InnoDB存储引擎:索引与算法
InnoDB存储引擎索引概述
InnoDB支持以下几种常见的索引:
- B+ 树索引 (传统意义上的索引,这是目前关系型数据库系统中查找最为常用和最为有效的索引;B+ 树索引并不能找到一个给定键值的具体行,能找到的只能是被查找数据行所在的页)
- 全文索引 (将存储于数据库中的整本书或整篇文章中的任意内容信息查找出来的技术)
- 哈希索引 (自适应,InnoDB存储引擎会根据表的使用情况自动为表生成哈希索引,不能人为干预是否在一张表中生成哈希索引;哈希索引只能用于搜索等值查询 )
B+ 树索引
B+ 树索引的本质就是B+ 树在数据库中的实现,其有个特点为高扇出性。
数据库中的B+ 树索引可分为:
- 聚集索引
- 辅助索引
聚集索引与辅助索引不同的是,叶子节点存放的是否是一整行的信息。
聚集索引
聚集索引:叶子节点中存放的即为整张表的行记录信息。
由于实际的数据页只能按照一棵B+ 树进行排序,因此每张表只能拥有一个聚集索引。
如果聚集索引必须按照特定的顺序存放物理记录,则维护成本显得非常之高;所以聚集索引的存储并不是物理上连续的,而是逻辑上连续的;聚集索引还一个好处就是对于主键的排序查找和范围查找速度非常快。
辅助索引
辅助索引也成为非聚集索引,叶子节点并不包含行记录的全部数据。
下图为辅助索引与聚集索引的关系:
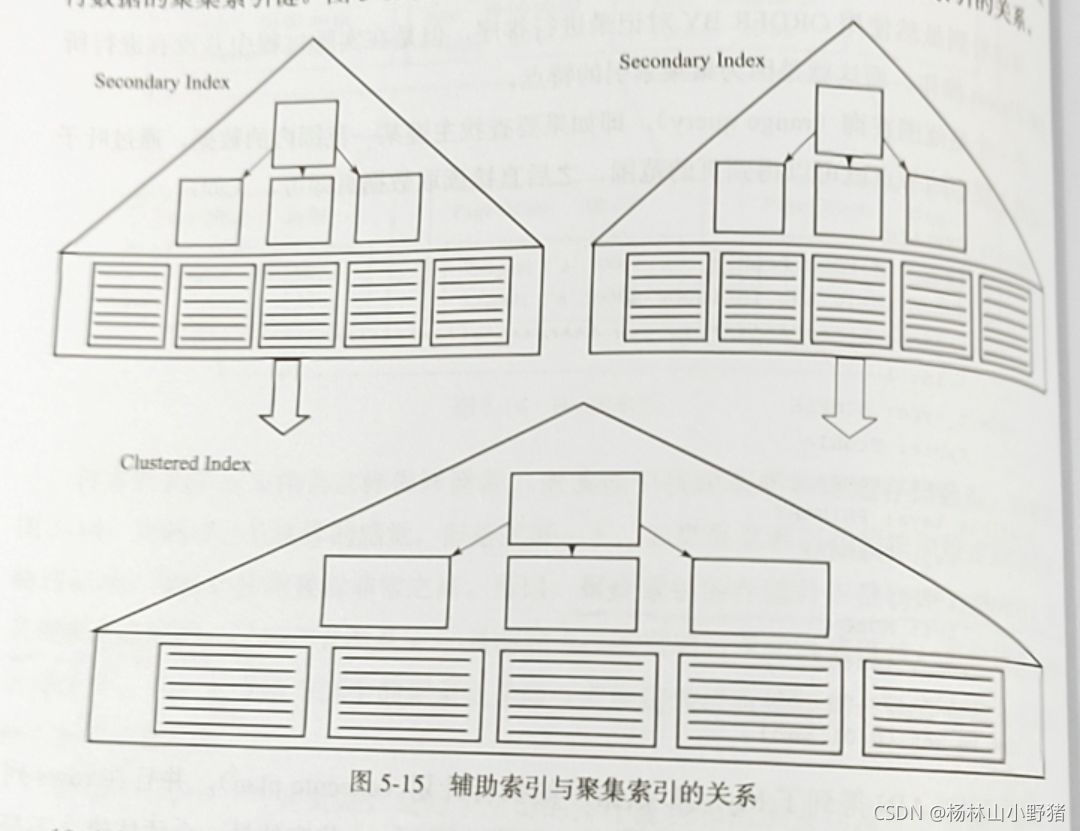
InnoDB存储引擎的辅助索引的书签就是相应行数据的聚集索引键。
辅助索引的存在并不影响数据在聚集索引中的组织,因此每张表上可以有多个辅助索引。
Cardinality 值
先看一下表中索引的信息:

- table:索引所在的表名
- Non_unique:非唯一的索引(0表示唯一;1表示不唯一)
- Key_name:索引的名字
- Seq_in_index:索引中该列的位置
- Column_name:索引列的名称
- Collation:列以什么方式存储在索引中
- Cardinality:索引中唯一值的数目的估计值
- Sub_part:是否是列的部分被索引(这里显示100,表示只对b列的前100字符进行索引;如果索引整个列,那么就为 NULL)
- Packed:关键字如何被压缩(NULL表示未被压缩)
- Index_type:索引的类型
- Comment:注释
Cardinality 值非常关键,表示索引中不重复记录数量的预估值。
数据库对于 Cardinality 的统计都是通过采样的方法来完成的。
采样过程如下:
- 取得 B+ 树索引中叶子节点的数量,记为 A
- 随机取得 B+ 树索引中的 8 个叶子节点(默认InnoDB存储引擎对8个叶子节点进行采样),统计每个页不同记录的个数,即为 P1,P2,...,P8
- 根据采样信息给出 Cardinality 的预估值:Cardinality = (P1 + P2 + ... + P8) * A / 8
由于是随机选取了 8 个叶子节点,故而每次得到的 Cardinality 值可能是不同的;当表的叶子节点数小于等于 8 时,那么每次得到的 Cardinality 值就相同了。
B+ 树索引的使用
- 联合索引:对表上的多个列进行索引(避免多次的排序操作)
- 覆盖索引:从辅助索引中得到查询的记录,不需要查询聚集索引中的记录(辅助索引不包含整行记录的所有信息,故其大小远小于聚集索引,因此可以减少大量的IO操作)
Multi-Range Read 优化
MySQL5.6版本开始支持 MRR优化 ,该优化的目的就是为了减少磁盘的随机访问,并且将随机访问转化为较为顺序的数据访问。

Index Condition Pushdown 优化
ICP优化同样是 MySQL5.6版本开始支持的一种根据索引进行查询的优化方式,当进行索引查询时,首先根据索引来查找记录,然后再根据 WHERE 条件来过滤记录。可以大大减少上层 SQL 层对记录的索取,从而提高数据库的整体性能。
全文索引
InnoDB存储引擎从1.2.x版本开始支持全文检索的技术,其采用 full inverted index 的方式。
倒排索引
全文检索通常使用倒排索引来实现。其拥有两种表现形式:
- inverted file index,其表现形式为
- full inverted index,其表现形式为

 浙公网安备 33010602011771号
浙公网安备 33010602011771号