线性回归模型
概率分布
1 二元变量
1 伯努利(Bernoulli)分布的形式如下
实际上伯努利分布没有自己的记号,考虑其作为二项分布的一个特例,可以用\(B(1,\mu)\)作为伯努利实验结果的表示。即若\(X\sim B(1,\mu)\),则
\[P\left(X=x\right)=\text{Bern}(x|\mu). \]
容易得出,其均值与方差分别为
假定我们有\(N\)个独立观察到的样本构成的数据集\(\mathcal{D}=\left\{x_1,...,x_N\right\}\),则似然函数为
似然对数为
关于\(\mu\)的梯度为零,求得最大似然估计为
二项分布形式如下
假设\(X\sim B(N,\mu)\),则
\[P(X=m)=\text{Bin}(m|N,\mu). \]
其均值和方差分别由下式给出
2 注意到通过\(N\)次独立伯努利实验对参数\(\mu\)进行估计时,似然函数为\(\mu\)和\(1-\mu\)指数之积,由此引入如下beta先验分布
其中\(\Gamma(a+b)/\Gamma(a)\Gamma(b)\)是归一化常数,\(\Gamma(\cdot)\)形式如下
该分布的均值和方差分别为
由于后验分布正比于先验分布于似然分布之积(倍数为与随机变量无关的某常数),因此在对二项分布进行参数估计时,后验分布满足
其中\(l\)满足
通过简单对比,容易给出后验分布的完整表示
当数据规模趋于无穷时,贝叶斯估计和最大似然估计相同。
2 多元变量
1 考虑伯努利分布的\(K\)维扩展,使用\(\mathbf{x}=\{x_1,...,x_K\}\)表示状态随机变量,满足
若以下概率条件成立
则随机变量的分布为
其中\(\boldsymbol\mu=(\mu_1,...,\mu_K)^\text T\),约束条件为\(\mu_k\geq 0\)且\(\sum_k\mu_k=1\)。
现在假定我们有\(N\)个独立观察到的样本构成的数据集\(\mathcal D=\{\mathbf{x}_1,...,\mathbf x_K\}\),则似然函数为
对数似然函数为
考虑到约束条件
利用拉格朗日乘子法可求得最大似然解
给定参数\(\boldsymbol\mu\),在\(N\)次独立观测中\(m_1,...,m_K\)的联合分布即多项分布(二项分布的扩展)
其中
同时有约束条件
2 通过比较,多项分布的共轭先验应该具有如下形式
其中\(0\leq\mu_k\leq 1\)且\(\sum_k\mu_k=1\),\(\boldsymbol\alpha=(\alpha_1,...,\alpha_K)^\text T\)。归一化后的狄利克雷分布为
其中
3 高斯分布
4 指数族分布
5 非参数化方法
1 参数化方法的运行结果依赖于模型的选择(多大程度上正确描述了真实数据的分布情况),相较而言,非参数化方法所作的假设要少得多。非参数化方法也分为基于频率和贝叶斯两类,这里主要讨论前者。考虑最简单的使用直方图进行密度估计,假设随机变量\(x\)为一维连续变量,将\(x\)的取值区间切分为若干宽度为\(\Delta_i\)的小块,落到第\(i\)块内的观测样本数为\(n_i\),总样本数为\(N\),从而给出对该块概率密度\(p_i\)的估计为
显然这种估计方法给出的密度估计呈阶梯状,当选取的块宽\(\Delta_i\)较小时,由绘制出的频数直方图可见,此时的密度估计对样本(尤其是其随机性)较为敏感,
我们说密度估计对样本随机性敏感是指这种估计过分还原了样本作为真实分布反映的特性从而损失了其对原本分布共性的复原。在极端情形下,当块宽极小时,密度估计和样本可以近似等价(相互无损失转换)。
其平滑性较差,而当块宽\(\Delta_i\)较大时,此时的密度估计容易丢失重要的分布特征,如下图所示(第一行)。实际上适当的\(\Delta_i\)的选取才能给出对原始分布的最佳估计,这与所谓模型复杂度或控制模型复杂度的正则化参数的选取殊途同归。
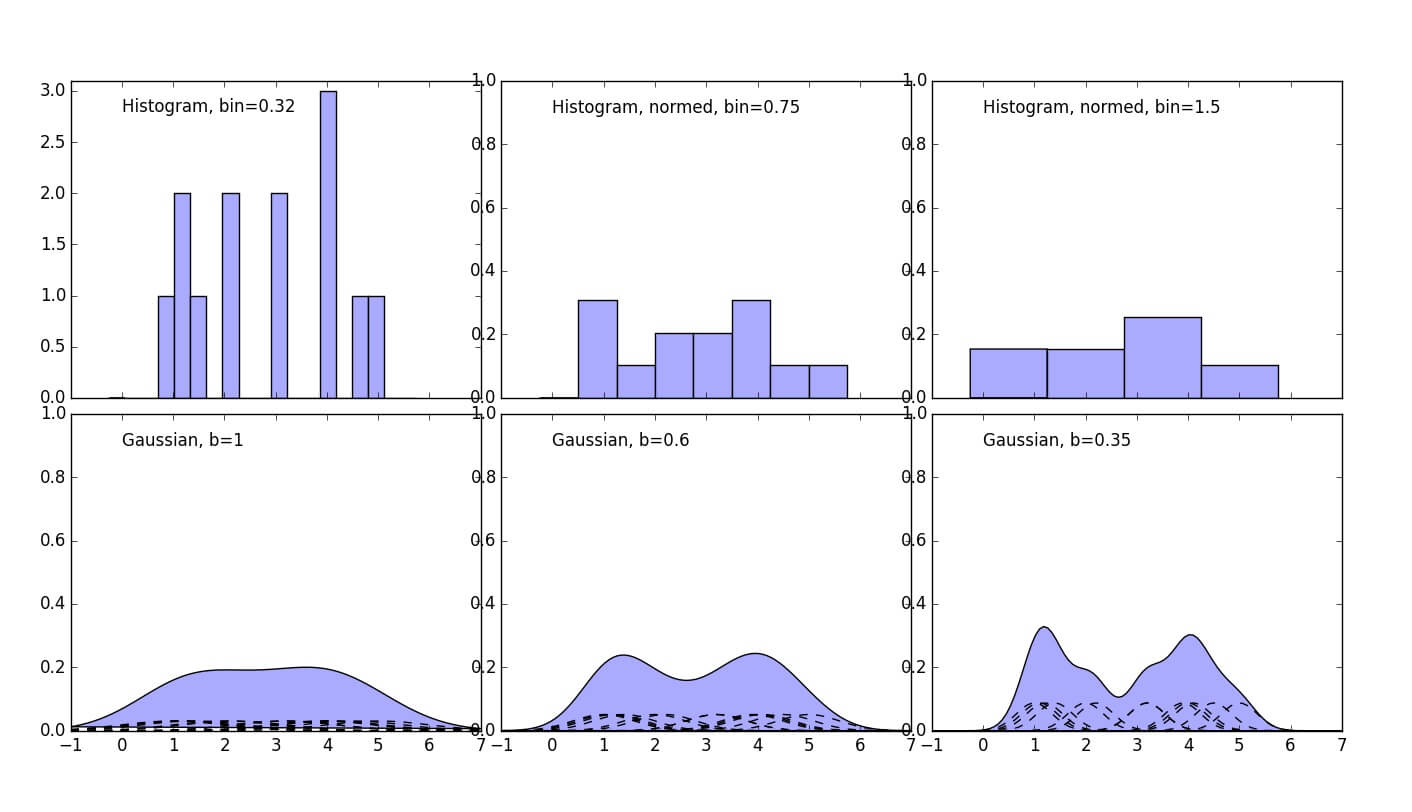
直方图估计的缺点主要是密度估计不连续以及维数受限的问题。在\(D\)维空间中,每一维使用\(M\)个小块,总需\(M^D\)个小块,随着\(D\)的增大,该数量呈指数式上升。此外所需的训练数据规模也以该速度增加。为了解决维数扩展的问题,以下介绍两种非参数化密度估计方法,分别是核估计和最近邻。
2 受直方图估计的启发,密度估计应该在待估计点的附近(locality)进行。假设观测数据由某个定义在\(D\)维空间的密度函数\(p(\mathbf{x})\)给出,考虑包含\(\mathbf{x}\)的一个小区域\(\mathcal{R}\),其概率为
假设观测数据规模(包含的观测点数目)为\(N\),落在区域\(\mathcal{R}\)内的数目为\(K\),从而\(K\)作为随机变量,其分布满足
由于\(\mathbb{E}[K/N]=\mathbb{E}[K]/N=P\),且\(\text{var}[K/N]=\text{var}[K]/N^2=P(1-P)/N\),从而当\(N\)充分大时,满足
\[\lim_{N\rightarrow \infty}\mathbb{E}\left[\frac{K-NP}{NP}\right]=0, \]\[\lim_{N\rightarrow \infty}\text{var}\left[\frac{K-NP}{NP}\right]=\lim_{N\rightarrow \infty}\frac{1-P}{NP}=0. \]
假设\(\mathcal{R}\)足够小,从而概率密度近似为某定值,满足
从而对\(p(\mathbf{x})\)的估计为
值得注意的是,为了给出对概率密度“足够好”的估计,我们使用了两条不一致的假设。一方面,\(\mathcal{R}\)应该充分小,从而区域密度恒定;另一方面,\(\mathcal{R}\)也应该足够大从而保证落入该区域的观测点数目足够接近\(NVp(\mathbf{x})\)。
当\(N\)充分大时,\(K/V\)充分大(\(K\)增\(V\)减),\(p(\mathbf{x})\)将收敛于真实密度。
核方法固定\(V\)调整\(K\),而最近邻固定\(K\),调整\(V\)。
3 核函数法固定体积统计频数。区域\(\mathcal{R}\)是以\(D\)维空间中的点\(\mathbf{x}\)为中心的超立方体,其边长为\(h\),定于如下核函数(此处亦称Parzen窗)
显然当且\(\mathbf{x_n}\)落在\(\mathcal{R}\)内(或边界上)时,核函数值\(k((\mathbf{x}-\mathbf{x_n})/h)\)为\(1\)。从而落在\(\mathcal{R}\)内数据点总数\(K\)满足
从而对点\(\mathbf{x}\)处的密度估计为
与直方图估计法一样,该核函数的选取意味着超立方体边界处密度估计值不连续,为此可以选取平滑的核函数,如高斯核:
从而核密度估计模型为
很显然,该模型是以\(N\)个数据点为中心的\(D\)维高斯模型的混合,常系数\(1/{N\sqrt{2\pi}h}\)使得该密度模型正确规范化。
推而广之,核密度估计或Parzen估计模型只需选取的核函数满足如下两个条件
\[\begin{aligned}k(\mathbf{u})&\geq 0,\\\int k(\mathbf{u})&=1.\end{aligned} \]
该估计方法在训练阶段计算代价为\(0\),在测试阶段计算代价为\(O(N)\)。
4 核估计的一个缺点是参数\(h\)的选取(决定平滑程度/模型复杂度)是全局的,而实际上我们希望\(h\)可以自适应地根据数据点位置进行调整。\(K\)近邻方法是固定\(K\)调整\(V\)进行密度估计的方法:选取以\(\mathbf{x}\)为中心恰好能包含\(K\)个数据点的球体,其体积记为\(V\),从而该出的密度估计值为\(p(\mathbf{x})=K/VN\)。这里控制模型复杂度的参数为\(K\)。利用贝叶斯公式可将该模型用于分类问题,误分率最低的决策是将\(\mathbf{x}\)赋给球内出现频数最高的类别。特别地,当\(K=1\)使,将\(\mathbf{x}\)赋给距离其最近的数据点所属类别,当\(N\)趋于无穷大时,其误分率不会超过最优决策(按真实类别分布计算)的两倍。
