
python第七次作业
import numpy as np
x = np.random.randint(1, 100, 20) # 产生的20个一到一百的随机整数
y = np.zeros(20)
k = 3
print(x)
print(y)
def initcenter(x, k): # 初始化聚类中心数组
return x[0:k].reshape(k)
kc = initcenter(x, k)
print(kc)
def nearest(kc, i): # 定义函数求出kc与i之差最小的数的坐标
d = (abs(kc - i))
w = np.where(d == np.min(d))
return w[0][0]
# print(nearest(kc,66))
# for i in range(x.shape[0]):
# y[i] = nearest(kc,x[i])
# print(y)
def xclassify(x, y, kc): # 按距离最近的准则将它们分到距离它们最近的聚类中心(最相似)所对应的类
for i in range(x.shape[0]):
y[i] = nearest(kc, x[i])
return y
y = xclassify(x, y, kc)
print(x)
print(y)
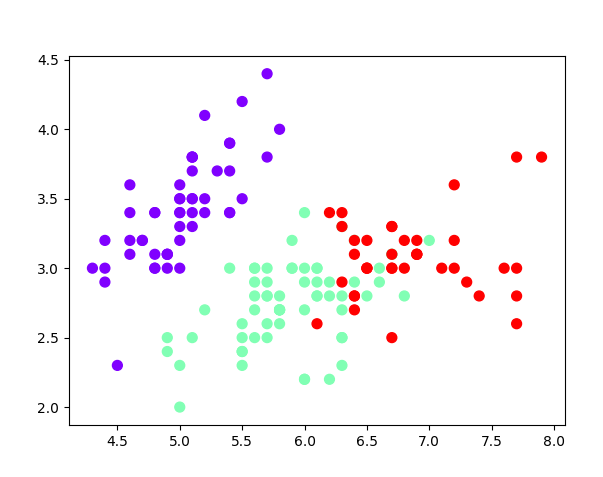
#.用sklearn.cluster.KMeans,鸢尾花完整数据做聚类并用散点图显示. import matplotlib.pyplot as plt import numpy as np from sklearn.datasets import load_iris iris=load_iris() print(iris) X=iris.data print(X) from sklearn.cluster import KMeans est = KMeans(n_clusters=3) est.fit(X) kc = est.cluster_centers_ y_kmeans = est.predict(X) #预测每个样本的聚类索引 print(y_kmeans,kc) print(kc.shape,y_kmeans.shape) plt.scatter(X[:,0],X[:,1],c=y_kmeans,s=50,cmap='rainbow') plt.show()
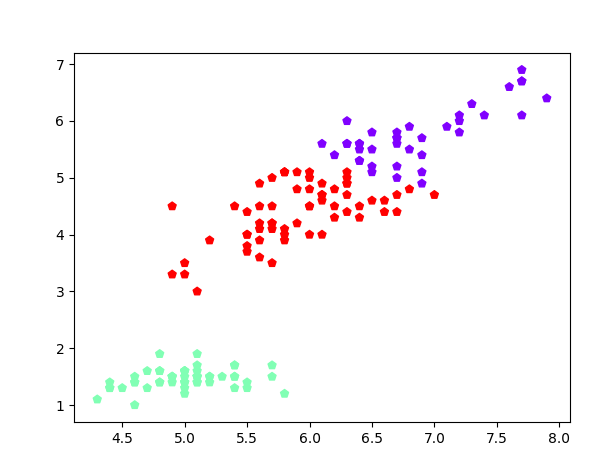
# 鸢尾花完整数据做聚类并用散点图显示. from sklearn.cluster import KMeans import numpy as np from sklearn.datasets import load_iris import matplotlib.pyplot as plt data = load_iris() iris = data.data petal_len = iris print(petal_len) k_means = KMeans(n_clusters=3) #三个聚类中心 result = k_means.fit(petal_len) #Kmeans自动分类 kc = result.cluster_centers_ #自动分类后的聚类中心 y_means = k_means.predict(petal_len) #预测Y值 plt.scatter(petal_len[:,0],petal_len[:,2],c=y_means, marker='p',cmap='rainbow') plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号