
HTTP/1.0和HTTP/1.1 http2.0的区别,HTTP怎么处理长连接(阿里)
HTTP1.0 HTTP 1.1主要区别
HTTP 1.0需要使用keep-alive参数来告知服务器端要建立一个长连接,而HTTP1.1默认支持长连接。
HTTP是基于TCP/IP协议的,创建一个TCP连接是需要经过三次握手的,有一定的开销,如果每次通讯都要重新建立连接的话,对性能有影响。因此最好能维持一个长连接,可以用个长连接来发多个请求。
HTTP 1.1支持只发送header信息(不带任何body信息),如果服务器认为客户端有权限请求服务器,则返回100,否则返回401。客户端如果接受到100,才开始把请求body发送到服务器。
这样当服务器返回401的时候,客户端就可以不用发送请求body了,节约了带宽。
另外HTTP还支持传送内容的一部分。这样当客户端已经有一部分的资源后,只需要跟服务器请求另外的部分资源即可。这是支持文件断点续传的基础。
现在可以web server例如tomat,设置虚拟站点是非常常见的,也即是说,web server上的多个虚拟站点可以共享同一个ip和端口。
HTTP1.0是没有host域的,HTTP1.1才支持这个参数。
HTTP1.1 HTTP 2.0主要区别
HTTP2.0使用了(类似epoll)多路复用的技术,做到同一个连接并发处理多个请求,而且并发请求的数量比HTTP1.1大了好几个数量级。
当然HTTP1.1也可以多建立几个TCP连接,来支持处理更多并发的请求,但是创建TCP连接本身也是有开销的。
TCP连接有一个预热和保护的过程,先检查数据是否传送成功,一旦成功过,则慢慢加大传输速度。因此对应瞬时并发的连接,服务器的响应就会变慢。所以最好能使用一个建立好的连接,并且这个连接可以支持瞬时并发的请求。
HTTP1.1不支持header数据的压缩,HTTP2.0使用HPACK算法对header的数据进行压缩,这样数据体积小了,在网络上传输就会更快。
意思是说,当我们对支持HTTP2.0的web server请求数据的时候,服务器会顺便把一些客户端需要的资源一起推送到客户端,免得客户端再次创建连接发送请求到服务器端获取。这种方式非常合适加载静态资源。
服务器端推送的这些资源其实存在客户端的某处地方,客户端直接从本地加载这些资源就可以了,不用走网络,速度自然是快很多的。
1.HTTP简介
web浏览器和服务器之类的交互过程必须遵守的协议.他是tcp/ip中的一个应用协议。用来协议数据交换过程和数据本身的格式.主要的有HTTP/1.0和HTTP1.1.
HTTP/1.0和HTTP/1.1都把TCP作为底层的传输协议。
HTTP客户首先发起建立与服务器TCP连接。一旦建立连接,浏览器进程和服务器进程就可以通过各自的套接字来访问TCP。如前所述,客户端套接字是客户进程和TCP连接之间的“门”,服务器端套接字是服务器进程和同一TCP连接之间的 “门”。客户往自己的套接字发送HTTP请求消息,也从自己的套接字接收HTTP响应消息。类似地,服务器从自己的套接字接收HTTP请求消息,也往自己 的套接字发送HTTP响应消息。客户或服务器一旦把某个消息送入各自的套接字,这个消息就完全落入TCP的控制之中。
TCP给HTTP提供一个可靠的数据传输服务;这意味着由客户发出的每个HTTP请求消息最终将无损地到达服务器,由服务器发出的每个HTTP响应消息最终也将无损地到达客户。我们可从中看到分层网络体系结构的一个明显优势——HTTP不必担心数据会丢失,也无需关心TCP如何从数据的丢失和错序中恢复出来的细节。这些是TCP和协议栈中更低协议层的任务。
TCP还使用一个拥塞控制机制。该机制迫使每个新的TCP连接一开始以相对缓慢的速率传输数据,然而只要网络不拥塞,每个连接可以迅速上升到相对较高的速率。这个慢速传输的初始阶段称为缓启动(slow start)。
需要注意的是,在向客户发送所请求文件的同时,服务器并没有存储关于该客户的任何状态信息。即便某个客户在几秒钟内再次请求同一个对象,服务器也不会响应说:自己刚刚给它发送了这个对象。相反,服务器重新发送这个对象,因为它已经彻底忘记早先做过什么。既然HTTP服务器不维护客户的状态信息,我们于是 说HTTP是一个无状态的协议(stateless protocol)。
2.一个完整的HTTP请求过程
HTTP事务=请求命令+响应结果

一次完整的请求过程:
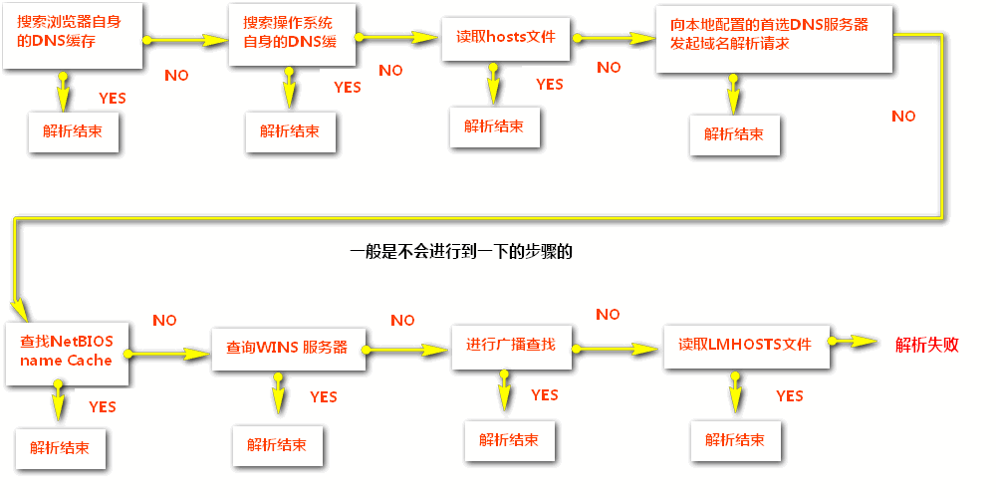
(1)域名解析
(2)建立TCP连接,三次握手
(3)Web浏览器向Web服务端发送HTTP请求报文
(4)服务器响应HTTP请求
(5)浏览器解析HTML代码,并请求HTML代码中的资源(JS,CSS,图片)(这是自动向服务器请求下载的)
(6)浏览器对页面进行渲染呈现给客户
(7)断开TCP连接

如何解析对应的IP地址?域名解析过程(注意了先走本地再走DNS)
3.HTTP/1.0和HTTP/1.1的区别
HTTP 协议老的标准是HTTP/1.0,目前最通用的标准是HTTP/1.1。
在同一个tcp的连接中可以传送多个HTTP请求和响应.
多个请求和响应可以重叠,多个请求和响应可以同时进行.
更加多的请求头和响应头(比如HTTP1.0没有host的字段).
它们最大的区别:
在 HTTP/1.0 中,大多实现为每个请求/响应交换使用新的连接。HTTP 1.0规定浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接,服务器完成请求处理后立即断开TCP连接,服务器不跟踪每个客户也不记录过去的请求。
在 HTTP/1.1 中,一个连接可用于一次或多次请求/响应交换,尽管连接可能由于各种原因被关闭。HTTP 1.1支持持久连接,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟。一个包含有许多图像的网页文件的多个请求和应答可以在一个连接中传输,但每个单独的网页文件的请求和应答仍然需要使用各自的连接。HTTP 1.1还允许客户端不用等待上一次请求结果返回,就可以发出下一次请求,但服务器端必须按照接收到客户端请求的先后顺序依次回送响应结果,以保证客户端能够区分出每次请求的响应内容,这样也显著地减少了整个下载过程所需要的时间。
举例说明:
一个包含有许多图像的网页文件中并没有包含真正的图像数据内容,而只是指明了这些图像的URL地址,当WEB浏览器访问这个网页文件时,浏览器首先要发出针对该网页文件的请求,当浏览器解析WEB服务器返回的该网页文档中的HTML内容时,发现其中的<img>图像标签后,浏览器将根据<img>标签中的src属性所指定的URL地址再次向服务器发出下载图像数据的请求。
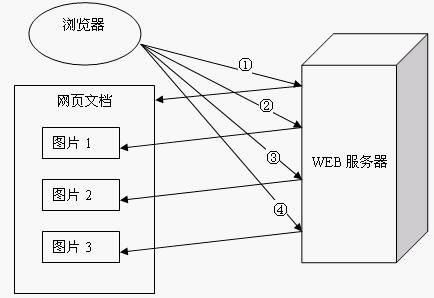
显然,访问一个包含有许多图像的网页文件的整个过程包含了多次请求和响应,每次请求和响应都需要建立一个单独的连接,每次连接只是传输一个文档和图像,上一次和下一次请求完全分离。即使图像文件都很小,但是客户端和服务器端每次建立和关闭连接却是一个相对比较费时的过程,并且会严重影响客户机和服务器的性能。当一个网页文件中包含Applet,JavaScript文件,CSS文件等内容时,也会出现类似上述的情况。
为了克服HTTP 1.0的这个缺陷,HTTP 1.1支持持久连接,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟。一个包含有许多图像的网页文件的多个请求和应答可以在一个连接中传输,但每个单独的网页文件的请求和应答仍然需要使用各自的连接。
HTTP 1.1还允许客户端不用等待上一次请求结果返回,就可以发出下一次请求,但服务器端必须按照接收到客户端请求的先后顺序依次回送响应结果,以保证客户端能够区分出每次请求的响应内容,这样也显著地减少了整个下载过程所需要的时间。
基于HTTP 1.1协议的客户机与服务器的信息交换过程,如下图所示
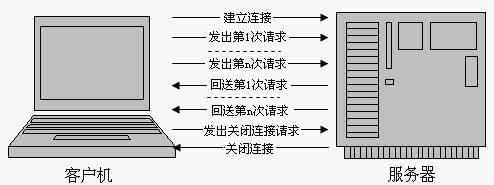
可见,HTTP 1.1在继承了HTTP 1.0优点的基础上,也克服了HTTP 1.0的性能问题。
还有哪些小的区别呢?
HTTP 1.1还通过增加更多的请求头和响应头来改进和扩充HTTP 1.0的功能。
例如,由于HTTP 1.0不支持Host请求头字段,WEB浏览器无法使用主机头名来明确表示要访问服务器上的哪个WEB站点,这样就无法使用WEB服务器在同一个IP地址和端口号上配置多个虚拟WEB站点。
在HTTP 1.1中增加Host请求头字段后,WEB浏览器可以使用主机头名来明确表示要访问服务器上的哪个WEB站点,这才实现了在一台WEB服务器上可以在同一个IP地址和端口号上使用不同的主机名来创建多个虚拟WEB站点。
HTTP 1.1的持续连接,也需要增加新的请求头来帮助实现。
例如,Connection请求头的值为Keep-Alive时,客户端通知服务器返回本次请求结果后保持连接;Connection请求头的值为close时,客户端通知服务器返回本次请求结果后关闭连接。
HTTP 1.1还提供了与身份认证、状态管理和Cache缓存等机制相关的请求头和响应头。
4.Http怎么处理长连接
基于http协议的长连接
在HTTP1.0和HTTP1.1协议中都有对长连接的支持。其中HTTP1.0需要在request中增加”Connection: keep-alive“ header才能够支持,而HTTP1.1默认支持.
http1.0请求与服务端的交互过程:
(1)客户端发出带有包含一个header:”Connection: keep-alive“的请求
(2)服务端接收到这个请求后,根据http1.0和”Connection: keep-alive“判断出这是一个长连接,就会在response的header中也增加”Connection: keep-alive“,同时不会关闭已建立的tcp连接.
(3)客户端收到服务端的response后,发现其中包含”Connection: keep-alive“,就认为是一个长连接,不关闭这个连接。并用该连接再发送request.转到(1)
http1.1请求与服务端的交互过程:
(1)客户端发出http1.1的请求
(2)服务端收到http1.1后就认为这是一个长连接,会在返回的response设置Connection: keep-alive,同时不会关闭已建立的连接.
(3)客户端收到服务端的response后,发现其中包含”Connection: keep-alive“,就认为是一个长连接,不关闭这个连接。并用该连接再发送request.转到(1)
基于http协议的长连接减少了请求,减少了建立连接的时间,但是每次交互都是由客户端发起的,客户端发送消息,服务端才能返回客户端消息。因为客户端也不知道服务端什么时候会把结果准备好,所以客户端的很多请求是多余的,仅是维持一个心跳,浪费了带宽。
栗子:下列哪些http方法对于服务端和用户端一定是安全的?(C)
A.GET
B.HEAD
C.TRACE
D.OPTIONS
E.POST
TRACE: 这个方法用于返回到达最后服务器的请求的报文,这个方法对服务器和客户端都没有什么危险。
HTTP是无状态的
也就是说,浏览器和服务器每进行一次HTTP操作,就建立一次连接,但任务结束就中断连接。如果客户端浏览器访问的某个HTML或其他类型的Web页中包含有其他的Web资源,如JavaScript文件、图像文件、CSS文件等;当浏览器每遇到这样一个Web资源,就会建立一个HTTP会话
HTTP1.1和HTTP1.0相比较而言,最大的区别就是增加了持久连接支持(貌似最新的 http1.0 可以显示的指定 keep-alive),但还是无状态的,或者说是不可以信任的。
如果浏览器或者服务器在其头信息加入了这行代码
Connection:keep-alive
TCP连接在发送后将仍然保持打开状态,于是,浏览器可以继续通过相同的连接发送请求。保持连接节省了为每个请求建立新连接所需的时间,还节约了带宽。
实现长连接要客户端和服务端都支持长连接。
如果web服务器端看到这里的值为“Keep-Alive”,或者看到请求使用的是HTTP 1.1(HTTP 1.1默认进行持久连接),它就可以利用持久连接的优点,当页面包含多个元素时(例如Applet,图片),显著地减少下载所需要的时间。要实现这一点, web服务器需要在返回给客户端HTTP头信息中发送一个Content-Length(返回信息正文的长度)头,最简单的实现方法是:先把内容写入ByteArrayOutputStream,然 后在正式写出内容之前计算它的大小
无论客户端浏览器 (Internet Explorer) 还是 Web 服务器具有较低的 KeepAlive 值,它都将是限制因素。例如,如果客户端的超时值是两分钟,而 Web 服务器的超时值是一分钟,则最大超时值是一分钟。客户端或服务器都可以是限制因素
在header中加入 --Connection:keep-alive
在HTTp协议请求和响应中加入这条就能维持长连接。
再封装HTTP消息数据体的消息应用就显的非常简单易用
Http Keep-Alive seems to be massively misunderstood. Here's a short description of how it works, under both 1.0 and 1.1
HTTP/1.0
Under HTTP 1.0, there is no official specification for how keepalive operates. It was, in essence, tacked on to an existing protocol. If the browser supports keep-alive, it adds an additional header to the request:
Connection: Keep-Alive
Then, when the server receives this request and generates a response, it also adds a header to the response:
Connection: Keep-Alive
Following this, the connection is NOT dropped, but is instead kept open. When the client sends another request, it uses the same connection. This will continue until either the client or the server decides that the conversation is over, and one of them drops the connection.
HTTP/1.1
Under HTTP 1.1, the official keepalive method is different. All connections are kept alive, unless stated otherwise with the following header:
Connection: close
The Connection: Keep-Alive header no longer has any meaning because of this.
Additionally, an optional Keep-Alive: header is described, but is so underspecified as to be meaningless. Avoid it.
Not reliable
HTTP is a stateless protocol - this means that every request is independent of every other. Keep alive doesn’t change that. Additionally, there is no guarantee that the client or the server will keep the connection open. Even in 1.1, all that is promised is that you will probably get a notice that theconnection is being closed. So keepalive is something you should not write your application to rely upon.
KeepAlive and POST
The HTTP 1.1 spec states that following the body of a POST, there are to be no additional characters. It also states that "certain" browsers may not follow this spec, putting a CRLF after the body of the POST. Mmm-hmm. As near as I can tell, most browsers follow a POSTed body with a CRLF. There are two ways of dealing with this: Disallow keepalive in the context of a POST request, or ignore CRLF on a line by itself. Most servers deal with this in the latter way, but there's no way to know how a server will handle it without testing.
Java应用
client用apache的commons-httpclient来执行method 。
用 method.setRequestHeader("Connection" , "Keep-Alive" or "close") 来控制是否保持连接。
常用的apache、resin、tomcat等都有相关的配置是否支持keep-alive。
tomcat中可以设置:maxKeepAliveRequests
The maximum number of HTTP requests which can be pipelined until the connection is closed by the server. Setting this attribute to 1 will disable HTTP/1.0 keep-alive, as well asHTTP/1.1 keep-alive and pipelining. Setting this to -1 will allow an unlimited amount of pipelined or keep-alive HTTP requests. If not specified, this attribute is set to 100.
解释1
所谓长连接指建立SOCKET连接后不管是否使用都保持连接,但安全性较差,
所谓短连接指建立SOCKET连接后发送后接收完数据后马上断开连接,一般银行都使用短连接
解释2
长连接就是指在基于tcp的通讯中,一直保持连接,不管当前是否发送或者接收数据。
而短连接就是只有在有数据传输的时候才进行连接,客户-服务器通信/传输数据完毕就关闭连接。
解释3
长连接和短连接这个概念好像只有移动的CMPP协议中提到了,其他的地方没有看到过。
通信方式
各网元之间共有两种连接方式:长连接和短连接。所谓长连接,指在一个TCP连接上可以连续发送多个数据包,在TCP连接保持期间,如果没有数据包发送,需要双方发检测包以维持此连接。短连接是指通信双方有数据交互时,就建立一个TCP连接,数据发送完成后,则断开此TCP连接,即每次TCP连接只完成一对 CMPP消息的发送。
现阶段,要求ISMG之间必须采用长连接的通信方式,建议SP与ISMG之间采用长连接的通信方式。
解释4
短连接:比如http的,只是连接、请求、关闭,过程时间较短,服务器若是一段时间内没有收到请求即可关闭连接。
长连接:有些服务需要长时间连接到服务器,比如CMPP,一般需要自己做在线维持。
最近在看“服务器推送技术”,在B/S结构中,通过某种magic使得客户端不需要通过轮询即可以得到服务端的最新信息(比如股票价格),这样可以节省大量的带宽。
poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标。如果对课程感兴趣,请大家咨询qq:908821478,咨询电话010-84505200。
HTTP是一个构建在传输层的TCP协议之上的应用层的协议,在这个层的协议,是一种网络交互需要遵守的一种协议规范。
HTTP1.0的短连接
HTTP 1.0规定浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接,服务器完成请求处理后立即断开TCP连接,服务器不跟踪每个客户也不记录过去的请求。这个过程大概可以描述为:
1、建立连接:首先DNS解析过程。如把域名变成一个ip,如果url不包含端口号,则会使用该协议的默认端口号,HTTP协议的默认端口号为80。然后三次握手建立一个TCP连接;
2、请求:连接成功后,开始向web服务器发送请求,这个请求一般是GET或POST请求。
3、应答:web服务器收到这个请求,进行处理。web服务器会把文件内容传送给响应的web浏览器。包括:HTTP头信息,体信息。
4、关闭连接:当应答结束后,web浏览器与web服务器必须四次握手断开连接,以保证其它web浏览器能够与web服务器建立连接。
HTTP1.1的长连接
但是HTTP1.1开始默认建立的是长连接,即一旦浏览器发起HTTP请求,建立的连接不会请求应答之后立刻断掉。
1、 一个复杂的具备很多HTTP资源的网页会建立多少TCP连接,如何使用这些连接?
2、 已经建立的TCP连接是否会自动断开,时间是多久?
对于第一个问题。现在浏览器都有最大并发连接数限制,应该说如果需要,就会尽量在允许范围内建立更多的TCP持久连接来处理HTTP请求,同样滴,一个TCP持久连接可以不断传输多个HTTP请求,但是如果上一个请求的响应还未收到,则不能处理下一个请求(Pipeling管道技术可以解决这个问题从而进一步提升性能),所以说很多浏览器其实都可以修改允许最大并发连接数以提升浏览网页的速度。
对于第二个问题。问题在于服务器端对于长连接的实现,特别是在对长连接的维护上。FTP协议及SMTP协议中有NOOP消息,这个就可以认为是心跳报文,但HTTP协议没有类似的消息,这样服务器端只能使用超时断开的策略来维护连接。设想超时时间非常短,那么有效空闲时间就非常短,换句话讲:一旦链路上没有数据发送,服务器端很快就关闭连接。
也就是说其实HTTP的长连接很容易在空闲后自动断开,一般来说这个时间是300s左右。
参考:HTTP/1.0和HTTP/1.1的区别,HTTP怎么处理长连接
参考:HTTP实现长连接(TTP1.1和HTTP1.0相比较而言,最大的区别就是增加了持久连接支持Connection: keep-alive)
本文来自博客园,作者:aspirant,转载请注明原文链接:https://www.cnblogs.com/aspirant/p/10833143.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号