创新实训 (八) 大模型微调技术学习
1.为什么需要微调大模型?
output_dir = "./results"
training_args = TrainingArguments(
report_to="wandb",
output_dir=output_dir,#训练后输出目录
per_device_train_batch_size=4,#每个GPU的批处理数据量
gradient_accumulation_steps=4,#在执行反向传播/更新过程之前,要累积其梯度的更新步骤数
learning_rate=2e-4,#超参、初始学习率。太大模型不稳定,太小则模型不能收敛
logging_steps=10,#两个日志记录之间的更新步骤数
max_steps=100#要执行的训练步骤总数
)
max_seq_length = 512
#TrainingArguments 的参数详解:https://blog.csdn.net/qq_33293040/article/details/117376382
trainer = SFTTrainer(
model=base_model,
train_dataset=dataset,
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=max_seq_length,
tokenizer=tokenizer,
args=training_args,
)
大型预训练模型的训练成本极高,涉及庞大的计算资源和海量数据,如果对于不同特征的数据和任务都要重新进行大模型的训练,那么成本是非常高昂的。这也导致了研究成果难以被复现和验证。为了解决这个问题,Parameter-Efficient Fine-Tuning(参数有效微调)技术应运而生,旨在通过最小化微调参数和计算复杂度,来提高预训练模型在新任务上的性能,从而大大降低了计算和储存成本。这样一来,即使计算资源有限,也可以利用预训练模型的知识来迅速适应新任务,从而高效的迁移学习。大型预训练模型通常在广泛的数据集上进行训练,学习到了丰富的通用特征。通过微调,这些通用特征可以被迁移到新的任务上,从而在新任务上取得更好的性能,尤其是在新任务数据量有限的情况下。
Parameter-Efficient Fine-Tuning(参数有效微调) 通过在各种细化类型的任务中有效地调整大模型,提供了一种实用的解决方案。特别是,PEFT 是指调整预先训练的大型模型的参数,使其适应特定任务或领域,同时最小化引入的额外参数或所需计算资源的数量的过程。当处理具有高参数计数的大型语言模型时,这种方法非常重要,因为从头开始微调这些模型可能计算成本高昂且资源密集,在支持系统平台设计中提出了相当大的挑战。
2.PEFT 方法分类:
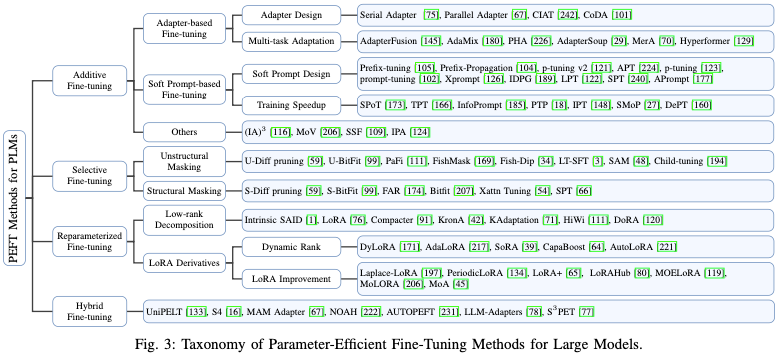
- Additive PEFT
保持预先训练的主干不变,并且只引入在模型架构中战略性定位的最小数量的可训练参数。在针对特定下游任务进行微调时,仅更新这些附加模块或参数的权重,这导致存储、内存和计算资源需求的显著减少。由于这些技术具有添加参数的特性,因此可以将其称为加性调整。常见的方法有:
加入配适器:在Transformer块中插入小型适配器层。
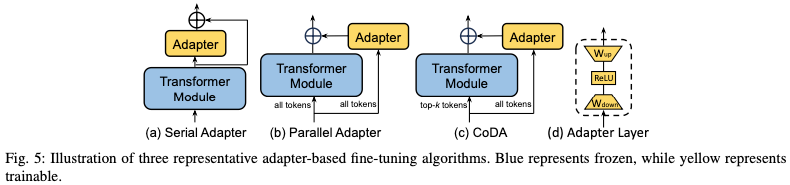
使用软提示:在模型的输入层引入可训练的参数来调整模型的行为,以便更好地适应特定任务。可以被看作是一种形式的提示或指令,它们不是固定的文本,而是可以随着训练过程进行调整的参数。可以在模型的嵌入层中添加额外的可训练向量。这些向量在训练过程中与输入数据一起被优化,从而影响模型的输出。
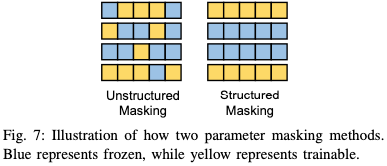
- Selective PEFT
Selective PEFT 不通过添加更多参数来增加模型复杂性的附加 PEFT,而是对现有参数的子集进行微调,以提高模型在下游任务中的性能。常用的方法有差分修剪,差分修剪是一种用于优化神经网络模型的技术,特别是在模型压缩和加速的背景下。这种技术旨在通过移除或修剪模型中不重要的权重来减少模型的复杂性和计算需求,同时尽量保持模型的性能。
- Reparameterized PEFT
重新参数化表示通过转换模型的参数将模型的体系结构从一个等效地转换到另一个,通过重新参数化模型的某些部分来减少微调过程中需要更新的参数数量,旨在提高微调的效率,同时保持或接近原始模型的性能。在传统的微调方法中,通常需要更新整个模型的所有参数,这在处理大型模型时可能会非常耗时和计算密集。Reparameterized PEFT 引入一种新的参数化方式来解决这个问题,使得在微调时只需要更新模型的一小部分参数。
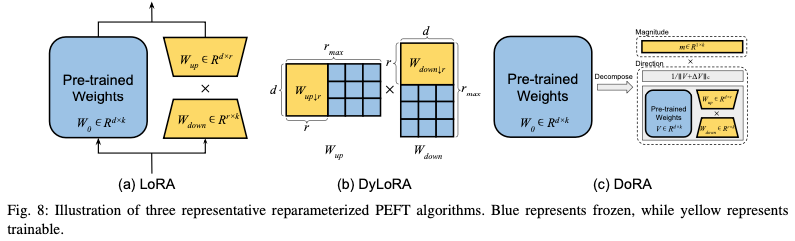
- Hybrid PEFT
各种 PEFT 的方法在效果上还是存在着较大的差距,。一种非常有效的且自然的方法是结合不同 PEFT 方法的优势,或通过分析这些方法之间的相似性来寻求建立统一的视角。PEFT 技术通过只更新模型的一小部分参数来解决这个问题,从而减少微调的成本。Hybrid PEFT 则更进一步,它结合了不同的 PEFT 技术,以期达到更好的效果。Hybrid PEFT 可以针对不同的模型部分和任务需求采用最合适的微调策略。例如,对于某些层可能使用适配器层,而对于其他层则可能使用低秩适应或提示调优。这种混合方法可以提供更大的灵活性,使得模型能够更有效地适应新任务,同时保持较低的计算成本。
论文:Prefix-Tuning: Optimizing Continuous Prompts for Generation
Prefix-tuning将一系列连续的特定于任务的向量添加到输入中,这些前缀向量并不能够映射到真正的实体 token,可以理解为“虚拟 token”,这些虚拟的 token 作为 Prefix。然后,在训练的时候只更新Prefix部分的参数,而 PLM 中的其他部分参数固定。
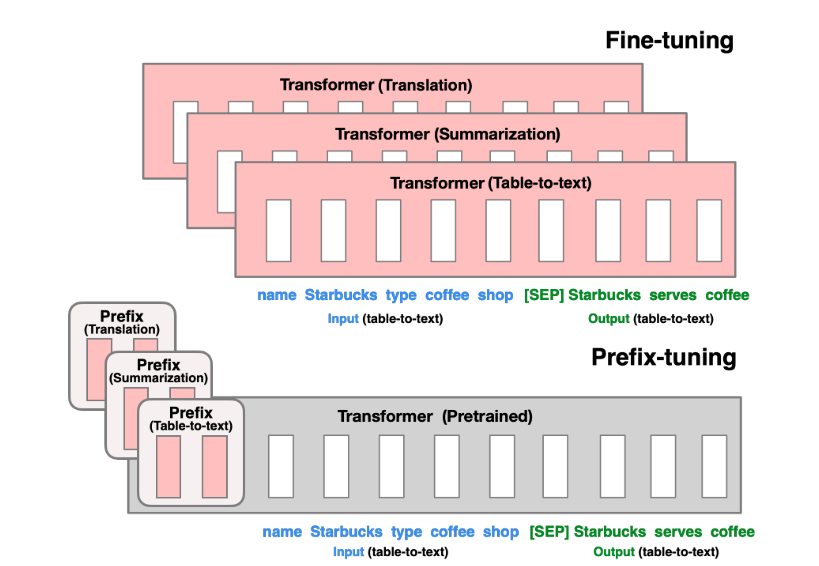
如上图,更新所有 Transformer 参数(红色方框内部分),只需为每个任务存储前缀向量,从而使前缀调整模块化并节省空间。
目前代码生成的 LLM 主要是基于以下两种模型:
-
自回归模型:自回归模型是一种序列生成模型,它在生成序列的每个时间步依赖于之前生成的所有时间步。在代码生成中,自回归模型通常用于逐词或逐符号地生成代码。例如,GPT(Generative Pre-trained Transformer)系列模型就是一种自回归模型,它们在自然语言处理任务中表现出色,会根据已生成的元素来预测下一个元素。
-
编码器-解码器模型:是一种常用于序列到序列(Seq2Seq)任务的架构。在代码生成中,编码器负责理解输入的上下文或需求描述,而解码器则负责生成相应的代码。这种模型通常用于需要将一种序列(如自然语言描述)转换为另一种序列(如代码)的任务。
这两种模型均常用于代码的生成,而我们选取的 CodeGeeX 是一个基于 Transformers 的大规模预训练编程语言模型。它是一个从左到右生成的自回归解码器,将代码或 token 作为输入,预测下一个标识符的概率分布。所以在阅读本文的过程中,对自回归模型的相关方法更加关注。
以文本摘要为例的自回归模型,输入是文本,输出是 token 序列。

如上图,\(x\) 是 source table(源数据),\(y\) 是 target utterance(目标语言)。在 Transformers 层有分布 \(P_{\phi}(y|x)\) 。令 \(z=[x:y]\) 是输入和输出 concatenation 的结果,\(h_1,h_2\dots h_n\) 为一系列激活向量,其中 \(h_i\) 是当前时间所有激活层的 concatenation 结果,其计算如下:
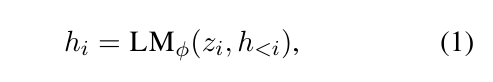
我们微调的目标是,最大化这个概率分布的值,即:
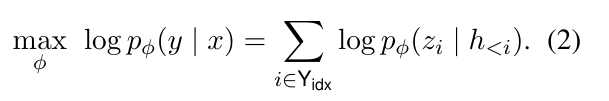
对于自回归模型,Prefix-Tuning 的方法是对 \(z\) 进行调整,令 \(z=[PREFIX;x;y]\),\(h_i\) 的计算为:
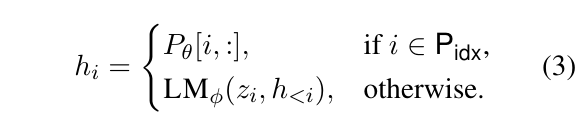
其中 \(P_{idx}\) 表示前缀prefix的下标。微调时,只对前缀参数进行梯度更新。
直接更新 \(P_{\theta}\) 会导致优化不稳定,降低性能。因此通过一个大型的前缀神经网络 $\rm MLP_{\theta} $ 组成的较小矩阵 $ P_{\theta}'$ 重新参数化矩阵 \(P_{\theta}[i,:]=\mathrm{MLP}_{\theta}(P_{\theta}'[i,:])\)。这样可训练参数就变为了 \(P_{\theta}'\) 和 \(\mathrm{MLP}_{\theta}\)。训练结束后只保存前缀参数 $ P_{\theta} $。
