InnoDB存储引擎:文件和表
文件
构成MySQL数据库和InnoDB存储引擎表的各种类型文件:
- 参数文件(告诉MySQL实例启动时在哪里可以找到数据库文件,并且指定某些初始化参数)
- 日志文件(用来记录MySQL实例对某种条件做出响应时写入的文件)
- socket文件(当用UNIX域套接字方式进行连接时需要的文件)
- pid文件(MySQL实例的进程ID文件)
- MySQL表结构文件(用来存放MySQL表结构定义文件)
- 存储引擎文件(存储了记录和索引等数据)
表
索引组织表
根据主键顺序组织存放的表称为索引组织表。
如果在创建表时没有显式地定义主键,则InnoDB存储引擎会按如下方法选择或创建主键:
- 首先判断表中是否有非空的唯一索引,如果有,则该列为主键。
- 如果不符合上述条件,InnoDB存储引擎自动创建一个6字节大小的指针。
当表中有多个非空唯一索引时,InnoDB存储引擎将选择建表时第一个定义的非空唯一索引为主键。
_rowid可以显示表的主键,但是它只能用于查看单个列为主键的情况,对于多列组成的主键就显得无能为力了。
InnoDB逻辑存储结构
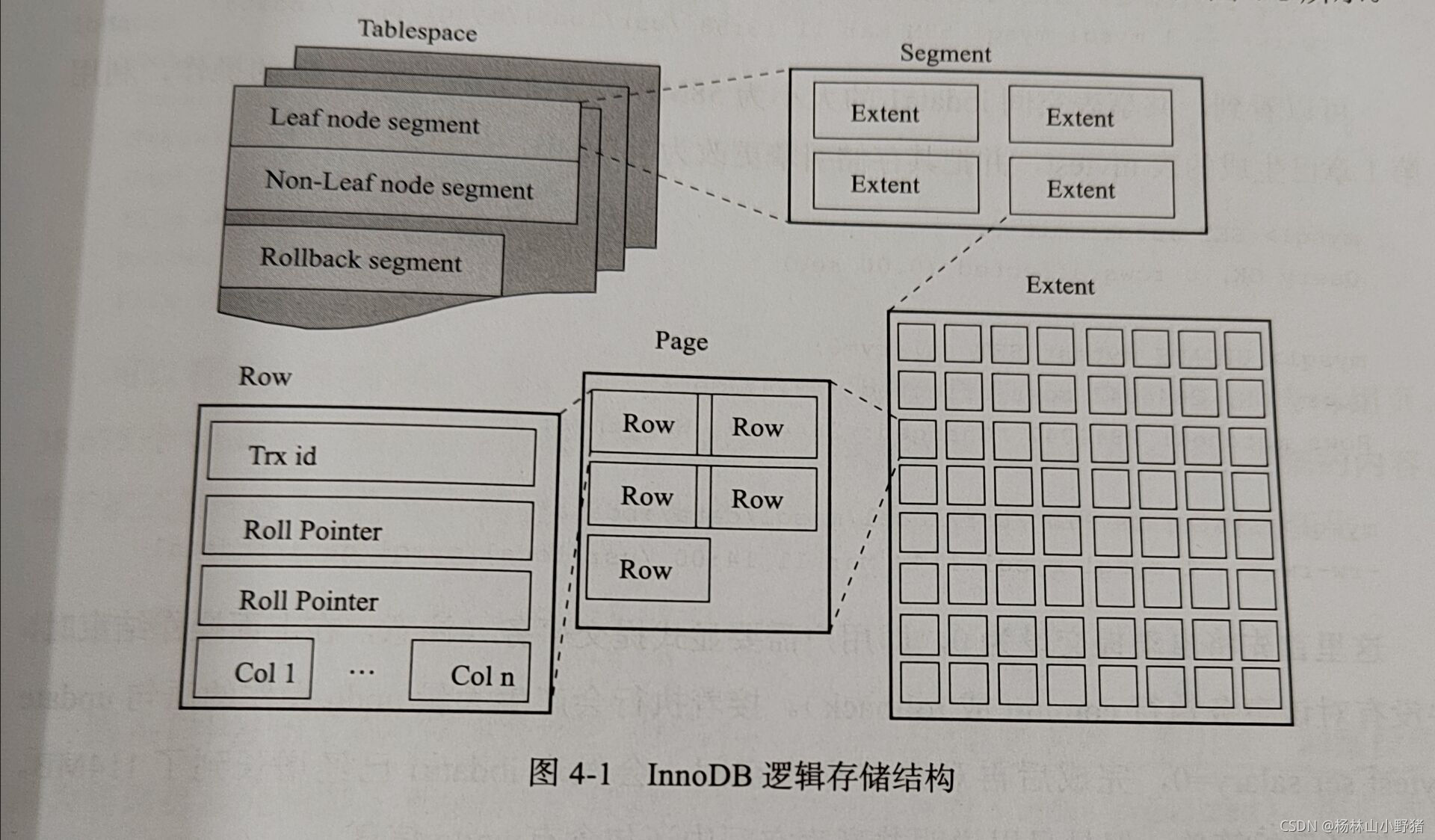
表空间:InnoDB存储引擎逻辑结构的最高层,所有的数据都存放在表空间中。
段:段组成了表空间,常见的段有数据段(B+树的叶子节点)、索引段(B+树的非叶子节点 )、回滚段等。
区:由连续的页组成的空间,在任何情况下每个区的大小都为1MB。
页:InnoDB磁盘管理的最小单位。
行:InnoDB存储引擎是面向行的,也就说数据是按行进行存放的。
InnoDB行记录格式
InnoDB 1.0.x版本之前,InnoDB存储引擎提供了 Compact 和 Redundant 两种格式来存放行记录数据;1.0.x版本开始引入了新的文件格式,以前支持的 Compact 和 Redundant 格式称为 Antelope 文件格式,新的文件格式称为 Barracuda 文件格式,该文件格式下拥有两种新的行记录格式 Compressed 和 Dynamic。
Compact 行记录格式
Compact 行记录格式的设计目标是高效地存储数据。

非NULL变长字段长度列表:按照列的顺序逆序放置的,其长度最大不可以超过2字节。
NULL标志位:指示了该行数据中是否有NULL值。
记录头信息:固定占用5字节。
后面的列数据有两个隐藏列:事务ID列和回滚指针列,分别为6字节和7字节的大小。若InnoDB表没有定义主键,每行还会增加一个6字节的 rowid 列。
不管是 CHAR 类型还是 VARCHAR 类型,在 compact 格式下 NULL 值都不占用任何存储空间。
Redundant 行记录格式

记录头信息:固定占用6字节。
其余同 Compact
对于 CHAR 类型,在 Redundant 格式下 NULL 值占用存储空间;而对于 VARCHAR 类型,不占用任何存储空间。
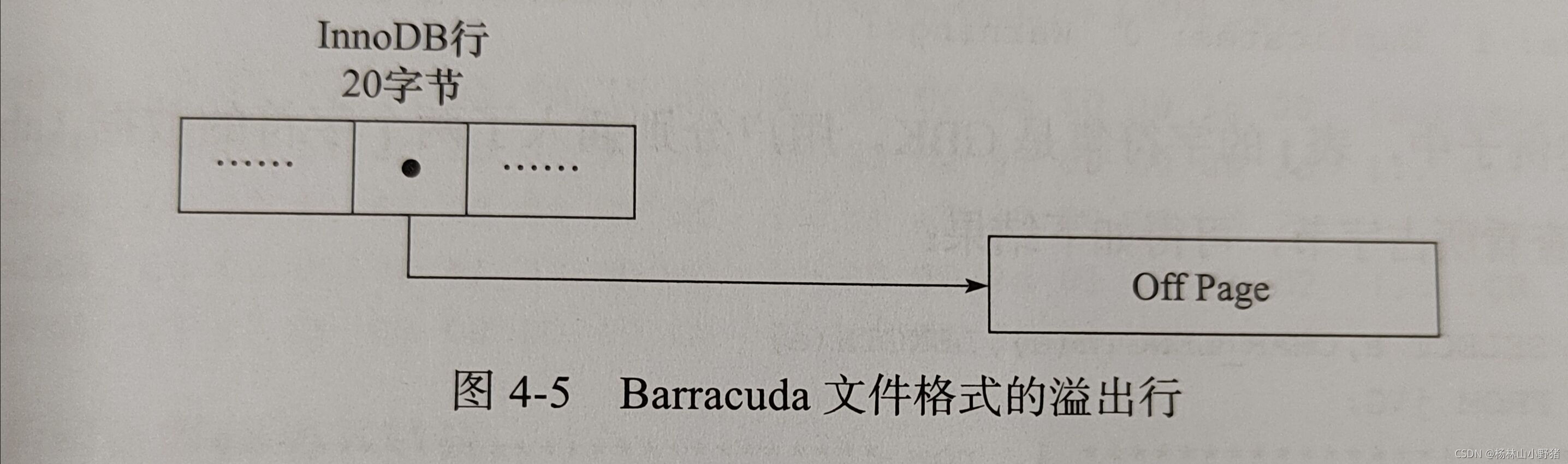
Compressed 和 Dynamic 行记录格式
对于存放在BLOB中的数据采用了完全的行溢出的方式:
InnoDB数据页结构
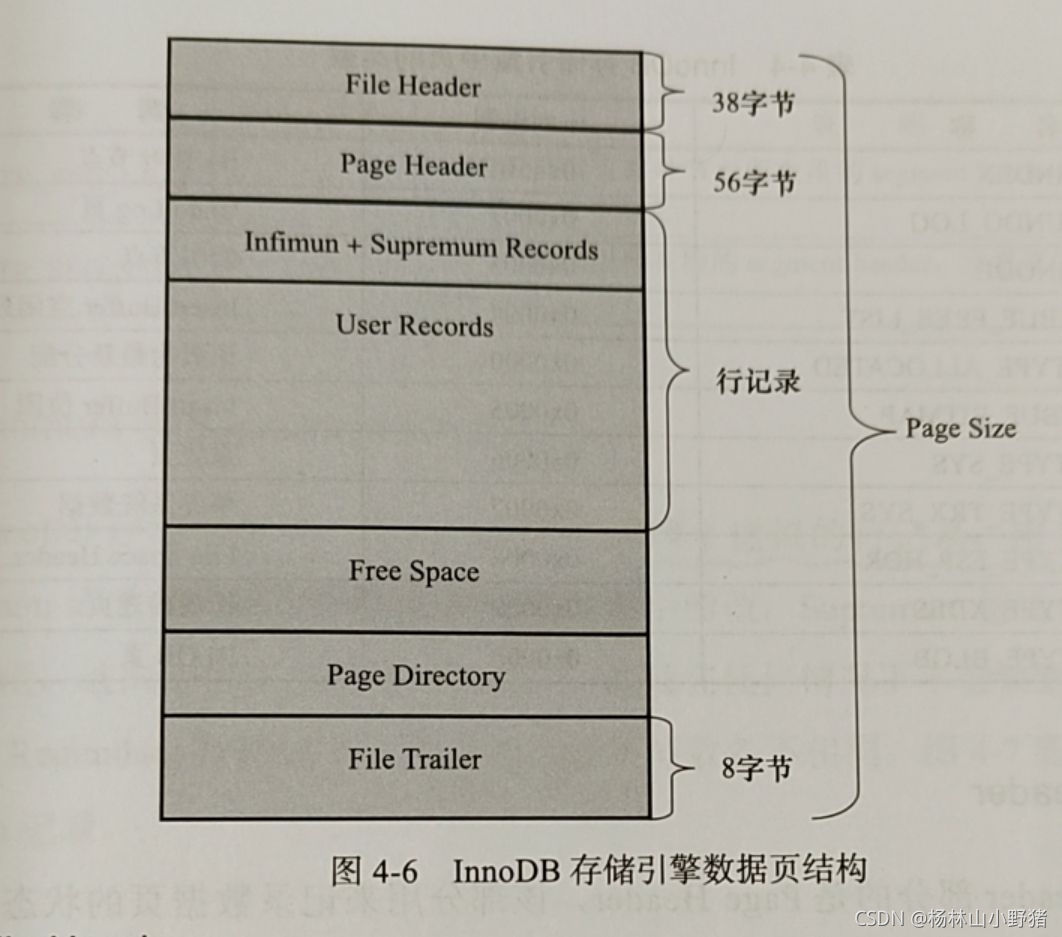
Infimum 和 Supremum Record:虚拟的行记录,用来限定记录的边界。
Page Directory:存放了记录的相对位置。
约束
约束机制提供了一条强大而简易的途径来保证数据库中数据的完整性。
对于 InnoDB存储引擎本身而言,提供了以下几种约束:
- Primary Key(约束名为 PRIMARY)
- Unique Key(默认约束名与列名相同)
- Foreign Key(用来保证参照完整性)
- Default(用来指定某列的默认值)
- NOT NULL(指定约束字段必须有值存在)
约束的创建
约束的创建有两种方式:
- 表建立时就进行约束定义
- 利用 ALTER TABLE 命令来进行创建约束
约束和索引的区别
当用户创建了一个唯一索引就创建了一个唯一的约束。但是约束和索引的概念还是不同的,约束更是一个逻辑的概念,用来保证数据的完整性;索引是一个数据结构,既有逻辑上的概念,在数据库中还代表着物理存储的方式。
对错误数据的约束
如果用户想通过约束对于数据库非法数据的插入或更新,即MySQL数据库提示报错而不是警告,那么用户必须设置参数 sql_mode,用来严格审核输入的参数。
ENUM和SET约束
MySQL数据库不支持传统的 CHECK 约束,但是通过 ENUM 和 SET 类型可以解决部分这样的约束请求。但是只限于对离散数值的约束,对于传统 CHECK 约束支持的连续值得范围约束或更复杂的约束,需要通过触发器来实现对值域的约束。
触发器与约束
触发器的作用是在执行 INSERT、DELETE 和 UPDATE 命令之前或之后自动调用 SQL 命令或存储的过程。(最多可以为一个表建立6个触发器)
视图
视图是一个命名的虚表,它由一个 SQL 查询来定义,可以当作表使用。视图中的数据没有实际的物理存储。
视图的主要用途之一是被用做一个抽象装置,在一定程度上起到一个安全层的作用。
分区表
MySQL 数据库支持的分区类型为水平分区,并不支持垂直分区。
MySQL 数据库的分区是局部分区索引,一个分区既存放了数据又存放了索引。
分区主要用于数据库高可用性的管理。
分区类型如下:
- RANGE 分区(分区列的值连续)
- LIST 分区(分区列的值离散)
- HASH 分区(使用用户定义的函数进行分区)
- KEY 分区(使用MySQL数据库提供的函数进行分区)
- COLUMNS 分区(可以直接使用非整型的数据进行分区)
子分区是在分区的基础上再进行分区,MySQL数据库允许在 RANGE 和 LIST 的分区上再进行 HASH 或KEY 的子分区。
子分区的建议需要注意以下几点:
- 每个子分区的数量必须相同。
- 要在一个分区表的任何分区上使用 SUBPARTITION 来明确定义任何子分区,就必须定义所有的子分区。
- 每个 SUBPARTITION 子句必须包括子分区的一个名字。
- 子分区的名字必须是唯一的。
MySQL数据库允许对 NULL 值做分区,其分区总是视 NULL 值小于任何一个非 NULL 值。
RANGE 分区会将 NULL 值放入最左边的分区;LIST 分区必须显式地指出哪个分区中放入 NULL 值;HASH 和 KEY 分区的任何分区函数都会将 NULL 值的记录返回为 0。
最后注意的就是,分区并不总是适合于 OLTP 应用,用户应该根据自己的应用好好来规划自己的分区设计;对于 OLAP 应用,分区可以很好地提高查询的性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号