

红黑树和B+树的应用场景
具体的红黑树介绍参考:红黑树原理以及插入、删除算法 附图例说明
红黑树
查找算法:遍历、二分(有序序列,二叉查找树 2^x=n树高=lgn,O(lgn))、哈希(最高效)、插值(二分的优化)、索引(搜索引擎、lucene)、BFS/DFS(图论的遍历)、平衡树、B树、B+树、红黑树(高效的查找算法)、二叉搜索树
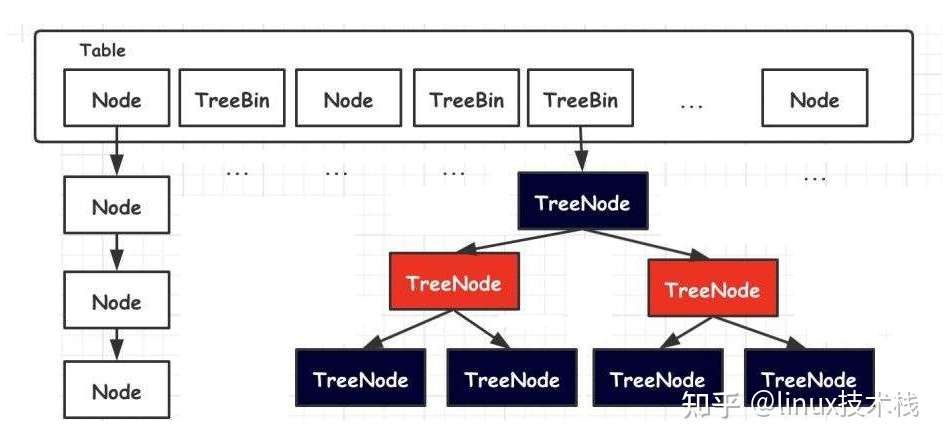
哈希:O(1) 查找、哈希冲突(即一个hash值下挂了很多点)、JDK1.8里的HashMap:链表+红黑树(处理哈希冲突,一个key对应一个计算出来的hash值,多个key对应了同一个hash值,则需要用链表来存储这多个key,链表长度大于8改用红黑树存储)
JDK1.7 HashMap:数组+链表 -> JDK1.8HashMap:链表+红黑树
AVL树:平衡二叉树,追求极致的平衡,有很多规则的理想状态(实际应用中一般不会用到)
红黑树的底层结构:特数的二叉查找树 【链表->二叉树->二叉查找树->特数的二叉查找树(自平衡的二叉查找树)】
红黑树的树高如果过大,会造成磁盘IO读写过于频繁,进而导致效率低下,因此红黑树一般都用在数据量较小,可以完全放进内存中的情况下,此时红黑树的时间复杂度比B树要低。
红黑树是一个近似平衡的二叉树,比AVL树旋转次数少,所以可以用在插入次数频繁的情况下。
应用场景:
- C++ 的 STL 中,map 和 set 是用红黑树实现的
- java 底层的 TreeMap 是用红黑树实现的
- linux 进程调度 Completely Fair Scheduler,用红黑树管理进程控制块
- epoll 在内核中的实现,用红黑树管理事件块
- nginx 中,用红黑树管理 timer
B+树
mysql 里如何查找?
遍历(暴力)、目录查找(类似索引)、键查找(hash查找)、二分(B+树的基础算法)
能做索引的数据结构有哪些?
数组、红黑树、链表、哈希、B树(B+树、B-树)
哈希:虽然效率高,但查询条件不能变,且没有部分查询和范围查询功能。
- hash(user_id) = key 一旦user_id变化,key就变化
- 联合索引:hash(user_id+name) = key 如果只传 user_id,不能支持部分索引查询和范围查找
红黑树:访问速率:内存>ssd固态硬盘>磁盘,读取磁盘次数多、读取浪费太多(磁盘一页能存16k数据)
但为什么红黑树可以用在 hashmap 中呢?因为 hashmap 存在内存里。
B、B+树都是多路查找树,一般用在数据库中做索引,因为他们分支多层数少,磁盘IO非常耗时,而大量数据都存储在磁盘中,所以要有效减少磁盘IO次数来避免频繁访问磁盘。
B+比B的优势:
B+树非叶结点存键值,叶子结点存数据,单个结点占空间少,而磁盘容量、一次读取数据大小固定,磁盘IO次数少,效率高;
叶子结点用链表存放数据,范围查找、遍历的效率比B树高
应用场景
- B树:数据库和文件系统,将相关数据尽量集中在一起,以便一次读取多个数据减少磁盘操作次数。如 mongoDB 数据库。
- B+树:数据库和文件系统。如 mysql 用 B+ 树做索引。
PS:还有一种Trie树(字典树),常用在统计和排序大量字符串上,如自动机。
红黑树的4种应用场景:虚拟内存管理、进程调度、sk_buff、epoll
参考:红黑树和B+树的应用场景
本文来自博客园,作者:aspirant,转载请注明原文链接:https://www.cnblogs.com/aspirant/p/16149400.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?
2021-04-15 老人血脂高吃什么好
2019-04-15 MAC 的ideal 修改 项目名称
2019-04-15 上海上传数据重复-sftp端口关闭
2017-04-15 linux 安装nginx -查看 linux的环境变量