
Mali Midgard架构解析
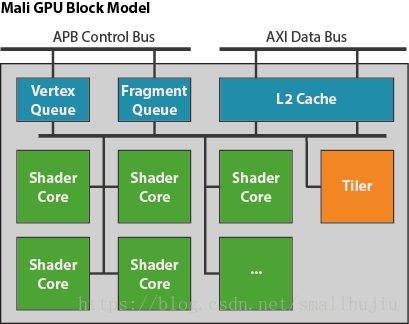
Mali-T800系列GPU采用Midgard架构,如上图所示,其中Shader Core负责执行所有的类型的计算操作,在T800的系类中最高可以拓展的16个SC。RK3399芯片包括4个SC因此简写T864。所有的计算请求被放入到请求队列中,按类型分为Vertex Queue和Fragment Queue(例如图像超分计算为Fragment),负载均衡器负责分发任务到对应的SC中。
SC包含两级的Cache L1和L2以减少带宽的使用量,其中L2的Cache与AXI总线相连,因此负责与msch / ddrc通信,L1位于SC内部由GPU实现。
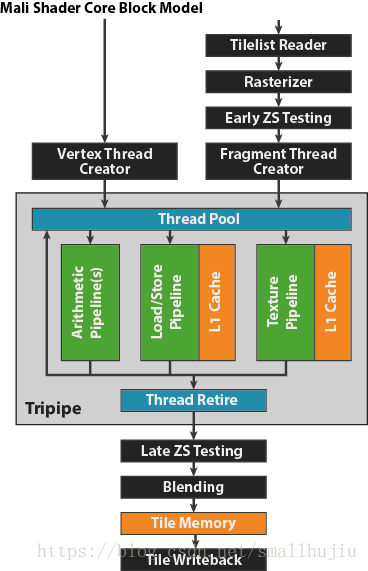
Shader Core内部包含核心的tripipe三管线架构,以及特有功能的硬件模块,例如数据光栅化模块、计算前深度和阴影检测以及计算任务发射器。
三管线架构包括三种不同类型的执行管线:Arithmetic Pipe(ARI)算术管线负责算术计算、Load/Store Pipe(LS)负责内存的读写加载、Texture Pipe(TEX)负责纹理插值的计算。其中三管线架构是大规模的硬件多线程架构(FGMT),因此在一个时钟周期内可以同时执行ARI指令、LS指令和TEX指令。
其中ARI支持SIMD技术(single instruction multiple data),一条指令可以处理128bit的数据计算,即可以处理2 x FP64, 4 x FP32, 8 x FP16数量的计算在一条指令内。
Mali T860@MP4架构图:

T864 SC包括两个ARI,因此在800M频率下单个ARI的算力为:
27.2GFLOPS / 800M / 2 = 17.4 FLOPS per pipe per clk
from: https://blog.csdn.net/smallhujiu/article/details/80928894

 浙公网安备 33010602011771号
浙公网安备 33010602011771号