操作系统导论习题解答(29. Locked Data Structures)
Lock-based Concurrent Data Structures
带着问题:给定一个数据结构,如何给其添加锁使其拥有正确性和高效性?
1. Concurrent Counters
1.1 Simple But Not Scalable


上述代码满足了正确性,但是对于性能,我们一无所知。为了了解性能优劣,做了一个基准测试,如下所示(precise):
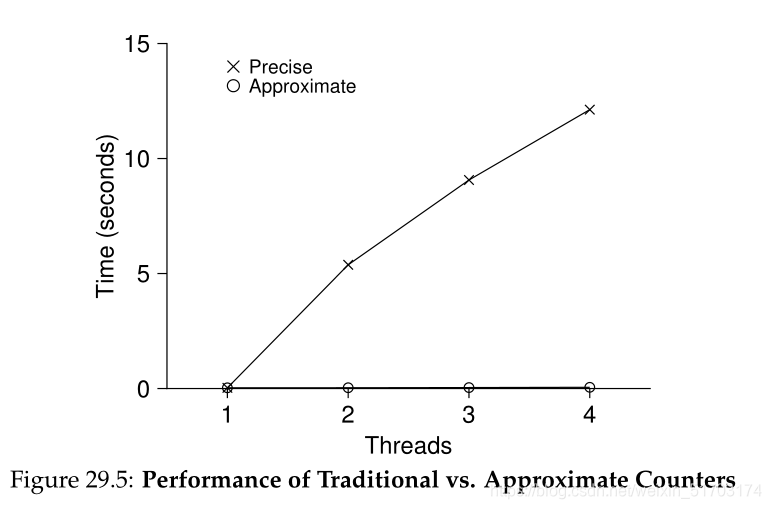
从上图可以看出,单线程性能可以,但是一旦多线程,性能极差!
perfect scaling:多处理器处理多线程性能和单处理器处理单线程性能几乎一样。
1.2 Scalable Counting
一种解决可扩展问题的方法叫approximate counter(近似计数)。
近似计数的基本思想如下:当在给定内核上运行的线程希望增加计数器时,它会增加其本地计数器,通过相应的本地锁同步对该本地计数器的访问。由于每个CPU都有自己的本地计数器,所以CPU上的线程可以在不用争的情况下更新本地计数器,因此该计数器的更新是可伸缩的。为了使全局计数器保持最新,通过获取全局锁并将其递增本地计数器的值,本地值会定期传输到全局计数器。
看一个例子,定期传输阈值为5。如下所示:
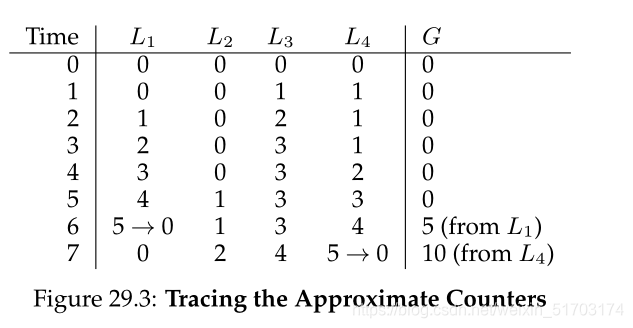
再看一次下图(approximate):
性能非常好(very good)!
下图展示了传输阈值对性能的影响:
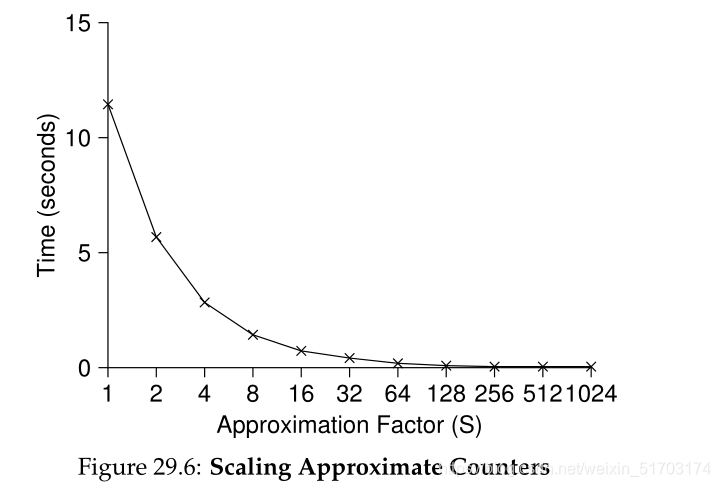
S越小,虽然性能越低,但是全局计数器越精确;S越大,性能越好,但是全局计数器越滞后。(精度/性能不可兼得)
下面是近似计数的代码:

2. Concurrent Linked Lists

对于上述代码,我们能否重写List_Insert()和List_Lookup()使其在并发插入情况下避免失败路径也需要调用unlock?

2.1 Scaling Linked Lists
一种在list中实现更多并发性的技术:hand-over-hand locking
其基本思想如下:不是整个list有一个锁,而是list中的每个node都有一个锁。在遍历list时,代码首先获取下个node的锁,然后释放当前node的锁。
这种方法确实有意义,实现了list操作的高度并发性。但是很难使这种结构比简单的单锁方法快(获取和释放遍历list中每个node的锁太耗时)。
3. Concurrent Queues

有两个锁,一个队头一个队尾,分别适用于入队和出队。
4. Concurrent Hash Table


 浙公网安备 33010602011771号
浙公网安备 33010602011771号