Hadoop中MapReduce流程简单总结
题记:
本博文主要描述MapReduce的流程,以及可以自定义的一些部分
hadoop中reducemap的东西实在有点多,就想着自己简单的整理一下
MapTask
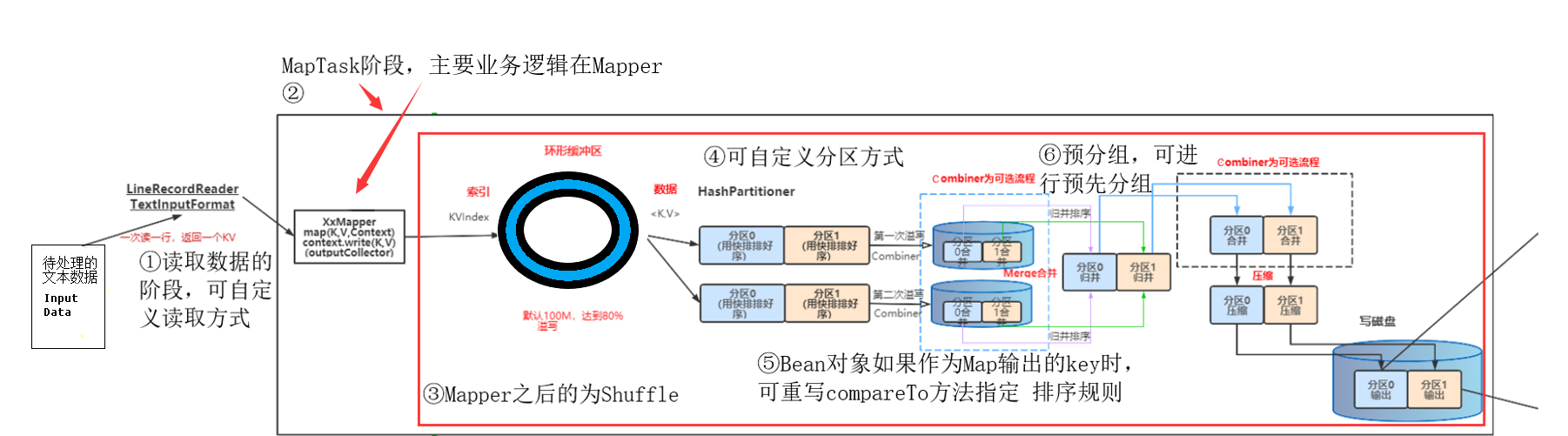
①读取数据:
这一阶段主要是读取待处理的文本数据,如Sprak、HDFS、Hive的数据,
默认是使用TextInputFormat,通过getSplits方法对输入目录中文件进行逻辑切片规划得到splits,
有多少个split就对应启动多少个MapTask。split与block的对应关系默认是一对一。
将输入文件切分为splits之后,由RecordReader对象(默认LineRecordReader)进行读取,以\n 作为分隔符,读取一行数据,返回<key,value>。
Key表示每行首字符偏移值,value表示这一行文本内容。
1 @InterfaceAudience.Public 2 @InterfaceStability.Stable 3 public class TextInputFormat extends FileInputFormat<LongWritable, Text> { 4 5 @Override 6 public RecordReader<LongWritable, Text> 7 createRecordReader(InputSplit split, 8 TaskAttemptContext context) { 9 String delimiter = context.getConfiguration().get( 10 "textinputformat.record.delimiter"); 11 byte[] recordDelimiterBytes = null; 12 if (null != delimiter) 13 recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8); 14 return new LineRecordReader(recordDelimiterBytes); 15 } 16 17 @Override 18 protected boolean isSplitable(JobContext context, Path file) { 19 final CompressionCodec codec = 20 new CompressionCodecFactory(context.getConfiguration()).getCodec(file); 21 if (null == codec) { 22 return true; 23 } 24 return codec instanceof SplittableCompressionCodec; 25 } 26 27 }
以上是TextInputFormat的源码,它的父类是FileInputFormat,可以看到其使用LineRecordReader进行读取每行数据。
public List<InputSplit> getSplits(JobContext job) throws IOException { ... while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) { int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining); splits.add(makeSplit(path, length-bytesRemaining, splitSize, blkLocations[blkIndex].getHosts(), blkLocations[blkIndex].getCachedHosts())); bytesRemaining -= splitSize; } ... } splitSize =128M SPLIT_SLOP=1.1
这是FileInputFormat对文件逻辑切块的方法部分,可以看出每次切块的大小是128M,这与HDFS的切块相对应,节约资源,
根据切片机制大于等于128M直接在原来的基础上切128M,大于128M的1.1倍的不大于128M两倍的会直接变成两份,不大于128M的1.1的算作一块,
假如有5个文件35M,126M,257M,129M,会切成35M,126M,128M+129M,129M,
35M+126M一个块,128M一个块,129M一个块,129M也是一个块,共4个块
值得一提的是,split为了不犯把一个单词切成两份的错误,切块时,即使数据到了128M,也继续读下去,只以换行符结束,如果没有换行符就一直读下去
我们可以自定义读取的方式,不适用默认的TextInputFormat读取
//自定义的Inputformat public class MyInputformat extends FileInputFormat<Text, BytesWritable> { //可设置文件不可切分 @Override protected boolean isSplitable(JobContext context, Path filename) { return false; } //获取自定义RecordReader对象用来读取数据 @Override public RecordReader<Text, BytesWritable> createRecordReader(InputSplit split, TaskAttemptContext context)throws IOException, InterruptedException { MyRecordReader recordReader = new MyRecordReader(); recordReader.initialize(split, context); return recordReader; } } //自定义的ecordReader public class MyRecordReader extends RecordReader<Text, BytesWritable> { private Configuration configuration; //切片 private FileSplit split; //是否读取到内容的标识符 private boolean isProgress = true; //输出的kv private BytesWritable value = new BytesWritable(); private Text k = new Text(); @Override public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException { //获取到文件切片以及配置文件对象 this.split = (FileSplit) split; configuration = context.getConfiguration(); } @Override public boolean nextKeyValue() throws IOException, InterruptedException { if (isProgress) { // 1 定义缓存区 byte[] contents = new byte[(int) split.getLength()]; //业务代码 ... //这一行不再读取 isProgress = false; return true; } return false; } ... }
//相应的Driver要修改 public class MyDriver{
...
// 如果不设置InputFormat,它默认用的是TextInputFormat.class
job.setInputFormatClass(MyTextInputFormat.class);
//虚拟存储切片最大值设置100m
MyTextInputFormat.setMaxInputSplitSize(job, 102400);
...
}
②Mapper阶段
用户自定义一个类继承Hadoop的Mapper类,重写map方法,其中map方法的逻辑就是用户希望mr程序map阶段如何处理的逻辑;
Mapper的输入数据是KV对的形式(类型可以自定义,但必须是Hadoop的序列化类型,实现Hadoop的序列化方法)
Map阶段的业务逻辑定义在map()方法中 Mapper的输出数据是KV对的形式(类型可以自定义,但必须是Hadoop的序列化类型,实现Hadoop的序列化方法)
注意:map()方法是对输入的一个KV对调用一次!!
简单案例:
public class MyMapper extends Mapper<LongWritable, Text, Text, NullWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { context.write(value,NullWritable.get()); } }
③Suffle阶段
mapper之后,reduce之前的阶段都是suffle,其目的是为了尽可能的使用节点的内存,尽可能地减少拉取数据的数据量,保证数据的完整性
suffle首先是把mapper过后的数据放入环形缓冲区,缓冲区的作用是批量收集map结果,减少磁盘IO的影响。
我们的key/value对以及Partition的结果都会被写入缓冲区。环形缓冲区的默认大小是100M,到达80%的时候溢写到磁盘,保证缓冲区可以边进边出,最后的数据不足80%也会全部溢写到磁盘
其中环形缓冲区的默认大小和溢写的百分比都可以修改配置文件mapred-default.xml自定义

环形缓冲区主要是对map()的key/value对以及Partition的结果,会按照key进行分区,默认的分区规则是key的hashcode%reducetask的数量,源码如下
1 package org.apache.hadoop.mapreduce.lib.partition; 2 3 import org.apache.hadoop.classification.InterfaceAudience; 4 import org.apache.hadoop.classification.InterfaceStability; 5 import org.apache.hadoop.mapreduce.Partitioner; 6 7 /** Partition keys by their {@link Object#hashCode()}. */ 8 @InterfaceAudience.Public 9 @InterfaceStability.Stable 10 public class HashPartitioner<K, V> extends Partitioner<K, V> { 11 12 /** Use {@link Object#hashCode()} to partition. */ 13 public int getPartition(K key, V value, 14 int numReduceTasks) { 15 return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; 16 } 17 18 }
我们也可自定义分区的方式
public class MyPartitioner extends Partitioner<Text,MyBean> { @Override public int getPartition(Text text, MyBean myBean, int numPartitions) { //不同的key,根据业务返回不同的 partition即可 if(xxx){ return 0; } return 1;
} }
//驱动类要设置分区类,以及可以按实际需求设置对应的reducetask的数量 public class MyDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { .... job.setPartitionerClass(MyPartitioner .class); job.setNumReduceTasks(5); .... } }
/**
reduceTask的数量默认为一,可以设置在Driver中
自定义分区器时最好保证分区数量与reduceTask数量保持一致;
如果分区数量不止1个,但是reduceTask数量1个,此时只会输出一个文件。
如果reduceTask数量大于分区数量,但是输出多个空文件
如果reduceTask数量小于分区数量,有可能会报错。
**/
Suffle对数据分区之后,就会对数据进行排序,默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。
MapTask和ReduceTask均会对数据按照key进行排序。该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。
我们也可以通过让bean对象作为Map输出的key时,实现WritableComparable接口并重写compareTo方法指定排序规则,来自定义排序规则
public class SortNumberBean implements WritableComparable<SortNumberBean> { @Override public int compareTo(SortNumberBean o) { return (this.number < o.number) ? -1 : ((this.number.longValue() == o.number.longValue()) ? 0 : 1); } @Override public void write(DataOutput out) throws IOException { out.writeLong(number); } @Override public void readFields(DataInput in) throws IOException {this.number = in.readLong(); } public SortNumberBean() { } public SortNumberBean(Long number) {this.number = number; }/** * 数字 */ @Override public String toString() { return id + "\t" + number; }
//省略getset... }
排序过后,我们可以做预分组操作Combiner
Combiner默认是不开启,开启需要在Driver中添加,如: job.setCombinerClass(MyCombiner.class);
Combiner组件的父类其实就是Reducer,只是Combiner和reducer的区别在于 Combiner是运行在Suffle的过程中的,它的作用是对每一个maptask的输出进行局部汇总,以减小网络传输量
Combiner必须在不能影响最后的业务逻辑的情况下使用,比如求平均数、排序之类的就不能使用
因为Combiner是一个承接mapper,启动reduce的阶段,
所以Combiner的入参必须是Mapper的出参,Combiner的出参必须是Reduce的入参
public class MyCombiner extends Reducer<Text,IntWritable,Text,IntWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //编写逻辑,通reduce差不多 context.write(key, total); } }
... //Driver类加上 job.setCombinerClass(MyCombiner.class);
ReduceTask
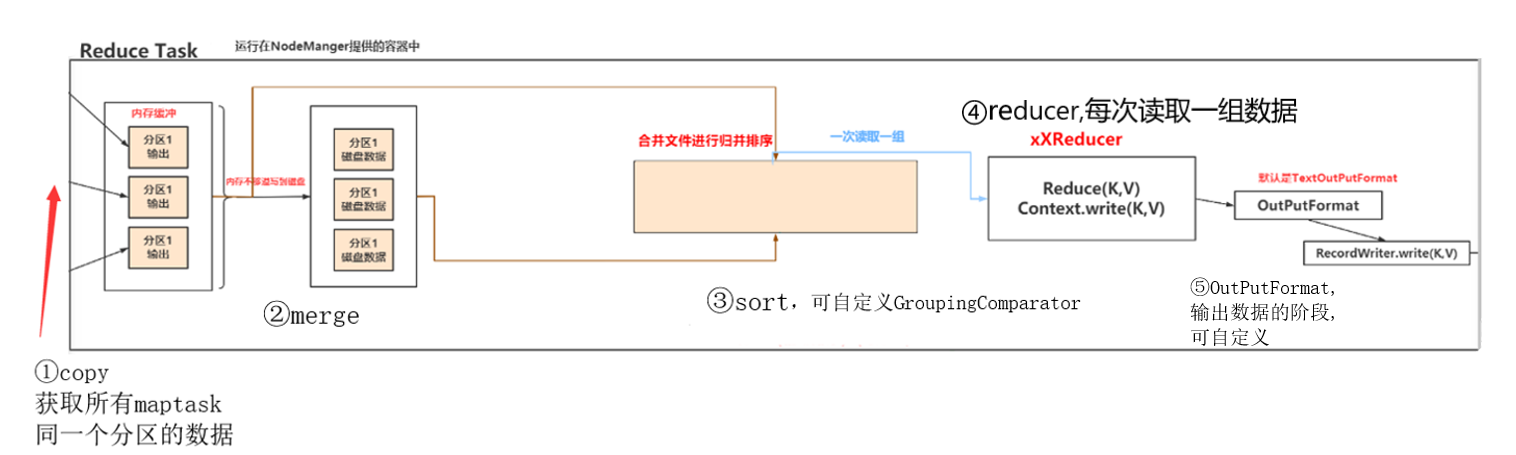
①一个reducetask开始,会简单的拉取每个maptask任务中属于自己处理的这一个分区的数据,reuducetask处理的是同一分区的数据
②之后reducetas会执行merge操作,把Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小相对于map端的更为灵活。
merge 有三种形式:
内存到内存,默认情况下是不启用。
内存到磁盘,当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。
与map 端类似,这也是溢写的过程,这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。
这种 merge方式一直在运行,直到没有map端的数据时才结束
磁盘到磁盘,一般最后的时候,启动这种磁盘到磁盘的merge 方式生成终的文件。
③Sort就是把分散的数据合并成一个大的数据后,还会再对合并后的数据排序。
对排序后的键值对调用reduce方法,键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对,后把这些输出的键值对写入到HDFS文件中或磁盘上。
这里我们可以通过自定义GroupingComparato方法实现不根据键相等的来分组,调用一次reduce方法
GroupingComparato是reduce端的一个功能组,通常用来做一些topn的功能
//自定义Mapper public class MyMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable> { MyBean bean=new MyBean(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //把数据装进bean的代码省略。。 context.write(bean, NullWritable.get()); } } //自定义Reduce public class MyReducer extends Reduce<MyBean, NullWritable, MyBean, NullWritable> { @Override protected void reduce(MyBeankey, Iterable<NullWritable> values, Context context) throws IOException,InterruptedException{ context.write(key, NullWritable.get()); } } //自定义bean public class MyBean implements WritableComparable<MyBean> { private String id; private Integer number; //重写排序方法 @Override public int compareTo(OrderBean o) { //比较id的大小顺序 int i = this.id.compareTo(o.id); if (i == 0) { //如果id相同,则比较number,number大的排在前面 i = -this.number.compareTo(o.number); } return i; } //省略读写序列化和getset等代码 } /**自定义GroupConparator方法,实现不根据key分组,这里我们的key是MyBean对象,如果按照key分组,我们没有重写Mybean的equals(),那么就是调用bean的内存地址比较,而我们想实现按照Mybean的id属性大小排序可以这样**/ public class MyGroupingComparator extendsWritableComparator { public MyGroupingComparator () { super(Mybean.class, true); } @Override public int compare(WritableComparable a, WritableComparable b) { Mybean mybean1= (Mybean) a; Mybean mybean2= (Mybean) b; return mybean1.getOrderId().compareTo(mybean2.getOrderId()); } } //最后,要在Driver上加上 job.setGroupingComparatorClass(MyGroupingComparator .class);
④reducer阶段
我们通过自定义一个Reducer类来继承Hadoop的Reducer类,在reduce()方法中编写我们的逻辑代码
Reducer的输入数据类型对应Mapper的输出数据类型(KV对)
不同于Mapper的map()方法是对输入的一个KV对调用一次, Reducer的reduce()方法是对相同K的一组KV对调用执行一次,就是上面sort分组后的数据,键相同的数据调用一次reduce()
⑤OutPutFormat阶段
这一阶段主要是把reducer阶段输出的键值对写入到HDFS文件中
默认是使用TextOutputFormat,TextOutputFormat把每条记录写为文本行,LineRecordWriter对象写出到磁盘上或hdfs中。
我们也可以自定义自己的outputFomat文件,实现自己想要的效果
1 //注意输入参数要跟reuduce()的输出参数对应 2 public class MyOutputFormat extends FileOutputFormat<Text, NullWritable> { 3 @Override 4 public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext context)throws IOException, InterruptedException { 5 //获取文件系统对象 6 final FileSystem fs = FileSystem.get(context.getConfiguration()); 7 //指定输出数据的文件 8 final Path aPath = new Path("c:/a"); 9 final Path bPath = new Path("c:/b"); 10 final Path cPath = new Path("c:/c"); 11 //获取输出流 12 final FSDataOutputStream aOut = fs.create(aPath); 13 final FSDataOutputStream bOut = fs.create(bPath); 14 final FSDataOutputStream cOut = fs.create(cPath); 15 return new MyWriter(aOut, bOut, cOut); 16 } 17 } 18 public class MyWriter extends RecordWriter<Text, NullWritable> { 19 private FSDataOutputStream aOut; 20 private FSDataOutputStream bOut; 21 private FSDataOutputStream cOut; 22 public CustomWriter(FSDataOutputStream aOut,FSDataOutputStream bOut,FSDataOutputStream cOut){ 23 this.aOut=aOut; 24 this.bOut=bOut; 25 this.cOut=cOut; 26 } 27 28 @Override 29 public void write(Text key, NullWritable value) throws IOException, InterruptedException { 30 31 32 // 不同的情况输出到不同文件的逻辑代码,这里泛指三种情况 33 if (key.toString().startsWith("a")) { 34 aOut.write(key.toString().getBytes()); 35 aOut.write("\r\n".getBytes()); 36 }else if (key.toString().startsWith("b")) { 37 bOut.write(key.toString().getBytes()); 38 bOut.write("\r\n".getBytes()); 39 }else { 40 cOut.write(key.toString().getBytes()); 41 cOut.write("\r\n".getBytes()); 42 } 43 44 } 45 46 @Override 47 public void close(TaskAttemptContext context) throws IOException, InterruptedException { 48 IOUtils.closeStream(aOut); 49 IOUtils.closeStream(bOut); 50 IOUtils.closeStream(cOut); 51 } 52 } 53 54 //Driver要添加参数 55 public class MyDriver { 56 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 57 ... 58 job.setOutputFormatClass(MyOutputFormat.class); 59 // 即使OutputFormatClass中设置了不同文件的输出目录,FileOutputFormat也要设置OutputPath,用来输出标志文件_SUCCESS 60 FileOutputFormat.setOutputPath(job, new Path("e:/click_log/output")); 61 ... 62 } 63
ReduceTask的数量还有几个需要注意的地方,我小小的记录一下:
如果分区数量不止1个,但是reduceTask数量1个,此时只会输出一个文件。
如果reduceTask数量大于分区数量,但是输出多个空文件
如果reduceTask数量小于分区数量,有可能会报错。
如果ReduceTask=0,表示没有Reduce阶段,输出文件数和MapTask数量保持一致;
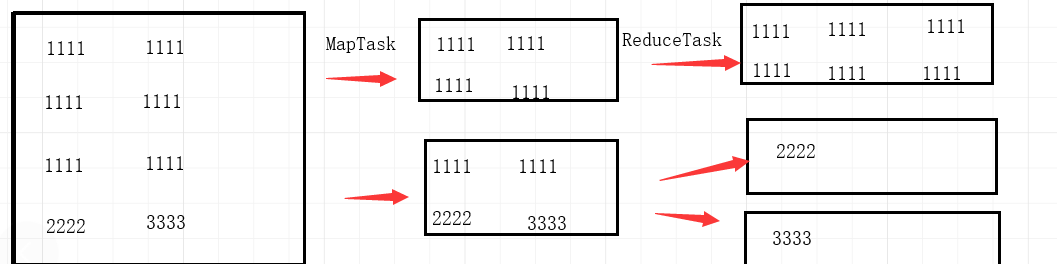
如果数据的key的分化严重不均,造成一部分数据很多,一部分数据很少的局面,就会造成数据倾斜,可能导致一个reducetask处理99%的数据的局面,如下图
结语:
这篇文章是我自己对于mapreduce的一点总结,刚开始学习确实感觉对我有点吃力,若有总结的有什么问题,请指出,立即改正。
