就业培训学习记录-day002
课堂任务
了解Linux的部分常用命令
- ps
英文:process status
说明:显示当前进程的状态,类似于 Windows 的任务管理器。
语法:ps [options] [--help]
ps -ef显示所有命令,连带命令行。
ps -ef | grep [进程关键字]查找指定进程格式。
ps -A列出所有的进程。
ps aux没有-号,可以查看系统中所有的进程。
ps -le可以查看系统中所有的进程,还能看到进程的父进程的PID和进程优先级。
进程管理命令:
- 程序是静态概念,本身作为一种软件资源长期保存,而进程是程序的执行过程,它是动态概念,有一定的生命周期,是动态产生和消亡
- 程序和进程无一一对应关系,一个程序可以由多个进程共用。
进程和线程的区别:
进程:进程就是正在执行的程序或命令
线程:轻量级的进程,进程有独立的地址空间,线程没有
-
kill
说明:关闭进程。
语法:kill [选项] [PID]
kill -9 1234强制关闭PID为1234的进程 -
useradd
说明:用于建立用户帐号。
语法:useradd [选项] [用户名]
useradd -r tt建立系统用户tt -
passwd
英文:password
说明:更改用户密码。
语法:passwd [选项] [用户名]
passwd tt设置tt用户的密码,要输入两次密码,密码无回显
passwd -d tt删除tt用户的密码 -
三种基本权限
r 读权限,w 写权限,x 执行权限,- 无权限
文件权限说明:
-rwxrw-r--
第1位:文件类型(d目录,-普通文件,l连接文件)
第2-4位:所属用户权限,用u(user)表示
第5-7位:所属组权限,用g(group)表示
第8-10位:其他用户权限,用o(other)表示
第2-10位:表示所有的权限,用a(all)表示
| 字符 | 权限 | 对文件的含义 | 对目录的含义 |
|---|---|---|---|
| r | 读权限 | 可以查看这个文件的内容 | 可以列出目录的内容(ls) |
| w | 写权限 | 可以修改文件内容 | 可以在目录中创建删除文件(mkdir,rm) |
| x | 执行权限 | 可以执行文件 | 可以进入目录(cd) |
- chmod
英文:change mode
说明:控制用户对文件的权限的命令。
语法:chmod [{ugoa}{+-=}{rwx}] [文件或目录]
chmod uu 表示该文件的拥有者,g 表示与该文件的拥有者属于同一个群体(group),o 表示其他以外的人,a 表示这三者皆是。
chmod ++ 表示增加权限、- 表示取消权限、= 表示唯一设定权限。
chmod rr 表示可读取,w 表示可写入,x 表示可执行,X 表示只有当该文件是个子目录或者该文件已经被设定过为可执行。
chmod a+r file1.txt将文件file1.txt设为所有人皆可读取
补充:八进制语法
chmod命令可以使用八进制数来指定权限。文件或目录的权限位是由9个权限位来控制,每三位为一组,它们分别是文件所有者(User)的读、写、执行,用户组(Group)的读、写、执行以及其它用户(Other)的读、写、执行。
| 数字 | 权限 | rwx | 二进制 |
|---|---|---|---|
| 7 | 读 + 写 + 执行 | rwx | 111 |
| 6 | 读 + 写 | rw- | 110 |
| 5 | 读 + 执行 | r-x | 101 |
| 4 | 只读 | r-- | 100 |
| 3 | 写 + 执行 | -wx | 011 |
| 2 | 只写 | -w- | 010 |
| 1 | 只执行 | --x | 001 |
| 0 | 无 | --- | 000 |
chmod abc file 其中a,b,c各为一个数字,分别表示User、Group、及Other的权限,file为指定的文件。
r=4,w=2,x=1
若要 rwx 属性则 4+2+1=7;
若要 rw- 属性则 4+2=6;
若要 r-x 属性则 4+1=5。
chmod a=rwx file和chmod 777 file效果相同
- chown
英文:change owner
说明:用于设置文件所有者和文件关联组的命令。
语法:chown user[:group] [文件或目录]
chown icecream:icecreamgroup file1.txt将文件file1.txt的拥有者设为icecream,群体的使用者icecreamgroup。
Shell基础知识
Shell 是一个用 C 语言编写的程序,它是用户使用 Linux 的桥梁。Shell 既是一种命令语言,又是一种程序设计语言。
Shell 是指一种应用程序,这个应用程序提供了一个界面,用户通过这个界面访问操作系统内核的服务。
Shell变量定义
-
临时变量
所谓临时变量是指在用户在当前登录环境生效的变量。用户登录系统后,直接在命令行上定义的变量只能在当前登录环境中使用。 -
环境变量
通过将环境变量定义在配置文件中,用户每次登录时候系统自动定义,无需在到命令行中重新定义。
/etc/profile针对系统所有用户生效,此文件应用于所有用户每次登录系统时的环境变量定义。
第一个Shell脚本
通过vi f1.sh来创建一个脚本,内容如下:
#!/bin/sh
echo "Hello Shell"
运行脚本的方式
./f1/sh
bash f1.sh
source f1.sh
变量设置规则
定义变量时应注意,变量名和等号之间不能有空格,这可能和你熟悉的所有编程语言都不一样。同时,变量名的命名须遵循如下规则:
- 命名只能使用英文字母,数字和下划线,首个字符不能以数字开头
- 中间不能有空格,可以使用下划线
_ - 不能使用标点符号
- 不能使用bash里的关键字(可用help命令查看保留关键字)
占位变量
$n n为数字,$0代表命令本身,$1~$9代表第1到第9个参数
expr命令
expr命令是一个手工命令行计数器,用于在UNIX/LINUX下求表达式变量的值,一般用于整数值,也可用于字符串。
语法:expr 表达式
表达式说明:
- 用空格隔开每个项
- 用反斜杠
\放在Shell特定的字符前面,\*表示转义符 - 对包含空格和其他特殊字符的字符串要用引号括起来
test命令
使用test命令可以对文件、字符串进行测试,一般配合控制流程语句使用:
test -d x x是否是目录
test -f x x是否是文件
test int1 -eq int2 两个整数是否相等
test int1 –ge int2 整数1大于等于整数2
test int1 –gt int2 整数1大于整数2
test int1 –le int2 整数1小于等于整数2
test int1 –lt int2 整数1小于整数2
test int1 –ne int2 整数1不等于整数2
if test -d $1 then ... else ...fi可以使用简化test -d $1 等价于 -d $1
Oracle Database
Oracle是常用的关系型数据库。关系型数据库是什么?关系型数据库,是指采用了关系模型来组织数据的数据库,其以行和列的形式存储数据,称为表。一组表组成了数据库。
安装Oracle 11g
Oracle 11g安装步骤详细图文教程
Oracle解锁SCOTT和HR账户
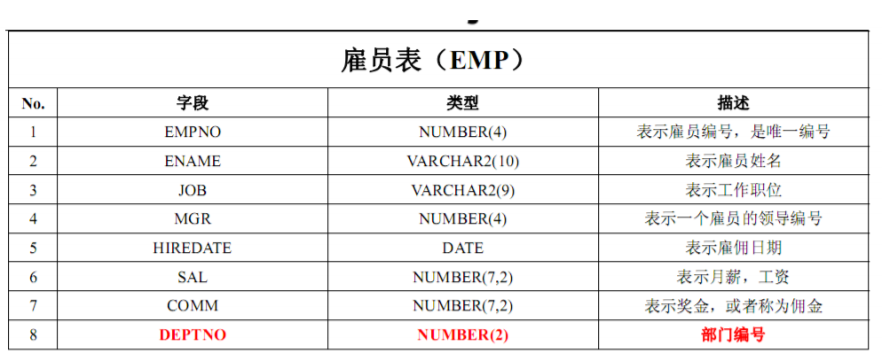
单表查询
Win+R,输入cmd,在命令行输入sqlplus回车,然后输入scott再回车,最后输入密码进入到系统。
- 显示当前用户
show user;
- 查询当前用户下的表
select * from tab;


- 查看员工表的结构
desc emp;
- 查询所有员工的信息
select * from emp;
- 查看行宽
show linesize;
- 设置行宽
set linesize 240;
- 通过列名查询
select empno,ename,job,mgr,hiredate,sal,comm,deptno from emp;
- 查询员工号 姓名 月薪
select empno,ename,sal from emp;
- 查询员工号 姓名 月薪 年薪
select empno,ename,sal,sal*12 from emp;
- 查询员工号 姓名 月薪 年薪 奖金 年收入
select empno,ename,sal,sal*12,comm,sal*12+comm from emp;
在查询结果中,会有一些行没有结果,原因是空值的影响
-
空值(null)是什么?
空值是无效的,未指定的,未知的或不可预知的值,空值不是空格或者0。
包含null的表达式的都为null,所以在第10点的查询结果中,有空值。 -
滤空函数nvl(a,b)
如果a为null则返回b,通常b为0。使用滤空函数再执行第10点的查询语句。
select empno,ename,sal,sal*12,comm,sal*12+nvl(comm,0) from emp;
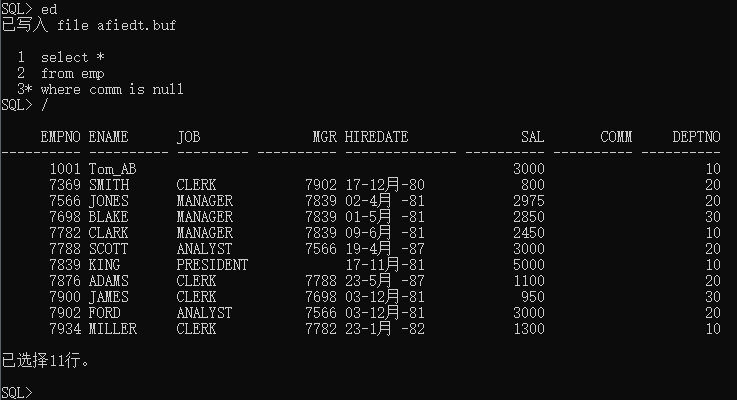
- null!=null
查询奖金为null的员工
select *
from emp
where comm=null;
查询结果为空,输入ed回车,会以记事本打开一个文件,在里面修改查询语句然后保存关闭,在查询中输入/执行上一条(指的是上一条保存或执行的)查询语句

- 设置别名的三种方式
select empno as "员工号",ename "姓名",sal 月薪 from emp;
- 基本查询语法
select * | {[distinct] column | expression [alias], ...}
from table;
column列,expression表达式,alias别名。
- distinct去掉重复记录
select deptno from emp;
select distinct deptno from emp;
select job from emp;
select distinct job from emp;
select distinct deptno,job from emp;
distinct作用于后面的所有的列,会显示组合起来不重复的结果
- concat函数
select concat('NiHao','Oracle');
SQL> select concat('NiHao','Oracle');
select concat('NiHao','Oracle')
*
第 1 行出现错误:
ORA-00923: 未找到要求的 FROM 关键字
Oracle当中有一个伪表dual
select concat('NiHao','Oracle') from dual;
select 3+2 from dual;
- 连接符 ||
要查询员工信息:XXX的薪水是XXX,即显示结果如下
SMITH的薪水是800
War的薪水是1600
select ename||'的薪水是'||sal from emp;
- 基本查询语法,加上条件查询和排序
select * | {[distinct] column | expression [alias], ...}
from table
where condition(s);
condition(s)条件,可以有多个。
- 查询10号部门的员工
select *
from emp
where deptno=10;
- 日期和字符串
日期和字符只能在单引号中出现
字符大小写敏感,日期格式敏感
默认的日期格式是DD-MON-RR
- 查询名叫KING的员工(大小写敏感)
select * from emp where ename='King';
select * from emp where ename='KING';
- 查询入职日期是1981年11月17日的员工(日期格式敏感)
select * from emp where hiredate='1981-11-17';
select * from emp where hiredate='17-11月-81';
- 修改日期格式(仅当前窗口有效)
select * from v$nls_parameters;
alter session set NLS_DATE_FORMAT='yyyy-mm-dd';
- 其他比较运算符
- between a and b在两个之间(包含边界,a<b)
- in(set) 等于集合内的一个值
- like 模糊查询('%','_'),
%代表任意个字符,_代表任意一个字符 - is null 空值
- 查询薪水1000-2000之间的员工
select *
from emp
where sal between 1000 and 2000;
- 查询10和20号部门的员工
select *
from emp
where deptno in (10,20);
- 查询不是10和20号部门的员工
select *
from emp
where deptno not in (10,20);
如果集合中有null,不能使用not in (x,null),可以使用in (x,null),但是查不出对应列为null的结果,也就是说用in (x,null)和in (x)的效果是一样的。
select *
from emp
where deptno not in (10,20,null);
- 查询名字以S开头的员工
select *
from emp
where ename like 'S%';
- 查询名字是4个字的员工
select *
from emp
where ename like '____';
- 查询名中含有下划线的员工
insert into emp(empno,ename,sal,deptno) values(1001,'Tom_AB',3000,10);
因为表中没有名字含有下划线的员工,所以先插入一条,然后再做查询
select *
from emp
where ename like '%_%';
这样写查出来的结果不是我们想要的。下划线_被认为是任意一个字符,这里我们需要转义符才能查出正确的结果。
select *
from emp
where ename like '%\_%' escape '\';
escape后面可以指定某个字符为转义符,转义符后的第一个字符将失去特殊作用(例如下划线_代表任意一个字符)。如果你想,也可以指定下划线_当做转义符。
- 逻辑运算
or逻辑或
and逻辑并
not逻辑否
select * from emp where deptno=10 or job in ('MANAGER','PRESIDENT');
select * from emp where deptno=10 and job in ('MANAGER','PRESIDENT');
select * from emp where deptno=10 and job not in ('MANAGER','PRESIDENT');
- 查询员工信息,按照月薪排序
asc升序
desc降序
如果不指定,order by默认是按升序来排
select * from emp order by sal;
select * from emp order by sal asc;
select * from emp order by sal desc;
- order by 后面+列、表达式、别名或者序号
select empno,ename,sal,sal*12 from emp order by sal*12 desc;
select empno,ename,sal,sal*12 年薪 from emp order by 年薪 desc;
select empno,ename,sal,sal*12 年薪 From emp order by 4 desc;
序号指的是第n列,第三句查询中,n=4代表的就是sal*12,别名年薪。
- 多个列的排序
select * from emp order by deptno,sal;
select * from emp order by deptno,sal desc;
order by作用域后面的所有列,先按照第一个列排序,再对后面的列进行排序,desc只作用与离他最近的列。
- 查询员工信息,按照奖金排序
select * from emp order by comm;
select * from emp order by comm desc;
null值最大,这点在排序时有很好的体现出来。但是涉及到数值排序时,null值我们一般认为是最值(可以是最大值或最小值),可以通过nulls last或者nulls first来指定null的位置。
select * from emp order by comm desc nulls last;
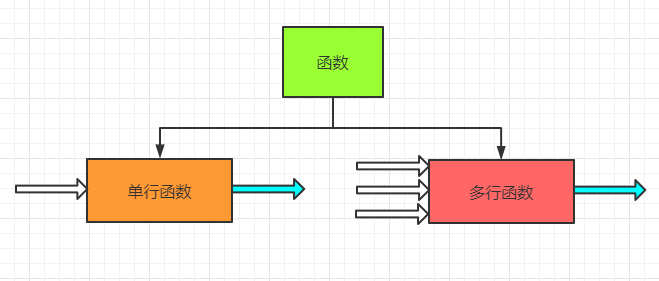
单行函数
单行函数,简单来说就是只有一行/条输入,一行/条输出的函数。
字符函数
- 字符大小写转换
select lower('NiHao java'),upper('NiHao java') from dual;
- 字符串截取
substr(a,b)从a中,第b位开始取
select substr('NIhao java',4) from dual;
substr(a,b,c)从a中,第b位开始取,取C位
select substr('NIhao java',4,5) from dual;
- 字符串字符数、字节数
length()字符数,lengthb()字节数
select length('nihao'),lengthb('nihao') from dual;
select length('你好'),lengthb('你好') from dual;
- 字符串替换
replace(a,b,c),把a中的b替换成c
select replace('nihao java','a','*') from dual;
- 字符串去除指定字符、去空格
trim('单个字符' from '待去字符串'),去掉字符串开头和末尾指定的字符
select trim('H' from 'HelHlo WordH') from dual;
trim('待去字符串'),去掉字符串开头和末尾的空格
select trim(' HelHlo WordH ') from dual;
数值函数
- 四舍五入
round(待处理数,到第n位小数)
select round(45.926,2),round(45.926,1),round(45.926,0),round(45.926,-1),round(45.926,-2) from dual;
结果如下
45.93,45.9,46,50,0
- 截断
trunc(待处理数,到第n位小数)
select trunc(45.926,2),trunc(45.926,1),trunc(45.926,0),trunc(45.926,-1),trunc(45.926,-2) from dual;
结果如下
45.92,45.9,45,40,0
查询本年的第一天
select trunc(sysdate,'year') from dual;
查询本季度的第一天
select trunc(sysdate,'q') from dual;
查询本月的第一天
select trunc(sysdate,'month') from dual;
日期函数
Oracl中的日期数据时间含有两个值:日期和时间
默认的日期格式是: DD-MON-RR
-
常用的日期函数
months_between 两个日期的相差的月数
add_months 向指定日期加上若干约束
last_day 本月的最后一天
next_day 指定日期的下一天 -
当前时间
select sysdate from dual;
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') from dual;
- 查询昨天、今天、还有明天
select (sysdate-1),sysdate,sysdate+1 from dual;
- 计算员工的工龄,天、周、月、年
select ename,hiredate,(sysdate-hiredate),(sysdate-hiredate)/7,(sysdate-hiredate)/30,(sysdate-hiredate)/365 from emp;
这种计算方式当然不是准确的,因为每个月的天数是不一样的,同理,每年的天数也不全是一样的(闰年的情况)。
- 计算员工的工龄,月
select ename,hiredate,(sysdate-hiredate)/30,months_between(sysdate,hiredate) from emp;
后者使用了函数months_between,计算结果更准确。
- 53个月后
select add_months(sysdate,53) from dual;
- 本月的最后一天
select last_day(sysdate) from dual;
- 下一个星期日
select next_day(sysdate,'星期日') from dual;
- to_char 对日期的转换
格式如下
- YYYY 2021
- YEAR TWENTY TWENTY-ONE
- MM 04
- MONTH 4月
- DAY 星期三
- DD 07
select to_char(sysdate,'YYYY/MM/DD DAY') from dual;
- 2021年4月7日 14:53:39 今天是星期三
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss "今天是"day') from dual;
转换函数
- to_char 对数字的转换
格式如下
9数字0零$美元符号L本地货币符号.小数点,千位符
- 查询员工的薪水,两位小数,千位符,本地货币代码
select to_char(sal,'L9,999.99') from emp;
- 在SQL中类似if-then-else的用法
CASE SQL99的语法:
CASE expr WHEN comparison_exp1 THEN return_expr1[
WHEN comparison_exp2 THEN return_expr2
WHEN comparison_expn THEN return_exprn
ELSE else_expr]
END
- 给员工涨工资,总裁1000,经理800,其他400(用case)
select ename,job,sal 涨前,
case job when 'PRESIDENT' then sal+1000
when 'MANAGER' then sal+800
else sal+400
end 涨后
from emp;
-
decode函数
类似java,是Oracle自己的语法:
DECODE (col | expression,search1,resut1
[,search2,result2,...,]
[,default]
) -
给员工涨工资,总裁1000,经理800,其他400(用decode)
select ename,job,sal 涨前,
decode(job,'PRESIDENT',sal+1000,'MANAGER',sal+800,sal+400) 涨后
from emp;
通用函数
- 滤空函数nvl(a,b)
如果a为null则返回b,通常b为0。使用滤空函数再执行第10点的查询语句。
select empno,ename,sal,sal*12,comm,sal*12+nvl(comm,0) from emp;
多行函数
多行函数也叫组函数,简单来说就是可以有多行/条输入,一行/条输出的函数。组函数会自动滤空。
- 工资总额
select sum(sal) from emp;
- 查询雇员总数
select count(*) from emp;
- 平均工资
select sum(sal)/count(*),avg(sal) from emp;
- 平均奖金
select sum(comm)/count(*),sum(comm)/count(comm),avg(comm) from emp;
- 组函数会自动滤空
select count(*),count(comm) from emp;
select count(*),count(nvl(comm,0)) from emp;
- 完整的基本查询语法
select * | {[distinct] column | expression [alias], ...}
from table
[where condition(s)]
[group by group_by_expression]
[having group_condition]
[order by column];
- 每个部门的平均工资
select deptno,avg(sal)
from emp
group by deptno;
使用grouo by子句,可以将表中的数据分成若干组。句式可抽象成下面的形式。
select a,组函数(x)
from emp
group by a;
在select列表中,所有未包含在组函数中的列都应该包含在group by子句中。
select a,b,c,组函数(x)
from emp
group by a,b,c;
上面的话倒过来也可以。包含在group by子句中的列不必包含在select列表中。
select a,b,c,组函数(x)
from emp
group by a,b,c,d,e;
- 非法使用组函数
select deptno,count(ename)
from emp;
执行结果如下
SQL> select deptno,count(ename)
2 from emp;
select deptno,count(ename)
*
第 1 行出现错误:
ORA-00937: 不是单组分组函数
- 多个列的分组
select deptno,job,sum(sal)
from emp
group by deptno,job
order by 1;
多个列的分组:先按照第一个列分组,如果相同,再第二个列分组,以此类推。
- 查询平均工资大于2000的部门
select deptno,avg(sal)
from emp
group by deptno
having avg(sal)>2000;
- 查询10号部门的平均工资
select deptno,avg(sal)
from emp
group by deptno
having deptno=10;
或
select deptno,avg(sal)
from emp
where deptno=10
group by deptno;
- group by增强(group by rollup)
select deptno,job,sum(sal) from emp group by rollup(deptno,job);
SQL优化原则
-
查询时用 * 效率高还是用列名效率高?
解答:用列名的查询效率高。先记结论,后续再讲为什么。
例子:select empno,ename,job,mgr,hiredate,sal,comm,deptno from emp;和select * from emp; -
where
trueandfalse和 wherefalseandtrue哪个效率更高?
解答:wheretrueandfalse效率更高。where解析条件的顺序是从右到左,因此尽量把可能为假条件的放在右边。
例子:where 2>1 and 2<1 和 where 2<1 and 2>1 -
select deptno,avg(sal) from emp group by deptno having deptno=10;和select deptno,avg(sal) from emp where deptno=10 group by deptno;,查出来的结果相同,哪种更好?
解答:尽量用where。
null值需要注意的地方
课后任务
使用HR用户
如果是在cmd里新打开sqlplus,那直接使用HR用户即可。如果是正在使用其他的用户(比如Scott),可以使用CONN HR来切换到HR用户。
练习题
- 查询工资大于12000的员工姓名和工资
select last_name||' '||first_name,salary
from employees
where salary>12000;
- 查询员工号为176的员工姓名和部门号
select last_name||' '||first_name,department_id
from employees
where employee_id=176;
- 选择工资不在5000到12000的员工姓名和工资
select last_name||' '||first_name,salary
from employees
where salary not between 5000 and 12000;
- 选择雇用时间在2008-02-01到2008-05-01之间的员工姓名,job_id和雇用时间
select last_name||' '||first_name,job_id,employee_id,hire_date
from employees
where hire_date between to_date('2008-02-01','YYYY-MM-DD') and to_date('2008-05-01','YYYY-MM-DD');
- 选择在20或50号部门工作的员工姓名和部门号
select last_name||' '||first_name,department_id
from employees
where department_id in(20,50);
- 选择在2004年雇用的员工的姓名和雇用时间
select last_name||' '||first_name,hire_date
from employees
where hire_date between to_date('2004-01-01','YYYY-MM-DD') and to_date('2004-12-31','YYYY-MM-DD');
- 选择公司中没有管理者的员工姓名及job_id
select last_name||' '||first_name,job_id
from employees
where manager_id is null;
- 选择公司中有奖金的员工姓名,工资和奖金级别
select last_name||' '||first_name,salary,commission_pct
from employees
where commission_pct is not null;
- 选择员工姓名的第三个字母是a的员工姓名
select last_name||' '||first_name
from employees
where last_name||' '||first_name like '__a%';
- 选择姓名中有字母a和e的员工姓名
select last_name||' '||first_name
from employees
where last_name||' '||first_name like '%a%' and last_name||' '||first_name like '%e%';
- 显示系统时间
select sysdate from dual;
- 查询员工号,姓名,工资,以及工资提高百分之20%后的结果(new salary)
select employee_id,last_name||' '||first_name,salary,salary*1.2 "new salary"
from employees;
- 将员工的姓名按首字母排序,并写出姓名的长度(length)
select last_name||' '||first_name,length(last_name||first_name)
from employees
order by substr(last_name||first_name,1,1);
- 查询各员工的姓名,并显示出各员工在公司工作的月份数(worked_month)
select last_name||' '||first_name,trunc(months_between(sysdate,hire_date),0)
from employees;
- 查询员工的姓名,以及在公司工作的月份数(worked_month),并按月份数降序排列
select last_name||' '||first_name,trunc(months_between(sysdate,hire_date),0)
from employees
order by 2 desc;
- 做一个查询,产生下面的结果
- <last_name> earns
monthly but wants <salary*3>
| Dream Salary |
|---|
| King earns $24000 monthly but wants $72000 |
select last_name||' earns'||to_char(salary,'$99999')||'but wants'||to_char(salary*3,'$99999') "Dream Salary"
from employees;
- 使用decode函数,按照下面的条件做一个查询
| Job_id | Grade |
|---|---|
| AD_PRES | A |
| ST_MAN | B |
| IT_PROG | C |
| SA_REP | D |
| ST_CLERK | E |
| Others | F |
| 查询的结果形式如下 | |
| Last_name | Job_id |
| ---- | ---- |
| king | AD_PRES |
select last_name,job_id,decode(job_id,
'AD_PRES','A',
'ST_MAN','B',
'IT_PROG','C',
'SA_REP ','D',
'ST_CLERK','E',
'F') Grade
from employees;
- 将第17题的查询用case再写一遍
select last_name,job_id,case job_id
when 'AD_PRES' then 'A'
when 'ST_MAN' then 'B'
when 'IT_PROG' then 'C'
when 'SA_REP ' then 'D'
when 'ST_CLERK' then 'E'
else 'F'
end Grade
from employees;
- 查询公司员工工资的最大值,最小值,平均值,总和
select max(salary),min(salary),avg(salary),sum(salary)
from employees;
- 查询各job_id的员工工资的最大值,最小值,平均值,总和
select job_id,max(salary),min(salary),avg(salary),sum(salary)
from employees
group by job_id;
- 查询各个job_id的员工人数
select job_id,count(employee_id)
from employees
group by job_id;
- 查询员工最高工资和最低工资的差距(DIFFERENCE)
select max(salary)-min(salary) "DIFFERENCE"
from employees;
- 查询各个管理者手下员工的最低工资,其中最低工资不能低于6000,没有管理者的员工不计算在内
select manager_id,min(salary)
from employees
where manager_id is not null
group by manager_id
having min(salary)>=6000;
- 查询所有部门的名字,location_id,员工数量和工资平均值
select department_name,location_id,count(employee_id),avg(salary)
from employees e join departments d on e.department_id = d.department_id
group by department_name,location_id;



