Apache Hadoop的重要组成部分
Hadoop=HDFS(分布式文件系统)+MapReduce(分布式计算框架)+Yarn(资源调度框架)+Common框架
1.Hadoop HDFS:(Hadoop Distribute File System) 一个高可靠、高吞吐量的分布式文件系统比如:100T数据存储,
比如:100T数据存储
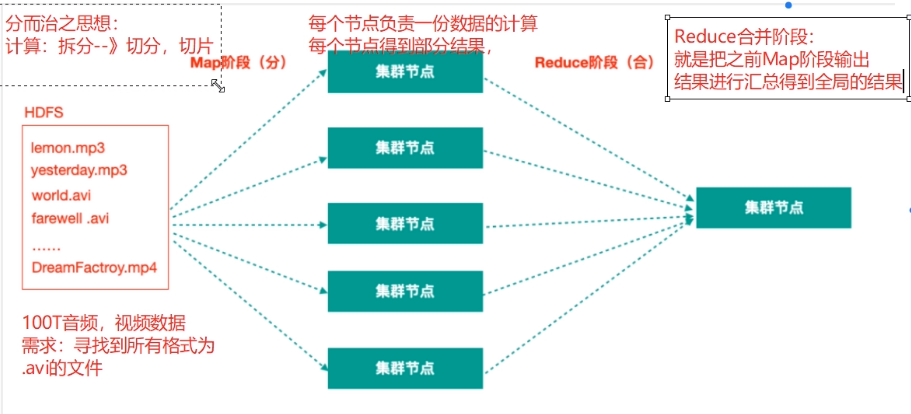
“分而治之”
分:拆分-》数据切割,100T数据拆分为10G一个数据块有一个电脑节点存储这个数据块。
数据切割、制作副本、分散储存
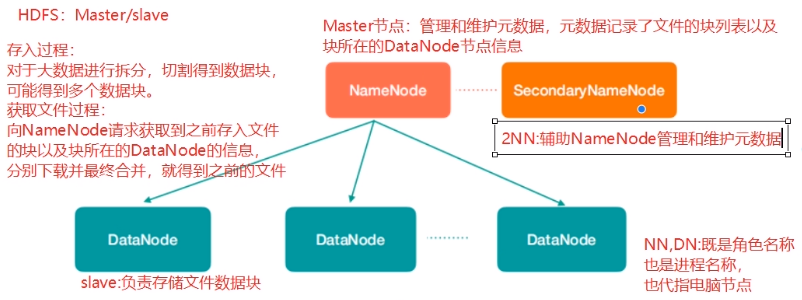
图中涉及到几个角色
NameNode(nn):存储文件的元数据,比如文件名、文件目录结构、文件属性(生产时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
SecondaryNameNode(2nn):辅助NameNode更好的工作,用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据快照
DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验
注意;NN,2NN,DN这些既是角色名称,进程名称,代指电脑节点名称!!
Hadoop Namenode节点只能格式化一次,多次格式会导致NameNode和DataNode版本号对不上,导致集群启动无法成功
