大数据学习(5)MapReduce切片(Split)和分区(Partitioner)
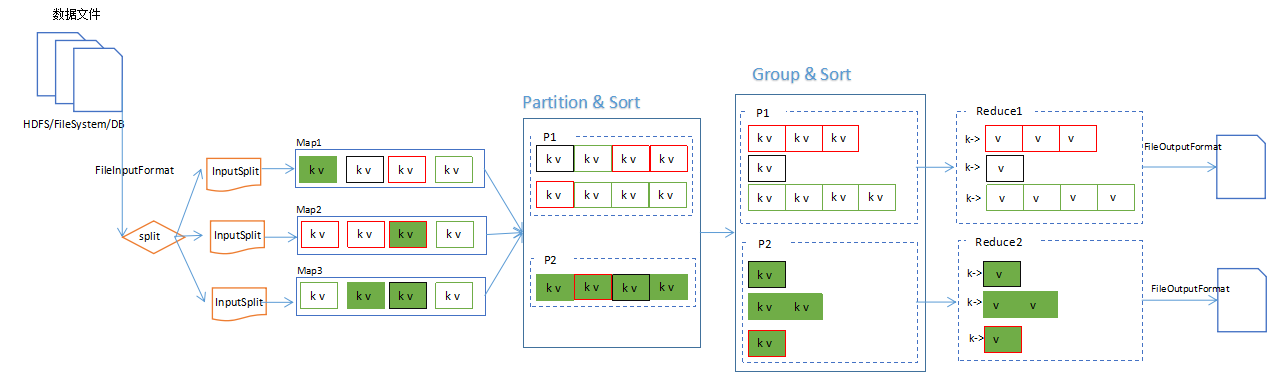
MapReduce中,分片、分区、排序和分组(Group)的关系图:
分片大小
对于HDFS中存储的一个文件,要进行Map处理前,需要将它切分成多个块,才能分配给不同的MapTask去执行。 分片的数量等于启动的MapTask的数量。默认情况下,分片的大小就是HDFS的blockSize。
Map阶段的对数据文件的切片,使用如下判断逻辑:
protected long computeSplitSize(long blockSize, long minSize, long maxSize) { return Math.max(minSize, Math.min(maxSize, blockSize)); }
blockSize:默认大小是128M(dfs.blocksize)
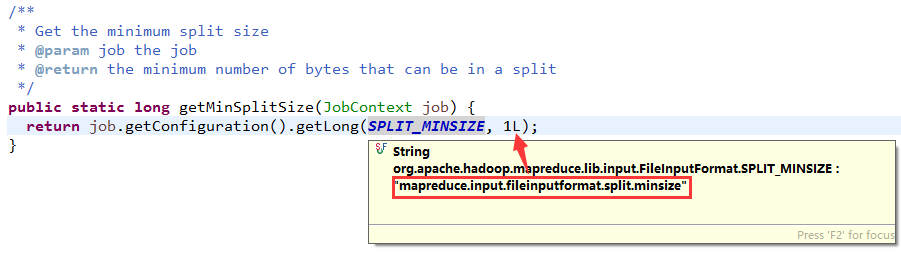
minSize:默认是1byte(mapreduce.input.fileinputformat.split.minsize):
maxSize:默认值是Long.MaxValue(mapreduce.input.fileinputformat.split.minsize)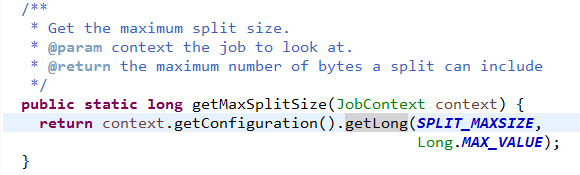
由此可以看出两个可以自定义的值(minSize和maxSize)与blockSize之间的关系如下:
当blockSize位于minSize和maxSize 之间时,认blockSize:

当maxSize小于blockSize时,认maxSize:
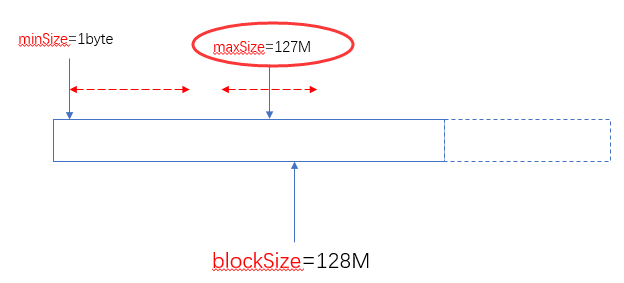
当minSize大于blockSize时,认minSize:
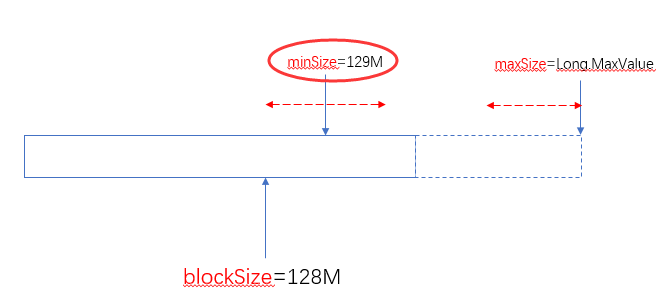
另外一个极端的情况,maxSize小于minSize时,认minsize,可以理解为minSize的优先级比maxSize大:
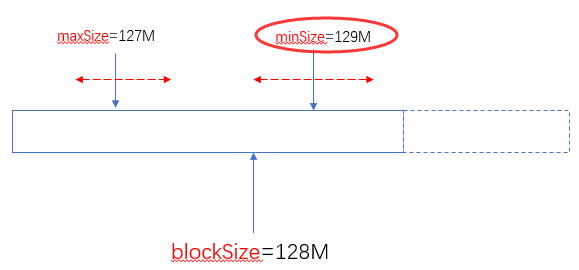
实际使用中,建议不要去修改maxSize,通过调整minSize(使他大于blockSize)就可以设定分片(Split)的大小了。
总之通过minSize和maxSize的来设置切片大小,使之在blockSize的上下自由调整。
什么时候需要调整分片的大小
首先要明白,HDFS的分块其实是指HDFS在存储文件时的一个参数。而这里分片的大小是为了业务逻辑用的。分片的大小直接影响到MapTask的数量,你可以根据实际的业务需求来调整分片的大小。
分区
在Reduce过程中,可以根据实际需求(比如按某个维度进行归档,类似于数据库的分组),把Map完的数据Reduce到不同的文件中。分区的设置需要与ReduceTaskNum配合使用。比如想要得到5个分区的数据结果。那么就得设置5个ReduceTask。
自定义Partitioner:
public class URLResponseTimePartitioner extends Partitioner<Text, LongWritable>{ @Override public int getPartition(Text key, LongWritable value, int numPartitions) { String accessPath = key.toString(); if(accessPath.endsWith(".do")) { return 0; } return 1; } }
然后可以在job中设置partitioner:
job.setPartitionerClass(URLResponseTimePartitioner.class); //URLResponseTimePartitioner returns 1 or 0,so num of reduce task must be 2 job.setNumReduceTasks(2);
两个分区会产生两个最终结果文件:
[root@centos01 ~]# hadoop fs -ls /access/log/response-time 17/12/19 14:53:55 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Found 3 items -rw-r--r-- 2 root supergroup 0 2017-12-19 14:49 /access/log/response-time/_SUCCESS -rw-r--r-- 2 root supergroup 7769 2017-12-19 14:49 /access/log/response-time/part-r-00000 -rw-r--r-- 2 root supergroup 18183 2017-12-19 14:49 /access/log/response-time/part-r-00001
其中00000中存放着.do的统计结果,00001则存放其他访问路径的统计结果。
[root@centos01 ~]# hadoop fs -cat /access/log/response-time/part-r-00001 |more 17/12/19 14:55:41 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable //MyAdmin/scripts/setup.php 3857 //css/console.css 356 //css/result_html.css 628 //images/male.png 268 //js/tooltipster/css/plugins/tooltipster/sideTip/themes/tooltipster-sideTip-borderless.min.css 1806 //js/tooltipster/css/tooltipster.bundle.min.css 6495 //myadmin/scripts/setup.php 3857 //phpMyAdmin/scripts/setup.php 3857 //phpmyadmin/scripts/setup.php 3857 //pma/scripts/setup.php 3857 /404/search_children.js 3827 /Dashboard.action 3877 /Homepage.action 3877 /My97DatePicker/WdatePicker.js 9371 /My97DatePicker/calendar.js 22044 /My97DatePicker/lang/zh-cn.js 1089 /My97DatePicker/skin/WdatePicker.css 158 /My97DatePicker/skin/default/datepicker.css 3486 /My97DatePicker/skin/default/img.gif 475
排序
要想最终结果中按某个特性排序,则需要在Map阶段,通过Key的排序来实现。
例如,想让上述平均响应时间的统计结果按降序排列,实现如下:
关键就在于这个用于OUTKey的Bean。它实现了Comparable接口,所以输出的结果就是按compareTo的结果有序。
由于这个类会作为Key,所以它的equals方法很重要,会作为,需要按实际情况重写。这里重写的逻辑是url相等则表示是同一个Key。(虽然Key相同的情况其实没有,因为之前的responseTime统计结果已经把url做了group,但是这里还是要注意有这么个逻辑。)
排序并不是依赖于key的equals!
public class URLResponseTime implements WritableComparable<URLResponseTime>{ String url; long avgResponseTime; public void write(DataOutput out) throws IOException { out.writeUTF(url); out.writeLong(avgResponseTime); } public void readFields(DataInput in) throws IOException { this.url = in.readUTF(); this.avgResponseTime = in.readLong(); } public int compareTo(URLResponseTime urt) { return this.avgResponseTime > urt.avgResponseTime ? -1 : 1; } public String getUrl() { return url; } public void setUrl(String url) { this.url = url; } public long getAvgResponseTime() { return avgResponseTime; } public void setAvgResponseTime(long avgResponseTime) { this.avgResponseTime = avgResponseTime; } @Override public int hashCode() { final int prime = 31; int result = 1; result = prime * result + ((url == null) ? 0 : url.hashCode()); return result; } @Override public boolean equals(Object obj) { if (this == obj) return true; if (obj == null) return false; if (getClass() != obj.getClass()) return false; URLResponseTime other = (URLResponseTime) obj; if (url == null) { if (other.url != null) return false; } else if (!url.equals(other.url)) return false; return true; } @Override public String toString() { return url; }
}
然后就简单了,在Map和Reduce分别执行简单的写和读操作就行了,没有更多的处理,依赖于Hadoop MapReduce框架自身的特点就实现了排序:
public class URLResponseTimeSortMapper extends Mapper<LongWritable,Text,URLResponseTime,LongWritable>{ //make a member property to avoid new instance every time when map function invoked. URLResponseTime key = new URLResponseTime(); LongWritable value = new LongWritable(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] logs = line.split("\t"); String url = logs[0]; String responseTimeStr = logs[1]; long responseTime = Long.parseLong(responseTimeStr); this.key.setUrl(url); this.key.setAvgResponseTime(responseTime); this.value.set(responseTime); context.write(this.key,this.value); } }
public class URLResponseTimeSortReducer extends Reducer<URLResponseTime, LongWritable, URLResponseTime, LongWritable> { @Override protected void reduce(URLResponseTime key, Iterable<LongWritable> values, Context ctx) throws IOException, InterruptedException { ctx.write(key, values.iterator().next()); } }
参考:
Hadoop Wiki,HowManyMapsAndReduces :https://wiki.apache.org/hadoop/HowManyMapsAndReduces

 浙公网安备 33010602011771号
浙公网安备 33010602011771号