创新实训(持续更新)
一 数据获取
为了提高在线评测系统的功能性,需要选择和集成一个强大的代码纠错大模型,用于自动分析和纠正用户提交的代码中的错误。
这里的大模型我们选择使用清华大学开源的 ChatGLM-CodeGeeX2。在该模型的基础上,选用程序设计试题的专门数据,进行Fine-turning的训练(即微调)。
为了令 CodeGeeX 在程序设计练习题的代码上生成能力更强,再将其集成到在线评测系统的过程对 CodeGeeX 模型进行了微调。微调模型的目标是使得模型对于程序设计练习题有着更强的解决能力,但不应降低其原有能力。所以我们需要从各大传统程序设计的在线评测平台中获得一些数据,将这些数据用于微调训练当中去。
- CodeGeeX 所需数据
首先,我们需要知道 CodeGeeX 所需的数据的格式。数据格式可以参考 HumanEval-X。
HumanEval-X 是一个用于评估代码生成模型多语言能力的基准。它由 820 个高质量的人工创建数据样本(每个样本都有测试用例)组成,语言包括 Python、C++、Java、JavaScript 和 Go,可用于代码生成和翻译等各种任务。CodeGeeX 的评测也是在 HumanEval-X 上完成的,所以可以参考 HumanEval-X 来了解对应数据的格式。下图为 HumanEval-X 的数据。
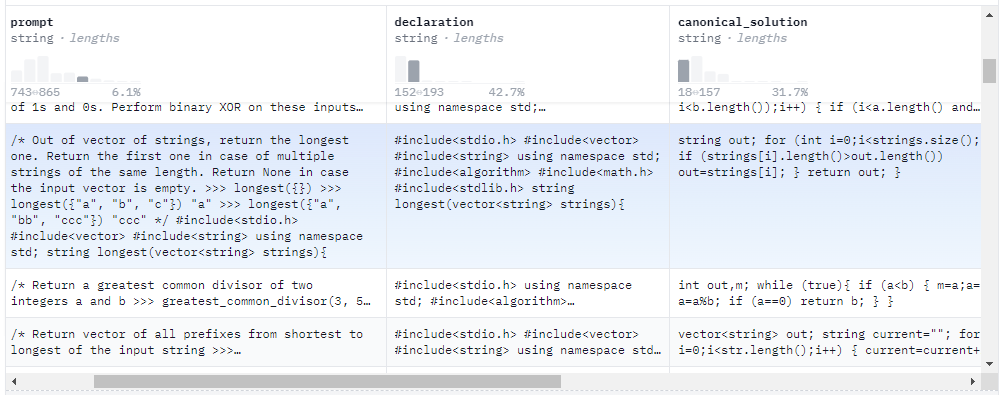
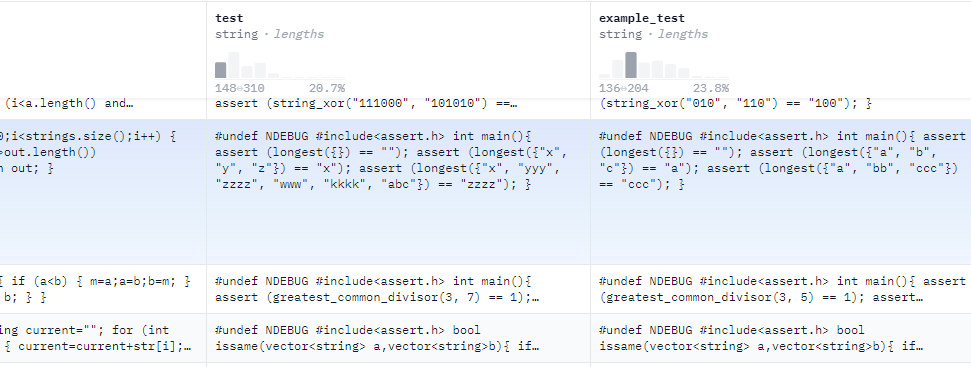
其中 Prompt 是对问题的描述,declaration 是代码的定义部分,canonical_solution 是代码的操作部分。后面的 test 和 example_test 是测试的代码和数据。
所以,想要对 CodeGeeX 进行微调和训练,就需要题目的描述和正确的代码。
- 数据获取
目前国内使用比较多程序设计练习平台是 PTA ,但是 PTA 的代码并不公开,所以我们转而选取了 LOJ。
LOJ 页面:
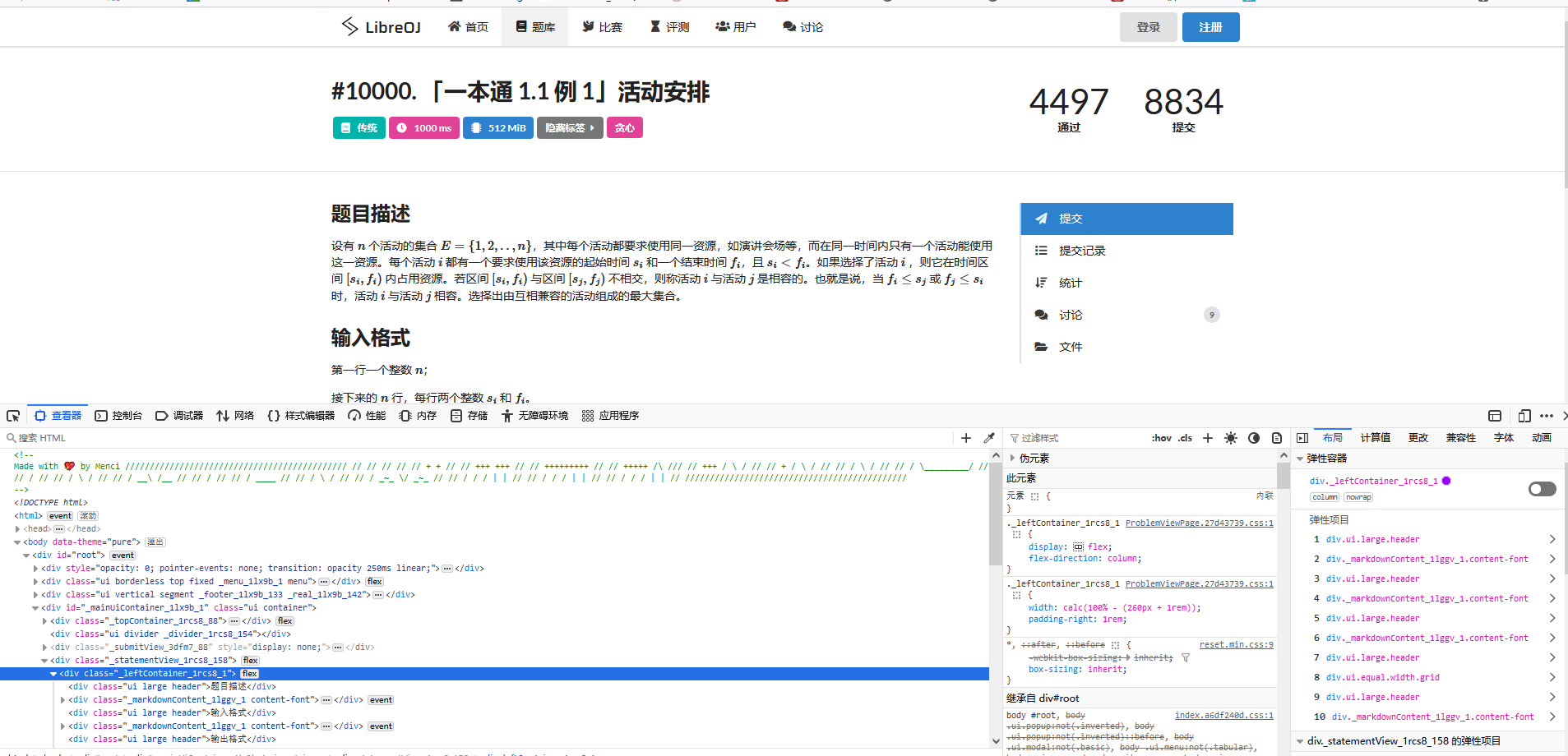
首先,我们需要获取题目信息。可以使用爬虫获取题目描述,并将数据保存到数据库中。
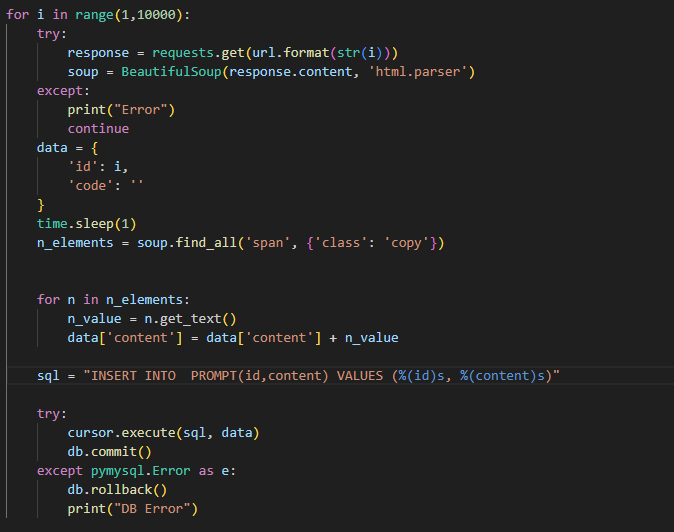
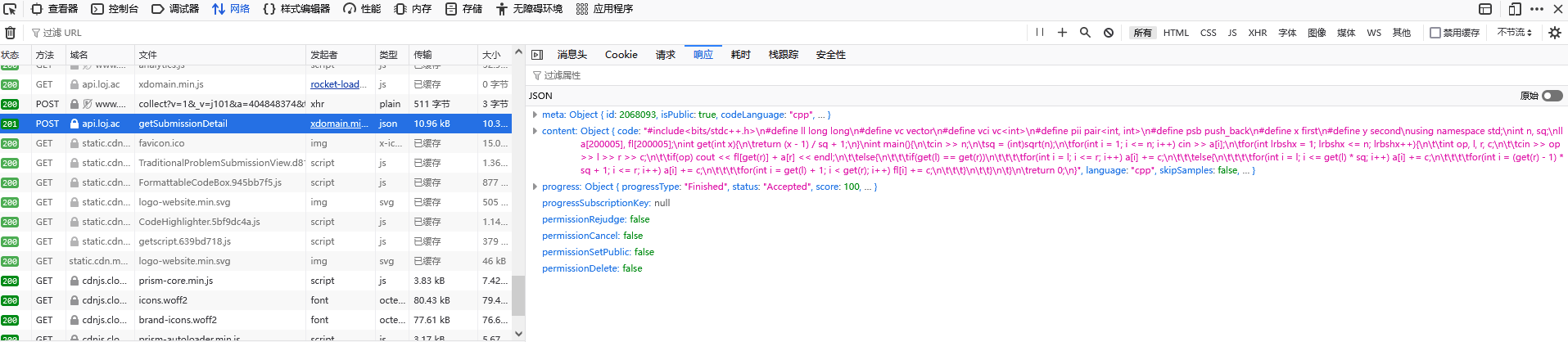
获取了题目信息后还需要获得正确的代码,而 LOJ 的代码都是公开的,未登录用户也可以进行访问,这非常方便。而 LOJ 有响应的 API 可以非常方便的获取代码。
API 如下,只要给出提交记录编号就可以获得包括代码在内的详细信息:
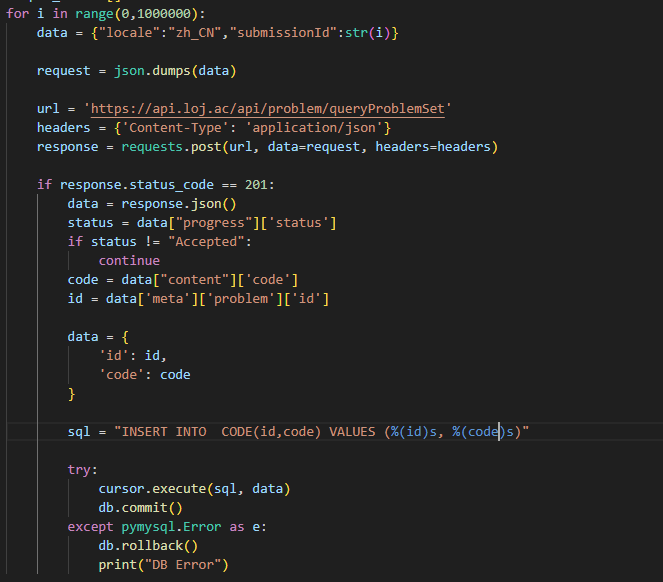
爬虫代码:
二 使用魔搭对 CodeGeeX 模型进行部署
在对模型进行部署时,可以使用魔搭默认的环境,CPU免费,GPU有使用的时间限制,需要关联阿里云的账号,因为 CodeGeeX 要用 GPU,所以先选择限制使用时长的 GPU。
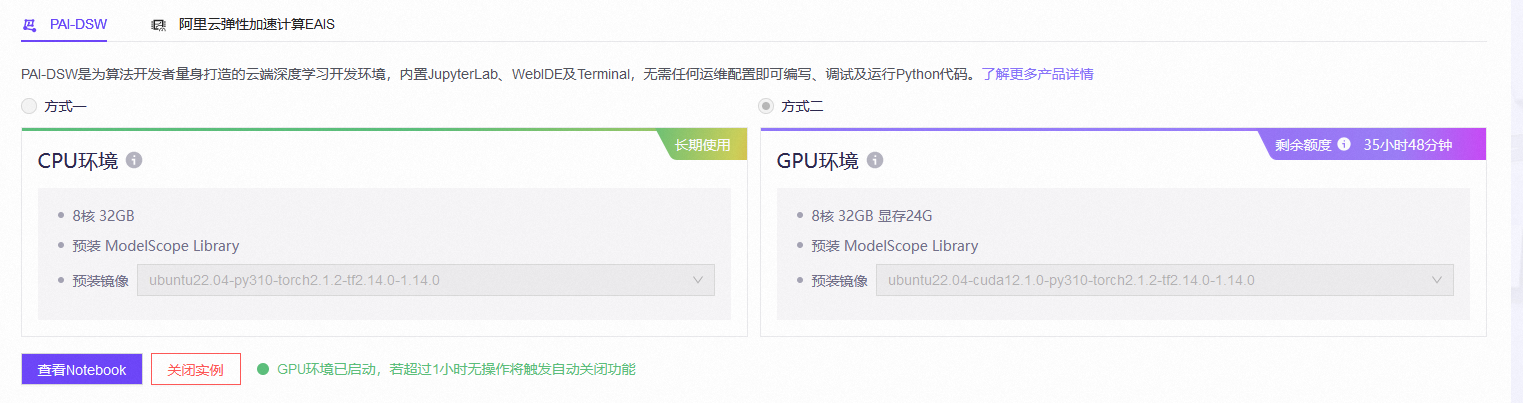
在相应的模型库中选择:CodeFuse-CodeGeeX2-6B
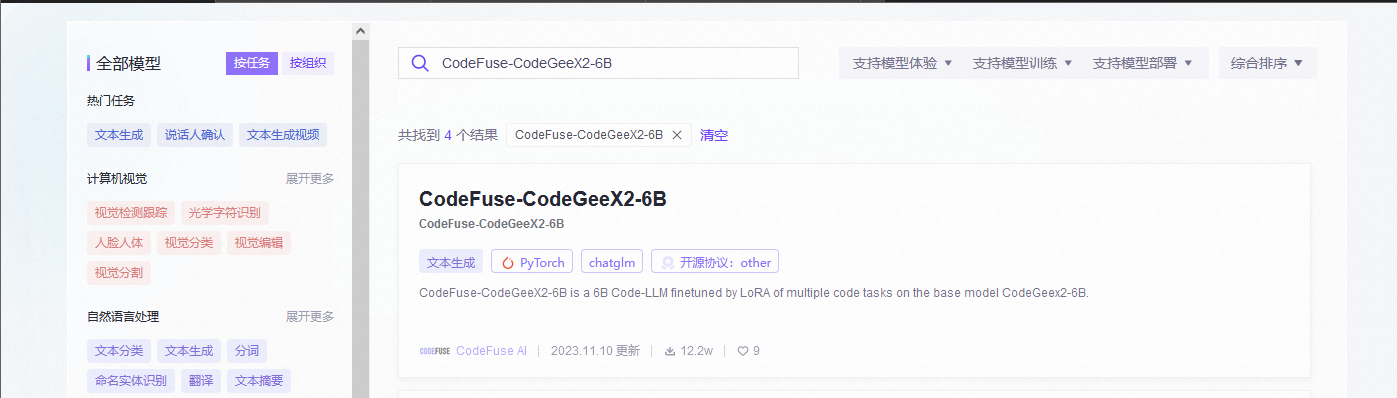
使用教程中对应的 git clone https://www.modelscope.cn/codefuse-ai/CodeFuse-CodeGeeX2-6B.git 命令,从对应的 Git 仓库克隆 CodeGeeX 的代码。

但是如果按照原来教程中的步骤,使用 pip install -r requirements.txt 安装项目所需的所有依赖包时会出现问题,查看 requirements.txt 后发现是版本不兼容导致的。
解决方案是删去 requirements.txt 中的 deepspeed 一行,DeepSpeed 是一个由微软开发的深度学习优化库,它旨在提高大型模型训练的效率,通过优化内存使用和分布式训练来实现。
尝试了一下方法后,发现可以使用 pip install deepspeed -U 来安装依赖。


将所有依赖都安装的时间较长,需要进行一段时间的等待。且在安装的最后,仍然会出现一段报错信息,但是模型已经可以正常运行了。
可以通过修改下面代码中的 text,来实现代码的生成。如命令模型生成求最大子段和的代码:
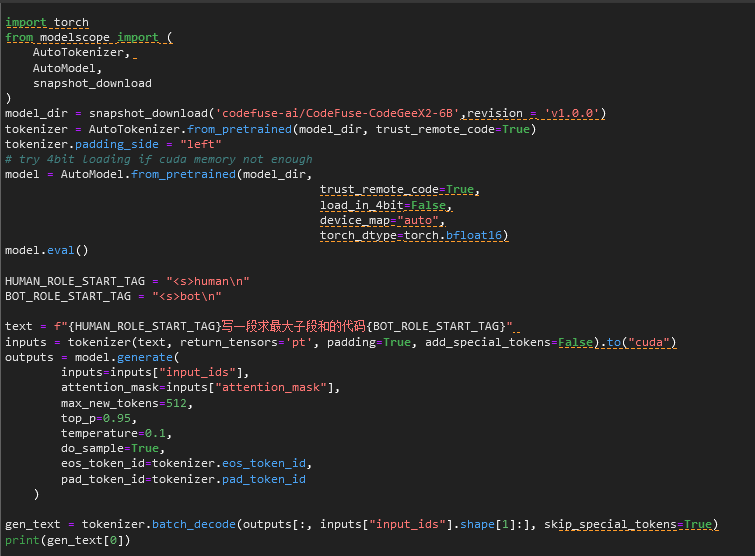
模型给出的结果包括代码和一些测试用例:

代码:
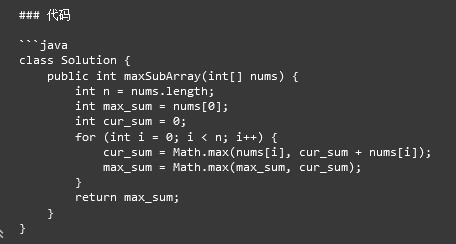
再一次打开模型,进行运行时,出现了一个错误:
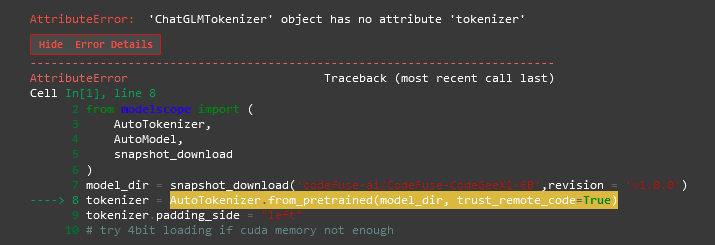
经过查阅资料,可以通过调整transformers版本解决:pip install transformers==4.33.2。
三 大模型微调学习
1.为什么需要微调大模型?
大型预训练模型的训练成本极高,涉及庞大的计算资源和海量数据,如果对于不同特征的数据和任务都要重新进行大模型的训练,那么成本是非常高昂的。这也导致了研究成果难以被复现和验证。为了解决这个问题,Parameter-Efficient Fine-Tuning(参数有效微调)技术应运而生,旨在通过最小化微调参数和计算复杂度,来提高预训练模型在新任务上的性能,从而大大降低了计算和储存成本。这样一来,即使计算资源有限,也可以利用预训练模型的知识来迅速适应新任务,从而高效的迁移学习。大型预训练模型通常在广泛的数据集上进行训练,学习到了丰富的通用特征。通过微调,这些通用特征可以被迁移到新的任务上,从而在新任务上取得更好的性能,尤其是在新任务数据量有限的情况下。
Parameter-Efficient Fine-Tuning(参数有效微调)通过在各种细化类型的任务中有效地调整大模型,提供了一种实用的解决方案。特别是,PEFT 是指调整预先训练的大型模型的参数,使其适应特定任务或领域,同时最小化引入的额外参数或所需计算资源的数量的过程。当处理具有高参数计数的大型语言模型时,这种方法非常重要,因为从头开始微调这些模型可能计算成本高昂且资源密集,在支持系统平台设计中提出了相当大的挑战。
2.PEFT 方法分类:
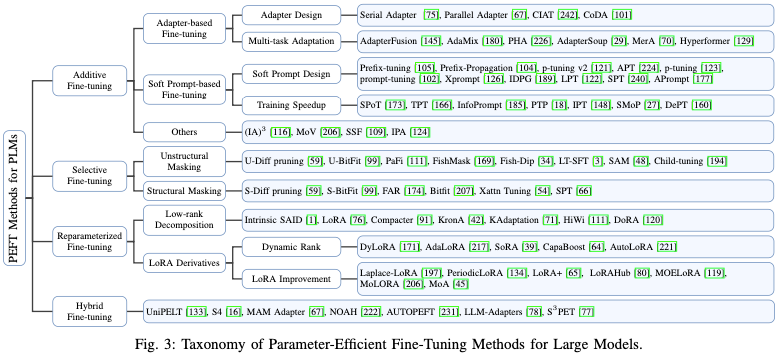
- Additive PEFT
保持预先训练的主干不变,并且只引入在模型架构中战略性定位的最小数量的可训练参数。在针对特定下游任务进行微调时,仅更新这些附加模块或参数的权重,这导致存储、内存和计算资源需求的显著减少。由于这些技术具有添加参数的特性,因此可以将其称为加性调整。常见的方法有:
加入配适器:在Transformer块中插入小型适配器层。
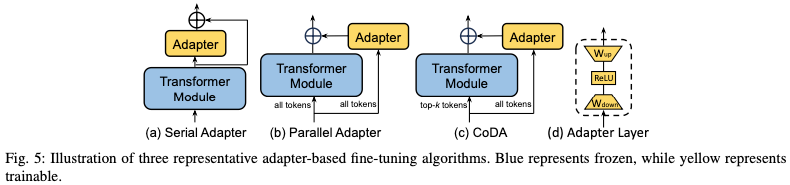
使用软提示:在模型的输入层引入可训练的参数来调整模型的行为,以便更好地适应特定任务。可以被看作是一种形式的提示或指令,它们不是固定的文本,而是可以随着训练过程进行调整的参数。可以在模型的嵌入层中添加额外的可训练向量。这些向量在训练过程中与输入数据一起被优化,从而影响模型的输出。
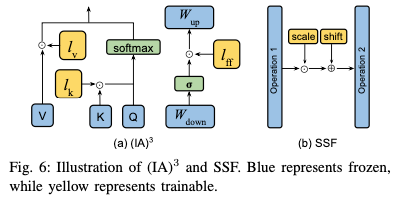
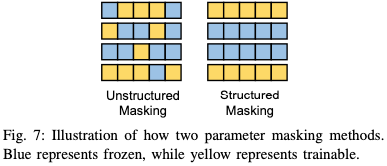
- Selective PEFT
Selective PEFT 不通过添加更多参数来增加模型复杂性的附加 PEFT,而是对现有参数的子集进行微调,以提高模型在下游任务中的性能。常用的方法有差分修剪,差分修剪是一种用于优化神经网络模型的技术,特别是在模型压缩和加速的背景下。这种技术旨在通过移除或修剪模型中不重要的权重来减少模型的复杂性和计算需求,同时尽量保持模型的性能。
- Reparameterized PEFT
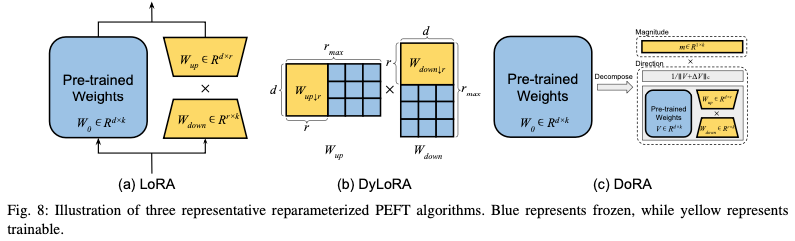
重新参数化表示通过转换模型的参数将模型的体系结构从一个等效地转换到另一个,通过重新参数化模型的某些部分来减少微调过程中需要更新的参数数量,旨在提高微调的效率,同时保持或接近原始模型的性能。在传统的微调方法中,通常需要更新整个模型的所有参数,这在处理大型模型时可能会非常耗时和计算密集。Reparameterized PEFT 引入一种新的参数化方式来解决这个问题,使得在微调时只需要更新模型的一小部分参数。
- Hybrid PEFT
各种 PEFT 的方法在效果上还是存在着较大的差距,。一种非常有效的且自然的方法是结合不同 PEFT 方法的优势,或通过分析这些方法之间的相似性来寻求建立统一的视角。PEFT 技术通过只更新模型的一小部分参数来解决这个问题,从而减少微调的成本。Hybrid PEFT 则更进一步,它结合了不同的 PEFT 技术,以期达到更好的效果。Hybrid PEFT 可以针对不同的模型部分和任务需求采用最合适的微调策略。例如,对于某些层可能使用适配器层,而对于其他层则可能使用低秩适应或提示调优。这种混合方法可以提供更大的灵活性,使得模型能够更有效地适应新任务,同时保持较低的计算成本。
四 前端基础部分
在线评测系统的前后端都是使用 PHP 进行开发的。PHP是一种广泛用于Web开发的服务器端脚本语言,有以下特点:
- 开源和跨平台:PHP是一种开源语言,可以在各种操作系统上运行,如Windows、Linux和macOS。这使得PHP非常灵活和可访问。
- 易学易用:与其他编程语言相比,PHP的语法相对简单,学习曲线较平缓。这使得PHP对初学者很友好。
- 广泛应用:PHP主要用于Web开发,可以构建动态网站和Web应用程序。许多著名的内容管理系统(如WordPress、Drupal和Joomla)都是基于PHP开发的。
- 强大的生态系统:PHP拥有庞大的开发者社区和丰富的第三方库,使得开发人员可以快速开发复杂的Web应用程序。
- 与数据库集成:PHP可以轻松地与各种数据库(如MySQL、PostgreSQL、Oracle等)进行交互,支持各种数据库操作。
- 灵活性:PHP可以嵌入到HTML中,也可以单独使用。这使得它非常灵活,可以满足各种Web开发需求。
- 性能优化:近年来,PHP也在不断优化性能,通过引入新版本和各种加速器,使得PHP的性能不断提升。
前后端文件目录:
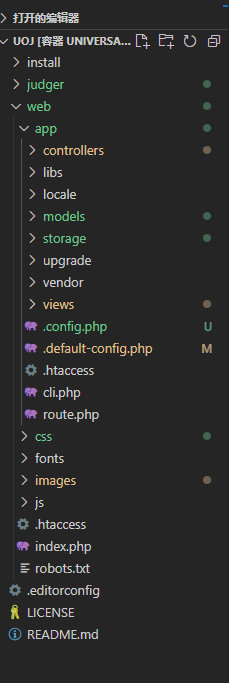
- controllers 是存放控制器文件的目录。
- libs 是一些前端库。
- locale 是存放页面上的文字在不同语言下的翻译的目录。
- models 是 OJ 运行所需的一些 PHP 类。
- storage 存储一些文件数据的目录,其中 storage/submissions 存放用户提交的测评请求中附带的文件的目录。
- views 存放视图文件的目录。
- route.php 是主站路由文件。
- vendor 是一些第三方 PHP 代码库。
入口脚本 index.php,当服务器收到一个请求时,会运行 index.php。index.php 会引入deeroj-lib.php、route.php等函数库和类库,然后根据路由去给请求中的网址匹配用于生成响应报文的 PHP 代码,根据路由的 action 部分确定控制器文件的路径。这相当于 C/C++/Java 中的 main 函数。
首先,需要实现一个 header 栏,用于各种功能的切换。
五 Prefix-tuning
论文:Prefix-Tuning: Optimizing Continuous Prompts for Generation
Prefix-tuning将一系列连续的特定于任务的向量添加到输入中,这些前缀向量并不能够映射到真正的实体 token,可以理解为“虚拟 token”,这些虚拟的 token 作为 Prefix。然后,在训练的时候只更新Prefix部分的参数,而 PLM 中的其他部分参数固定。
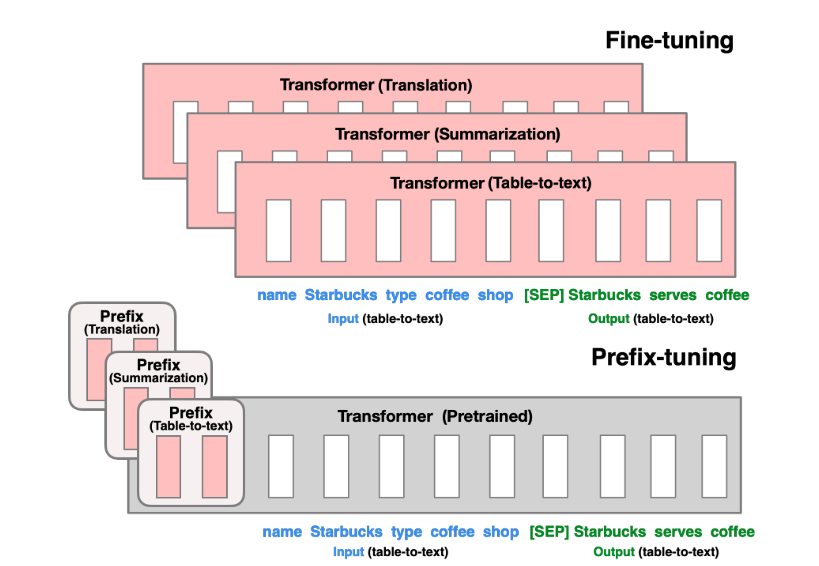
如上图,更新所有 Transformer 参数(红色方框内部分),只需为每个任务存储前缀向量,从而使前缀调整模块化并节省空间。
目前代码生成的 LLM 主要是基于以下两种模型:
-
自回归模型:自回归模型是一种序列生成模型,它在生成序列的每个时间步依赖于之前生成的所有时间步。在代码生成中,自回归模型通常用于逐词或逐符号地生成代码。例如,GPT(Generative Pre-trained Transformer)系列模型就是一种自回归模型,它们在自然语言处理任务中表现出色,会根据已生成的元素来预测下一个元素。
-
编码器-解码器模型:是一种常用于序列到序列(Seq2Seq)任务的架构。在代码生成中,编码器负责理解输入的上下文或需求描述,而解码器则负责生成相应的代码。这种模型通常用于需要将一种序列(如自然语言描述)转换为另一种序列(如代码)的任务。
这两种模型均常用于代码的生成,而我们选取的 CodeGeeX 是一个基于 Transformers 的大规模预训练编程语言模型。它是一个从左到右生成的自回归解码器,将代码或 token 作为输入,预测下一个标识符的概率分布。所以在阅读本文的过程中,对自回归模型的相关方法更加关注。
以文本摘要为例的自回归模型,输入是文本,输出是 token 序列。

如上图,\(x\) 是 source table(源数据),\(y\) 是 target utterance(目标语言)。在 Transformers 层有分布 \(P_{\phi}(y|x)\) 。令 \(z=[x:y]\) 是输入和输出 concatenation 的结果,\(h_1,h_2\dots h_n\) 为一系列激活向量,其中 \(h_i\) 是当前时间所有激活层的 concatenation 结果,其计算如下:
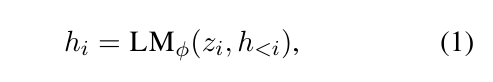
我们微调的目标是,最大化这个概率分布的值,即:
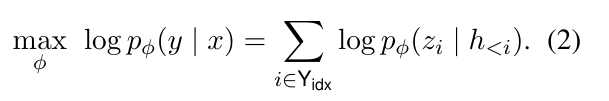
对于自回归模型,Prefix-Tuning 的方法是对 \(z\) 进行调整,令 \(z=[PREFIX;x;y]\),\(h_i\) 的计算为:
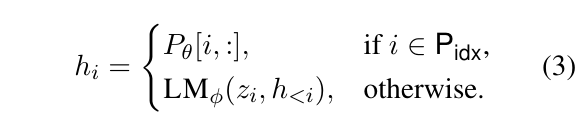
其中 \(P_{idx}\) 表示前缀prefix的下标。微调时,只对前缀参数进行梯度更新。
直接更新 \(P_{\theta}\) 会导致优化不稳定,降低性能。因此通过一个大型的前缀神经网络 $\rm MLP_{\theta} $ 组成的较小矩阵 $ P_{\theta}'$ 重新参数化矩阵 \(P_{\theta}[i,:]=\mathrm{MLP}_{\theta}(P_{\theta}'[i,:])\)。这样可训练参数就变为了 \(P_{\theta}'\) 和 \(\mathrm{MLP}_{\theta}\)。训练结束后只保存前缀参数 $ P_{\theta} $。
六 CEISEE
在指导老师鹿旭东的指导下,我们将现有的工作进行总结,形成了一篇简短的论文,目前该文章已投稿至 CEISEE 2024。

An Online Judgement System Based on Code-Generating Large Mode
Abstract: For computer science majors in higher education institutions, programming courses are one of the most important professional foundation courses. Proficiency in independent programming skills is of great help to the study of subsequent courses and the personal development of students. In the teaching process of programming courses, online judgement systems are often used to improve students' programming level. Traditional online judgement systems lack guidance for students, and it is often difficult for inexperienced students to find and correct errors in their codes by themselves. In this article, we propose an online judgement system that integrates a large model of error correction to help students find errors and improve their programming skills.
Key words:Online Judgement System;Code-Generating Large Mode; AI assistant。
Programming courses (C++ programming, Python programming, Java programming, etc.) are one of the most important professional foundation courses for computer science majors in colleges and universities. Meanwhile, computer technology is penetrating into various fields, and programming has become one of the skills that many college students must master. Many non-computer majors also offer programming courses. The main teaching goal of this course is to enable students to master a high-level programming language, and can independently and autonomously use high-level programming language to analyse and solve problems.
However, in the process of teaching, due to the large number of students, the short teaching time, and the fact that different students have different levels of acceptance and mastery of programming, it is often difficult for teachers to accurately know the programming ability of each student. Some students may have been exposed to programming before the course, and may feel that the content of the class is too simple and lose interest in the course. Some students who have not been exposed to programming beforehand may be less receptive to the programming language and may have difficulty in understanding the knowledge presented in the course. Therefore, programming courses often require students to go through a lot of practice, from the process of hands-on further deepen the understanding of the course knowledge, improve the hands-on ability, stimulate the interest in programming and motivation. The practice questions of programming are different from the questions of other courses, there is no standard answer, and it is difficult to judge the correctness of the static code only. Therefore, it is necessary to use an online judgement system to run the students' codes under actual data, and the system will give an judgement of the correctness, efficiency and quality of the students' codes.
And unlike other subjects, the errors that can occur in programming are not only varied but also sometimes very subtle, which makes it a high barrier to entry. With a large number of students and a wide variation in student code, teachers do not have the time and energy to be able to help every student with code error correction. Students who have not been in contact with programming often lack effective code debugging tools due to the lack of basic experience in programming, and often spend a lot of time and energy on code error checking and debugging, which is not conducive to the learning of the course and the consolidation of knowledge. The process of error checking also lacks effective reference, which is not conducive to the development of correct and good coding habits.
In order to solve this problem, this paper proposes an online judgement system with an integrated error-correcting large model. On the basis of providing the functions of traditional online judgement system such as problemset, judgement and examination, it adds the large model technology that can perform code error correction. It can help students to perform code error correction, save students' time in code error checking and debugging, help students develop correct and good coding habits, and reap better teaching results.
1 Status of the online judgement system
Programming course is one of the most important professional foundation courses for computer science majors in many colleges and universities. And as computer technology is gradually penetrating into various fields, many engineering majors also offer programming courses. Programming has become one of the necessary skills for college students in the new era. The online judgement system is an important teaching tool and platform for programming courses.
Online judgement systems, abbreviated as OJ, were first used in programming competitions. With the development of programming competitions and the opening of programming courses, various universities have gradually developed their own online judgement systems. For example, POJ of Peking University and ZOJ of Zhejiang University are two of the earliest online judgement systems in China. These online judgement systems have rich and high-quality programming practice problems, which attracted a large number of programming contestants to use these systems for practice. Nowadays, the main online judgement system used by colleges and universities is PTA, which contains a large number of basic problems in the problemset, so that teachers can add problems from the problemset into the question list by themselves, and check the feedback of students' performance. These features help to achieve better teaching results.
In the era of the Internet, there are abundant online teaching resources for students to learn and refer to, which helps the teaching of programming courses to perform, and also highlights the importance of online judgement system in the teaching of programming courses. For how to carry out a good programming course, how to combine the advantages of online course teaching and offline course teaching to improve the educational quality of online courses[1], is the focus of many scholars. Academics have conducted extensive research on the goal orientation, teaching mode, teaching evaluation, and course resource construction of programming courses in online courses and offline teaching[2]. Many believe that an online judgement system is an important tool for combining online courses with offline teaching, which can fully improve the teaching quality of programming courses[3]. Scholars have investigated the blended teaching model based on the "OJ+SPOC" platform, which has shown that by implementing a closed-loop teaching process before, during, and after the class, students' programming and problem-solving abilities can be significantly improved[4].
Online judgement system is an important tool in programming courses, with the help of online judgement system, it can make the boring classroom into a fun practice place, so that students can appreciate the wonders of programming through independent exploration. Students can broaden their horizons through a wealth of online teaching resources. From "paper programming", which only focuses on the degree of knowledge memorizing, to on-line programming, which focuses on practice.
An online judgement system is a tool that can fully release the exploratory abilities of students. However, in the process of students' exploration, due to the short time of exposure to programming and lack of experience in programming, many errors often occur. Moreover, students often do not have the ability to check and debug errors on their own, and they can do nothing about erroneous codes. If the errors are relatively obvious or common, students can solve the problems by discussing with each other. But in a practice-oriented subject like programming, errors can be quite subtle and may be difficult for novices to detect. Such as such an error:
#include<cmath>
#include<iostream>
using namespace std;
double x1,x2,y1,y2;
int main()
{
cin>>x1>>y1;
cin>>x2>>y2;
cout<<abs(x1-x2)+abs(y1-y2);
return 0;
}
The function of this code is to read in the coordinates of two points (x_1,y_1 ),(x_2,y_2) and compute the Manhattan distance between them. The code is not complicated and is a good exercise for novices to practice reading and handling variables in C++ programming. But the code as above does not compile. The error message is:
c:\mingw\include\math.h:273:24: note: previous declaration 'double y1(double)'
An experienced programmer can tell from this error message that there is a conflict between the variable y1 and y1 in the cmath library. For someone with a lot of debugging experience, it is very easy to locate this error, just analyse the error message and find the reason for the error in the cmath library. However, for a novice who is new to programming, the variable name was defined using the letters and subscripts as described in the title, and the variable name conformed to the specifications for C++ variable name definitions described in the class. Without being able to understand the error message, it takes a lot of time to independently locate and solve what seems to be a very simple error. Many students will even give up on the problem after a few attempts.
Spending too much time on error checking and debugging on a wrong code is not only a waste of students' learning time, but also a blow to their interest and confidence in learning programming. Due to the large number of students, and the students' code habits, errors vary greatly, and there is no standard answer to the programming problems, so it is often difficult for teachers to take into account the learning progress of all students in the class, and can not help all the students in a timely manner for the code error checking and debugging.
And at the end of 2022, a new generation of AI technology Large Language Models represented by ChatGPT came out, ChatGPT is able to understand natural language, achieve interaction with humans, and iteratively train through reinforcement learning techniques with human feedback (RLHF). Code generation is also an important area of concern for large models, and large language models pioneered by Codex have achieved impressive results in code generating, giving rise to commercial products such as GitHub Copilot and open source billions of code models such as StarCoder and Code LLaMA [5]. Many of these code generation models have demonstrated excellent capabilities in many tasks such as code generation, completion, interpretation, error correction, and unit testing. If these large models can be used in online judgement systems for programming teaching, the AI assistant based on the large models can help students to correct their code when they make mistakes, and help them to improve the efficiency of error checking and debugging, which can greatly solve the problems mentioned above.
2 System Functions and Architecture
2.1 System Functions
In order to achieve better teaching results in programming courses. Also considering the scalability of the system, this online judgement system has the following functions:
User rights and basic information management: The system has three levels of rights: administrator, teacher, and student. The system allows users to register accounts, log into the system, and manage personal information and settings. Teachers, based on courses and classes, import students' information, can view students' codes, issue assignments to students, and view data feedback on how students are doing.
Problemset Management: The system contains a problemset with a variety of programming practice problems. The problemset management function allows teachers or administrators to add, edit and delete problems, including problem descriptions, input/output samples, test results, etc. The system also provides support for multiple choice questions, judgement questions and other question types to help students consolidate their basic knowledge while practicing.
Judgement and Feedback: The system can automatically judge user submitted code. It can run the user code and compare it with the expected results to check its correctness. The system can also evaluate the performance indicators of the code, such as the running time of the code and the memory used during the running process. After completing the evaluation, the system gives instant feedback, including test case passes, error messages and performance analysis. At the same time, in order to prevent attacks and malicious submissions, the system must take certain security measures, such as placing the user's application in a sandbox for isolation during evaluation, performing syntax tree analysis on the code to prevent plagiarism, and detecting code overlap to prevent a large number of submissions within a short period of time.
Competition and Examination: Teachers can select specific problems in the problemset for examination, so as to check the practical ability of students in programming. In order to cope with the large-scale submission of the examination, the system should support the addition of multiple judgement machines, so as to achieve parallel judgement, and prevent the examination from the problem of excessive pressure on the judgement caused by multiple submissions of students, which affects the performance of the system. At the same time, the system is also geared towards the needs of programming contestants, and should also provide the corresponding competition function. The competition supports OI/IOI/ACM and other competition modes; there is a question area in the competition. The result of each game will calculate the rating for the user and provide a ranking of points. Each question has a Hack mechanism, i.e. you can look at other people's code and try to find out the loopholes, which is more rigorous and more fun.
Communication and discussion: When students have doubts about problems or have good ideas to share, they can use the blog function provided by the system to express their opinions. Other users can comment under the blog, thus achieving the function of communication and discussion.
Meanwhile, in order to save the students' time in code checking and debugging, in our online judgement system, if a code fails to pass all the test data, an AI assistant based on the large model will give advice on how to modify the code. This feature will be explained in more detail in the next section.
2.2 System Architecture
Architecture: A distributed system including front-end, back-end and error correction large model components was adopted.
Front-end: The system has a fully functional and user-friendly web interface, which includes functions such as submitting code, viewing error correction results, and providing feedback. The front-end sends the user's code to the back-end, waits for the back-end to process it and accepts the error correction and feedback information sent by the back-end, and displays the information in the front-end in an appropriate way to inform the user.
Backend: The system builds a high-performance server-side application that is responsible for receiving the code submitted by the user and evaluating the code. If the evaluation passes, the code will return the code pass (AC) message to the front-end. If the code can not pass all data, it will be sent to the error correction model for processing, and accepts the error correction information and feedback information, and sends these information to the front-end.
Error Correction Model: The system integrates a powerful code error correction model for automatically analysing and correcting errors in user-submitted code. On the basis of this model, special data from programming test questions are selected for Fine-turning training.
3 Code-Generating Large Model
3.1 Introduction to Code-Generating Large Model
Code-generating large models are trained using deep learning techniques for automatic generation of computer program code. These models are able to understand natural language descriptions or high-level abstract concepts and translate them into executable code. Code-generating large models are usually based on powerful language models such as GPT (Generative Pre-Training Models), which learn the syntax, structure and semantics of the code through a large-scale pre-training and fine-tuning process.
The training process for code-generating large models usually consists of two phases. First, pre-training is performed using a large library of publicly available code in order for the model to learn common code syntax and structure. Then, fine-tuning is performed on specific domains or tasks, such as natural language description-to-code conversion, code auto-completion, or code defect repair. These models have a wide range of applications and can be used to improve developer productivity, assist in code writing, automate software development processes, etc. They can also be used for educational purposes to help beginners understand the basic concepts and paradigms of code writing.
Integrated into the online judgement system proposed in this paper is CodeGeeX, a multilingual code generation model jointly created by Tsinghua and Wisdom Spectrum AI, which can achieve code translation, code completion generation, and basic question and answer functions that are available in large language models. Another important reason for choosing CodeGeeX is that the model supports many mainstream high-level programming languages such as C++, Java, Python, etc., and all of them have good results, which is applicable to a variety of programming course scenarios.
3.2 Fine-tuning and Training of CodeGeeX
Figure 1 Large model technology roadma
The CodeGeeX model was fine-tuned in the process of integrating it into an online judgement system in order to make CodeGeeX more capable of generating code for programming problems. The goal of fine-tuning the model was to make it more capable of solving programming problems, but not less capable. The multi-task fine-tuning capability of the CodeFuse-MFTCoder allows for multi-task fine-tuning (MFT) of the CodeGeex2-6B using multiple code task datasets. Formatting/splitting, syntax analysis, feature extraction, and causal judgement are performed on the obtained code files. The processed dataset will be provided to the big model for fine-tuning training. The fine-tuning is done by using the pre-trained model obtained on the big data to initialise the weights to improve the accuracy. Due to the small number of CodeGeex2-6B parameters, the training is performed using the multi-task LoRA fine-tuning mode of MFTCoder instead of QLoRA, and the code tasks are relatively complex tasks, we fine-tune more modules including Attention and MLP.
For the training datasets, classic public datasets and GitHub high-quality code outside were used. These datasets are mainly software development oriented codes, which are not very effective for code generation of programming topics, although they are helpful to some extent. In order to further improve the model's code generation ability for programming practice topics, a large amount of public code from Codeforces, PTA, Atcode, Topcoder, and other teaching or algorithmic competition practice platforms was additionally obtained using a crawler and added to the training data. The targeting ability of the model was further improved.
In order to evaluate the generative capability of the model, pass@k is chosen as the evaluation metric. The goal of this model is to perform code error correction and generate code, so traditional string similarity metrics such as BLEU are not suitable for evaluating the performance of the model. The pass@k adopted here is an approach to evaluate the performance of the generated code, which measures the accuracy of the generated code by using test cases.
In order to evaluate the generative capability of the model, pass@k is chosen as the evaluation metric. The goal of this model is to perform code error correction and generate code, so traditional string similarity metrics such as BLEU are not suitable for evaluating the performance of the model. The pass@k adopted here is an approach to evaluate the performance of the generated code, which measures the accuracy of the generated code by using test cases.
pass@k is defined as follows:pass@k =E(1-(((n-c)¦k))/((n¦k) )) ,where n denotes the number of models generated and k is the metric we selected,Usually k=1,10,100. c is the number of codes that pass all the test cases。(n¦k) denotes the number of combinations, (n¦k)=n!/(k!(n-k)!) 。The higher this metric is, the better the code generated by the model passes the test. The actual calculation of this metric can be done by calculating the value of 1-(((n-c)¦k))/((n¦k) ) for each topic, and then averaging the values afterwards for the overall metric.
3.3 Processes after Integrating a Large Model
The next section demonstrates the workflow of the system after integrating the large model of code error correction.
As an example, the code in Section 1 is submitted with a compilation error.
Figure 2 Compilation error in code
After that, you can click the "Ask AI Assistant" button to use the large model component.
You can find that the large model found the error in the original code, replaced the wrong variable name "y1" with "y1_val", and gave a more standardised code with additional comments, making the code clearer and easier to understand.
Figure 3 Large mode gives a correct code
4 Conclusion
This online judgement system with integrated large model is currently in the testing stage and will be put into use in programming courses in the near future. While the system has the functions of a basic online judgement system, it also integrates the code error correction model, which can provide timely help to students when they encounter problems, alleviate the problem of difficult to answer questions in programming courses, and improve the teaching quality of programming courses.
Reference
[1] Xiang Zhou, Yanping Zhang, Practice of "Online+Offline" Blended Teaching Mode for Basic Programming Courses[J]. Computer Education, 2021(8): 138-141
[2] Ning Liu, Xia Mengyan, Ru Liu, et al. Research on online-offline integrated teaching mode of Python public course[J]. Science and Technology Wind, 2021(9): 62-63
[3] Yong Liu, Kai Tina, Xiaolin Zhou, et al. Practical Teaching of Programming with OJ System and Subject Competition[J]. Journal of Higher Education, 2021(6): 28-31
[4] Cuixiao Zhang, Guobing Zhang. Blended teaching practice of programming course based on "OJ+SPOC"[J]. China Management Informatisation, 2021, 24(19): 230-232
[5] Zhang Z, Chen C, Liu B, et al. A survey on language models for code[J]. arXiv preprint arXiv:2311.07989, 2023
七 力扣爬虫
1.登录
爬取力扣上的数据首先需要进行登录,使用 Chrome 的开发者模式来确定登录时提交的信息。
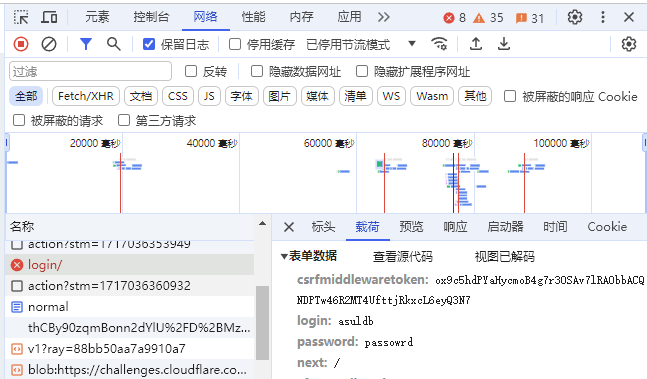
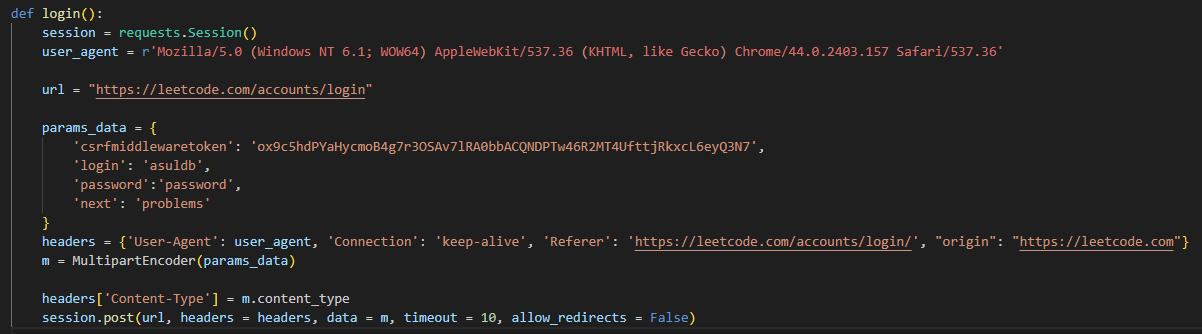
经过登录验证,发现是通过 https://leetcode.com/accounts/login 这一接口提交了登录表单,使用爬虫进行登录的时候需要填写表单中对应的数据。其中 csrfmiddlewaretoken 是 cookie 值,需要登录后进行获取。
为了保持连接,可以使用 requests.Session() 方法,可以维持多个连接。登陆成功力扣会自动进行跳转,为了避免这一问题,可以在 post 方法中将 allow_redirects 设置为 Fasle 禁止跳转。
2.获取题目信息
https://leetcode.com/api/problems/all/ 接口是获取所有题目的接口。获取解析里面的数据便可以得到所有题的名称,但并不能获取题目的详细信息。而我们所需要的是详细的信息。
当点击一道题目时,分析所使用的请求,发现是一个 https://leetcode.com/graphql 的请求,返回了题目的详细信息。
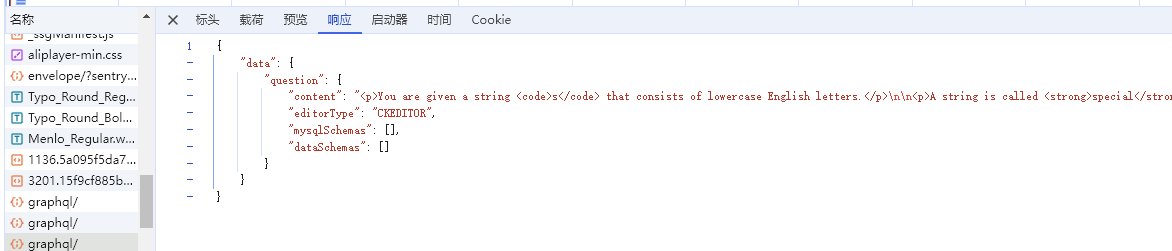
GraphQL 是一种用于 API 的查询语言,查询方式类似于 SQL,对于该题请求为:

可以发现请求包含题目名称等信息,我们将对应题目的查询请求提交即可获得返回的题目详细信息。
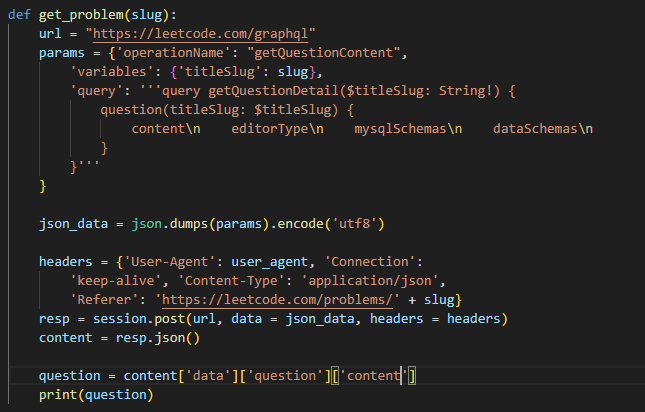
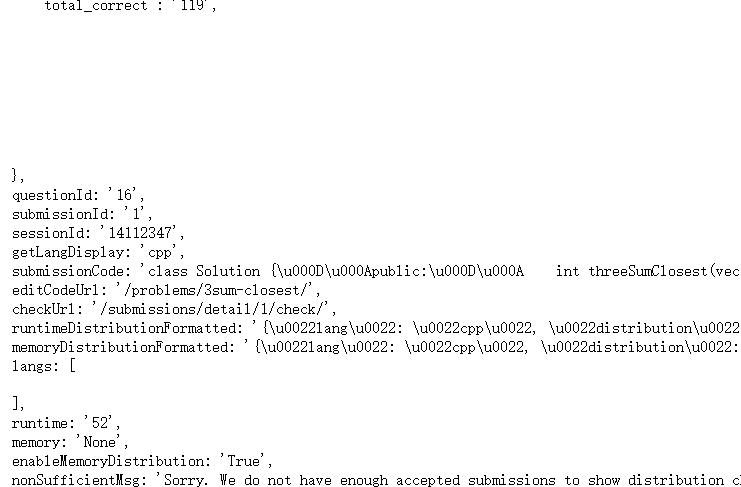
3.获得正确代码
查看代码必须是在登录状态下,所以之前实现的登录是非常必要的。
可以使用 GraphQL 获取提交记录的简单信息,但是无法其中并不包含代码。
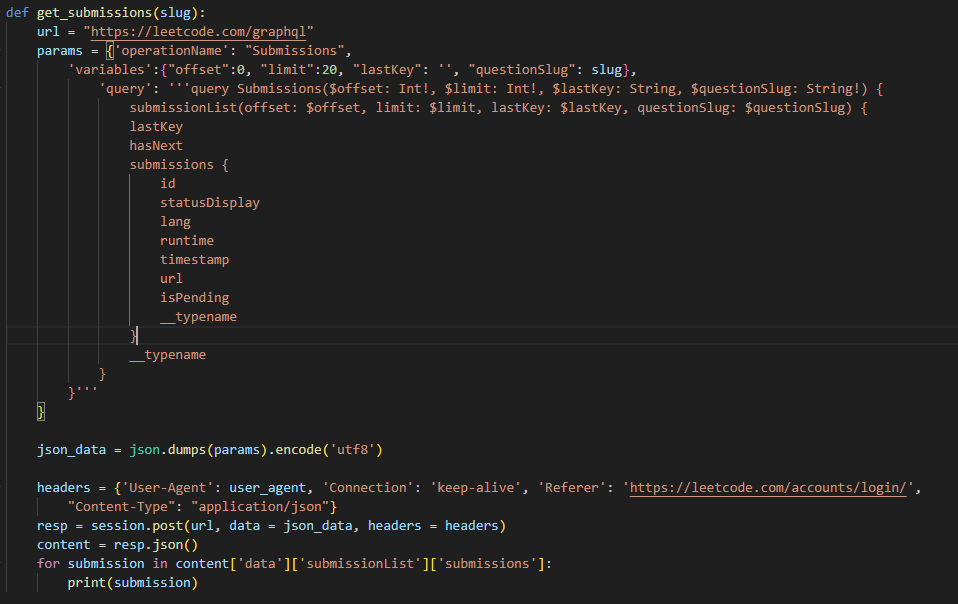
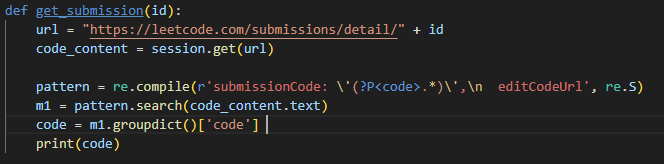
我们考虑通过 https://leetcode.com/submissions/detail/1/ 来获取代码,对页面分析发现这里并没有调用请求数据,查看页面的源代码,发现使用了一个pageData 的函数,代码应该是使用 JS 渲染而成,因此只能通过传统的获取页面源码正则解析的方式。代码被赋予到一个 submissionCode 的变量中去了,可以通过正则表达式获取该变量。