
python第五、六次作业
取系统时间
转换成‘2017年9月30日星期六10时28分56秒’格式字符串
’2018-10-25 22:00‘转换成一个日期时间变量
计算两者的间隔
二、问题:
- 数列:
- a = a1,a2,a3,·····,an
- b = b1,b2,b3,·····,bn
- 求:
- c = a12+b13,a22+b23,a32+b33,·····+an2+bn3
1.用列表+循环实现,并包装成函数
2.用numpy实现,并包装成函数
3.对比两种方法实现的效率,给定一个较大的参数n,用运行函数前后的timedelta表示。
三、尝试把a,b定义为三层嵌套列表和三维数组,求相对应元素的ai2+bi3
对比两种数据类型处理方法及效率的不同。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
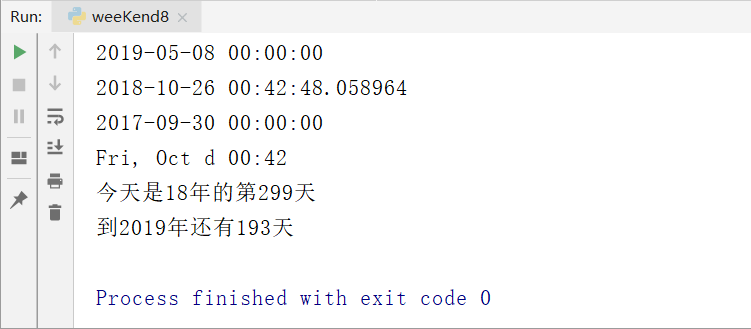
import datetimea=datetime.datetime(2019,5,8)print(a)b=datetime.datetime.now()print(b)from datetime import datetimec=datetime.strptime('2017年9月30日星期六10时28分26秒','%Y年%m月%d日星期六10时28分26秒')print(c)d=b.strftime('%a, %b d %H:%M')print(d)print('今天是{0:%y}年的第{0:%j}天'.format(datetime.now()))from datetime import timedeltaf=a-bprint('到2019年还有{}天'.format(f.days)) |
|
1
2
3
4
5
6
7
8
9
10
|
n=10def numSum(n): a=list(range(n)) b=list(range(0,n*5,5)) c=[] for i in range(len(a)): c.append(a[i]**2+b[i]**3) return (c)print(numSum(n)) |

|
1
2
3
4
5
6
7
|
import numpy as npdef npSum(n): a =np.arange(n) b= np.arange(0,n*5,5) c= a**2 + b**3 return (c)print(npSum(10)) |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
from datetime import datetimestart = datetime.now()from Numpy import numSumnumSum(10000)delta = datetime.now()-startprint(delta)from Numpy1 import npSumstart = datetime.now()npSum(10000)delta = datetime.now()-startprint(delta) |

|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
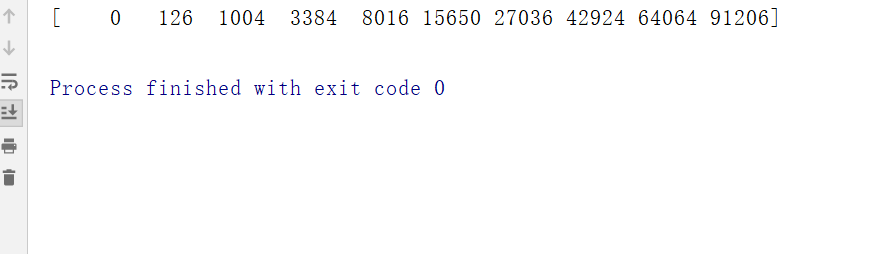
import numpyfrom datetime import datetimefrom Numpy import numSumfrom Numpy1 import npSumdef listSum(n): a = numpy.arange(n) b = numpy.arange(0,5*n,5) c = numpy.array([[a,b],[a**2,b**3]]) return (c)print(npSum(10))start = datetime.now()listSum(100000)time = datetime.now()-startprint(time) |

第六次作业
1. 安装scipy,numpy,sklearn包
2. 从sklearn包自带的数据集中读出鸢尾花数据集data
3.查看data类型,包含哪些数据
4.取出鸢尾花特征和鸢尾花类别数据,查看其形状及数据类型
5.取出所有花的花萼长度(cm)的数据
6.取出所有花的花瓣长度(cm)+花瓣宽度(cm)的数据
7.取出某朵花的四个特征及其类别。
8.将所有花的特征和类别分成三组,每组50个
9.生成新的数组,每个元素包含四个特征+类别
10.计算鸢尾花花瓣长度的最大值,平均值,中值,均方差。
11.显示鸢尾花某一特征的曲线图,散点图。
from sklearn.datasets import load_iris import numpy as np data=load_iris()#鸢尾花数据集data print(type(data))#查看数据集的类型 print(data.keys())#包含的数据
data_tgs=data ['target']##鸢尾花特征 data_tgsname=data['target_names']##鸢尾花的类别数据 data_ts=data_tgsname,data_tgs#鸢尾花特征和鸢尾花的类别数据 print(data_ts)#形状 print(type(data_ts))#数据类型
#取出所有花的花萼长度 data_sepal_l=np.array([x[0] for x in data['data']]) data_sepal_l
data_petal_l=[x[2] for x in data['data']]#所有花花瓣的长度 data_petal_w=[x[3] for x in data['data']]#所有花花瓣的宽度 data_petal_l_w=np.array([data_petal_l,data_petal_w])#所有花花瓣的长度和宽度 data_petal_l_w
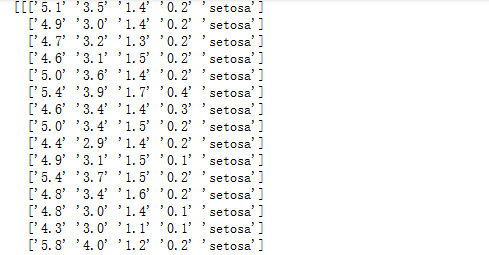
#7某朵花的四个特征和类别 data_flower=(data['data'][0],data['target_names'][0]) data_flower #8定义三个列表来存放不同类型花朵的类别 data_setosa=[] #存放类为0的花朵 data_versicolor=[] #存放类为1的花朵 data_virginica=[] #存放类为2的花朵 len(data['data']) for i in range(0,150): if data['target'][i]==0: #类别为setosa datas=data['data'][i].tolist() datas.append('setosa') print(data_setosa.append(datas)) elif data['target'][i]==1: #类别为versicolor datas=data['data'][i].tolist() datas.append('versicolor') data_versicolor.append(datas) else: datas=data['data'][i].tolist()#类别为virginica datas.append('virginica') data_virginica.append(datas) #9形成新的数组来存放三个类别的花朵 new_data=(np.array([data_setosa,data_versicolor,data_virginica])) print(new_data)






 浙公网安备 33010602011771号
浙公网安备 33010602011771号