

分布式系统一致性问题解决实战(阿里) 异步解耦+消息队列可作为分布式系统满足最终一致性的优秀方案
结论:
- 对于单机单库系统,数据一致性可通过关系型数据库的事务来满足,而且ACID特性中的C是指强一致性,各数据库本身都支持,而且很成熟。
- 分布式系统则需要以BASE理论作为指导,即以基本可用性和最终一致性作为目标。
- 远程RPC调用是一致性问题主要原因,异步解耦+消息队列可作为分布式系统满足最终一致性的优秀方案。
一、背景及问题描述
业务背景:
商户提交表单数据至旺铺(deco项目,以下皆称为deco),deco需要接入poi系统进行装修内容的人工审核,详细流程见下图。
问题:
店铺装修审核状态在deco系统和poi系统之间不一致,下图中1,2,3步提交流程会出现同一次提交审核流在deco系统中的装修状态为未装修,而在poi系统为审核中。同样在4,5,6步骤的审核回调过程也会有同类的状态不一致问题。两块问题都是同一技术问题,本文只以1,2,3步提交过程为例进行分析解决。

二、问题分析 1. 关系型数据事务在分布式系统中的问题
从业务中抽离出来,问题的核心原因可用下图流程模型来描述。
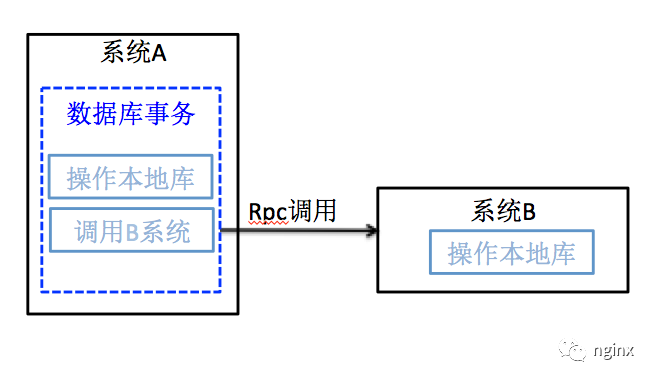
系统A的某个业务功能包含两步操作,第一步把数据写入A系统本地库,第二步远程调用系统B,这两步操作在A系统用一个数据库事务来包装。伪代码如下:
$db->begain(); // 第一步操作本地数据库 $res = $db->update($sql_a); if (!$res) { $db->rollback(); return; } // 第二步远程调用B系统 $res = $http_request->get($url_b); if ('success' != $res) { $db->rollback(); return; } $db->commit();
第一步有两种结果成功、失败,第二步则有3种结果成功、失败、超时,其中导致超时原因可能是网络中断,也可能是B系统服务异常。那么我们根据两步骤的执行结果情况来分别分析一下是否会导致A、B系统之间的数据不一致。
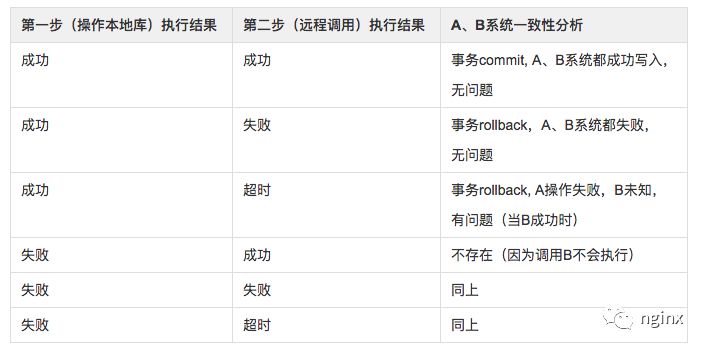
可得当第一步执行成功,第二步远程调用超时时,A系统事务会回滚,那么就发生A、B系统数据不一致的情况,A库中写入失败,但是B库中却成功写入。我们习惯于使用关系型数据库事务的ACID特性来达到一致性的目的,但是当事务中发生跨系统的调用时ACID就无效了,只从数据库层面来看,跨系统就意味着同一个业务存在多个数据副本,对应着不同的数据库实例,而且分布在不同的机器上,而关系型数据库的事务只是针对同一个库的同一个connection而言的。
2.那么怎么解决跨系统的数据一致性问题?
我们先重新认识一下什么是一致性?首先想到的是关系型数据库事务,又会想到最经典的甲给乙转钱的例子,事务的四大基本特性ACID保证了甲账户扣钱和乙账户入钱同时发生或同时不发生,其中的C特性就是指一致性,它是指数据库事务不能破坏关系数据的完整性以及业务逻辑上的一致性。在web2.0之前大部分网站或者项目都是单系统,对应底层存储也只是单数据库,所以使用数据库本身的事务特性就满足了一致性。
但是随着互联网用户和数据量的指数级增长,对于每个系统的计算能力、吞吐量以及响应速度的要求都大大提高,于是单节点服务器肯定满足不了要求,所以都在考虑拆分和系统扩展性,无论是经过水平拆分还是垂直拆分,单机系统就变成了分布式系统,分布式系统就肯定存在某节点或者网络故障的情况,之前说的事务的ACID中的强一致性就无法保证。
再回到我们的问题上来,poi系统其实就可以理解为垂直拆分出的一个微服务,deco调用poi的提交审核接口就是分布式系统之间的调用,但是deco中仍然用关系型数据库的事务来达到强一致性的目的,根据CAP理论 CAP原则 (阿里),分布式系统的一致性、可用性、分区容错性不可能同时得到满足,只能满足其中两个,而分布式系统的分区容错性都需要得到满足,所以就需要在一致性和可用性之间进行取舍。Deco的这种实现其实就是为了保证一致性,而牺牲了可用性。
而对于现在的系统而言,可用性是至关重要的必须要保证,要做到即使poi系统出现偶尔的网络故障或者超时,也尽可能不要用户的一次提交失败掉。
再来了解一个概念BASE理论,BASE理论是CAP理论的一种实现,它对分布式系统的一致性和可用性不可兼得的问题提出了一种方案,即基本可用和最终一致是目标。既然提到了强一致性和最终一致性,再介绍一下业界对一致性的分层次定义。
- 强一致 :当更新操作完成之后,任何多个后续进程或者线程的访问都会返回最新的更新过的值。这种是对用户最友好的,就是用户上一次写什么,下一次就保证能读到什么。根据 CAP 理论,这种实现需要牺牲可用性。
- 弱一致 :系统并不保证续进程或者线程的访问都会返回最新的更新过的值。系统在数据写入成功之后,不承诺立即可以读到最新写入的值,也不会具体的承诺多久之后可以读到。
- 最终一致 :弱一致性的特定形式。系统保证在没有后续更新的前提下,系统最终返回上一次更新操作的值。在没有故障发生的前提下,不一致窗口的时间主要受通信延迟,系统负载和复制副本的个数影响。DNS 是一个典型的最终一致性系统。
对上面几段分析的总结就是:关系型数据库的事务可以满足单系统的强一致性,大部分分布式系统只能把最终一致性作为追求。而我们的deco和poi系统显然也是应该追求最终一致性,因为对于poi和deco之间装修审核数据出现短时间的不一致是完全可以接受的。
三、解决方案
基于上述理论,我们可以有以下两种方案来达到可用性和最终一致性:
方案一、
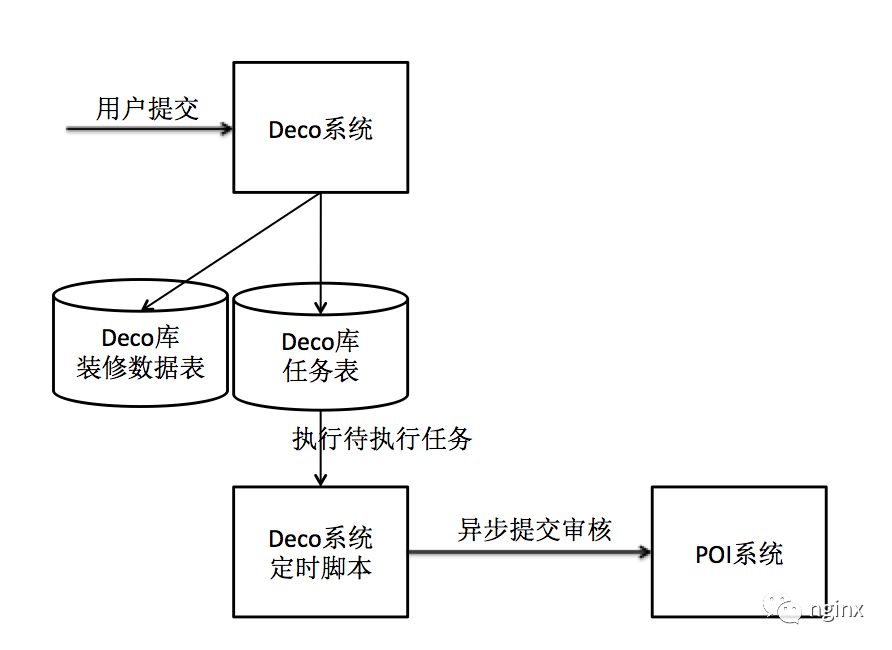
解耦,异步任务处理,由原来同步调用poi系统变为异步调用,将deco系统信息入库和调用poi创建审核任务这两个操作分开。
- deco系统收到用户请求之后先信息入库,然后在本地数据库同时新建一个任务(任务初始状态为待执行),当调用poi完成之后该任务改为已经执行,信息入库和创建任务在同一个数据库事务下。
- 后台定时脚本来执行待执行状态的任务。
- 如果异步调用poi返回失败,则需要对之前入库的信息进行回退。
- 如果异步调用poi遇到网络问题或者超时,则考虑重试机制,注意重试机制要避免重复提交,可采取在deco系统重试前确认 或者 在poi系统保证接口的幂等性。
方案二、
引入消息队列,相当于对方案一的升级版。
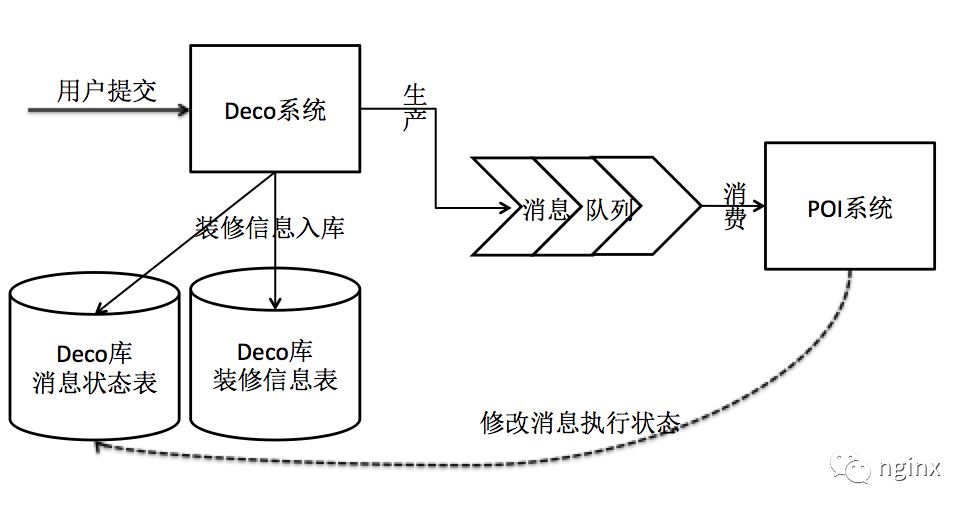
- deco系统为消息生产者,poi系统为消息消费者。
- 生产者接收到用户请求,业务数据处理入库,然后写入一条任务到消息队列,并且要新建一张消息状态表用于记录消息的执行状态,以上三个操作要在同一个本地事务中进行。其实也可以在业务表增加一个字段用来表示消息执行状态,这样有一个缺点就是生产消息和本身业务处理发生耦合,但是可以接受,因为既然放在一个事务中耦合就不可避免。
- 消费者取出一条消息,进行业务处理,处理完成后需要告诉Deco系统消息执行结果,成功或者失败,如果失败需要重新把消息写入队列,注意这里说的失败并不是业务处理的正常返回“失败”状态,而是由于一些异常原因导致业务处理没有正常完成的情况。Poi系统方需要重试时才会发送失败的通知。
- 要保证最终一致性,该方案还有一个关键点是消息队列本身的可靠性和写数据库和写消息队列事务的一致性。比如淘宝的notify的两阶段提交机制就是为了满足这一点。也可以参考其它技术文章平台有一篇技术文章《轻量级高可靠消息队列》
本文来自博客园,作者:aspirant,转载请注明原文链接:https://www.cnblogs.com/aspirant/p/11455095.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号