
ArrayList继承关系分析
最近翻看ArrayList的源码,对ArrayList的继承关系做了大概梳理,记录如下!
继承关系
为了更全面了解ArrayList,我们需要首先对ArrayList的继承关系有个大概了解,ArrayList的UML图谱如下:

下面,我们根据UML图谱,自上而下逐个做个简要介绍,便于ArrayList的理解!
Iterable
这是一个支持for-each循环的接口,一共有三个方法:

1.iterator():可以获得一个Iterator对象。Iterator我们都很熟悉了,它可以根据hasNext()、next()两个方法进行循环迭代。
2.forEach():这是一个default方法,默认接收Consumer对象,通过for循环进行单对象操作。
3.spliterator():这也是一个default方法,可以得到一个Spliterator对象,支持对象的并发操作。后面我们会对Spliterator进行专门的讲解!
Collection
它是集合操作的"root interface",每个Collection就代表不同的集合类型,例如:重复集合和非重复集合、有序集合和无序集合等。JDK中没有对它进行直接的实现,只是提供了实现它的子接口,例如:Set、List等。
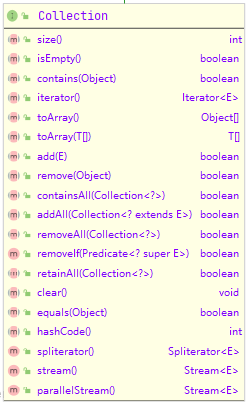
List
这是我们最熟悉的有序集合接口,它的实现类,ArrayList、LinkedList是我们最常用。它内部的方法也一目了然,不做过多介绍。

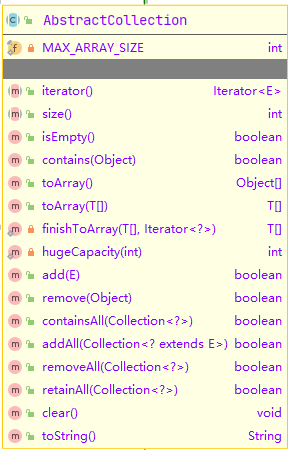
AbstractCollection
这个抽象类是对Collection接口的一个基本实现。
如果实现一个不可变集合,我们只需要继承这个类,并实现它的iterator()和size()方法,当然,iterator()方法返回的iterator对象中的hasNext()和next()方法也需要实现。
如果实现一个可变集合,项目中就必须override它的add()方法,默认该方法抛出异常UnsupportedOperationException,同时,实现iterator()方法返回的iterator对象中的hasNext()、next()以及remove()方法。
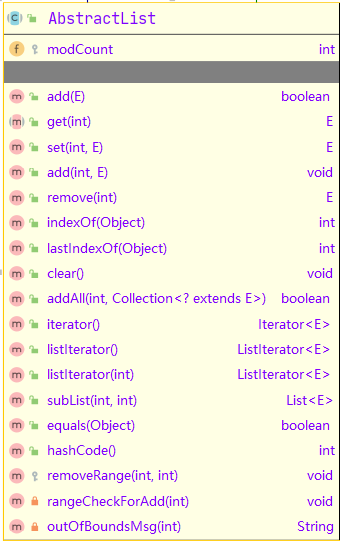
AbstractList
此类提供了List接口的基本实现,以最小化实现由“随机访问”数据存储(例如数组)支持的该接口所需的工作量。
实现不可变List集合时,继承该类,并实现其中的get()、size()方法。
实现可变List集合时,还需要实现其中的set()方法,如果集合是可变长度集合,override其中的add()和remove()方法。
重点属性modCount:
AbstractList中有个重要属性
modCount,int类型,一旦类内部结构被修改,该属性就会进行累加,,用来表示该类被修改的次数。在AbstractList的子类中,会存在与modCount向对应的另一个属性expectedModCount,子类可以通过对比两个值是否相等,来达到校验该类是否被其他线程修改的目的,该功能称为fast-fail。例如:AbstractList中add()方法都会对modCount进行累加操作,如果一个线程A在对它进行遍历add操作时,另一线程B也对它进行了add操作,那么A线程就会检测到expectedModCount与modCount不一致,从而抛出异常ConcurrentModificationException。
RandomAccess
这只是一个接口,内部没有方法,它仅作为一个标记接口存在,表示List集合下的实现支持快速随机访问功能,简单来说就是底层是数组实现的集合标识。
Serializable
序列化接口,至于接口为什么需要序列化,可以参考:对象序列化.
Cloneable
实现Cloneable接口的类,可以合法地使用Object的clone()方法对该类实例进行按字段复制,没有实现Cloneable接口的类调用Object的clone()方法时,则会导致抛出异常CloneNotSupporteddException。
这里涉及到浅克隆(shallow clone)和深克隆(deep clone)的知识,在此不做过多介绍!可参考:对象的深度复制和浅复制.
Itr
AbstractList与ArrayList内部都有一个内部类Itr,都实现了Iterator接口的hasNext()与next()方法,并将默认remove()方法重写,另外,ArrayList中还重写了forEachRemaining()方法,该方法是对未处理过的元素进行遍历。
Itr对元素遍历过程使用到了三个重要属性:cursor、lastRet、expectedModCount:
cursor:表示下一个返回元素的指针;
lastRet:最后一次返回的元素指针,没有的话,默认-1;
expectedModCount:初始化迭代器时,默认为AbstractList中的modCount值,迭代过程中,会与modCount进行比较,达到"fail-fast"效果,保证线程同步安全,不相同时,就会抛出ConcurrentModificationException异常。
ListItr
同理,AbstractList与ArrayList通过ListItr对迭代器Itr进行继承,实现了迭代效果,两则的不同点,ArrayList.ListItr比AbstractList.ListItr更加优化了。
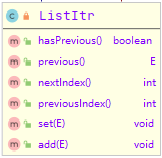
另外,ListItr除了继承Itr外,它还实现了ListIterator。相比于父类Iterator,ListIterator新增了如下方法:
hasPrevious():相对于
hasNext()方法,判断是否有前一个元素;
previous():相对于next()方法,返回前一个元素;
nextIndex():下一个元素的index值;
previousIndex():前一个元素的index值;
remove():删除当前元素;
set(E e):修改当前元素;
add(E e):新增元素;
总的来说,ListIterator使迭代器兼容向前、向后两个方向的遍历,并能够对元素进行修改、添加和删除。

SubList
这是一个支持对ArrayList局部操作的集合,从构造方法中可以看到,我们操作的是fromIndex到toIndex的parent对象,offset是迭代操作的偏移量。
SubList(AbstractList<E> parent,
int offset, int fromIndex, int toIndex) {
this.parent = parent;
this.parentOffset = fromIndex;
this.offset = offset + fromIndex;
this.size = toIndex - fromIndex;
this.modCount = ArrayList.this.modCount;
}
因为它支持对集合从fromIndex到toIndex的区段进行随机访问,因此实现了RandomAccess接口,前面我们讲过,这是一个随机访问标识。另外,我们对区段操作与ArrayList相同,所以继承ArrayList。

ArrayListSpliterator
前面我们在Itrable中提到了spliterator()方法,它可以得到一个Spliterator对象,支持并发操作。那么ArrayList中就对Spliterator进行了具体实现,实现类就是ArrayListSpliterator。
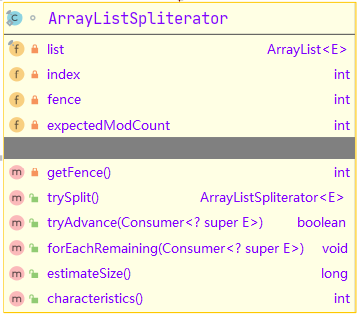
要想了解ArrayListSpliterator,我们首先来看一下它的三个字段属性含义:
// 接收到的list对象
private final ArrayList<E> list;
// 开始位置
private int index; // current index, modified on advance/split
// 结束位置(不包含)
private int fence; // -1 until used; then one past last index
// 期望的ModCount值
private int expectedModCount; // initialized when fence set
其中,我们操作的元素区间就是:[index, fence),即:[index, fence-1]。
ArrayListSpliterator中有三个重要方法:
trySplit():通过"二分法"分隔List集合;
tryAdvance():消费其中单个元素,此时index会相应+1;
forEachRemaining():遍历所有未消费的集合元素;
具体操作,我们举例说明,首先我们ArrayListSpliterator新增一个toString()方法,便于打印观察。
@Override
public String toString() {
return "[" + this.index + "," + getFence() + ")";
}
1.对trySplit()举例测试:
查看测试代码
public static void main(String[] args) {
// 初始化集合
ArrayList<Integer> list = new ArrayList<>();
for (int i = 0; i <= 10; i++) {
list.add(i);
}
// 创建ArrayListSpliterator对象
log.info("--------------创建ArrayListSpliterator对象-----------------");
ArrayListSpliterator<Integer> list_1 = new ArrayListSpliterator<>(list, 0, -1);
log.info("list_1:" + list_1); // [0,11)
// 对list_1进行分割
log.info("--------------对list_1进行分割-----------------");
ArrayListSpliterator<Integer> list_2 = list_1.trySplit();
log.info("list_1:" + list_1); // [5,11)
log.info("list_2:" + list_2); // [0,5)
// 分割流程:[0,11)(list_1) ---> [0,5)(list_2) + [5,11)(list_1)
// 对list_1和list_2进行分割
log.info("--------------对list_1和list_2进行分割-----------------");
ArrayListSpliterator<Integer> list_3 = list_1.trySplit();
ArrayListSpliterator<Integer> list_4 = list_2.trySplit();
log.info("list_1:" + list_1); // [8,11)
log.info("list_2:" + list_2); // [2,5)
log.info("list_3:" + list_3); // [5,8)
log.info("list_4:" + list_4); // [0,2)
// 分割流程:
// [0,5)(list_2) --> [0,2)(list_4) + [2,5)(list_2)
// [5,11)(list_1) --> [8,11)(list_1) + [5,8)(list_3)
// 测试集合地址
log.info("--------------测试集合地址-----------------");
log.info("(list_1.list == list_2.list) = " + (list_1.list == list_2.list));
log.info("(list_2.list == list_3.list) = " + (list_2.list == list_3.list));
log.info("(list_3.list == list_4.list) = " + (list_3.list == list_4.list));
}
打印结果:

从结果我们看到,因为Spliterator中都共享一个list,所以他们的list地址都相同,是同一个list对象。
2.对tryAdvance()和forEachRemaining()举例测试:
查看测试代码
public static void main(String[] args) {
// 初始化集合
ArrayList<Integer> list = new ArrayList<>();
for (int i = 0; i <= 10; i++) {
list.add(i);
}
// tryAdvance操作
ArrayListSpliterator<Integer> list_1 = new ArrayListSpliterator<>(list, 0, -1);
list_1.tryAdvance(t -> log.info("tryAdvance:" + t + " "));
// forEachRemaining操作
list_1.forEachRemaining(t -> log.info("forEachRemaining:" + t + " "));
// 剩余元素
log.info("list_1:" + list_1);
log.info("left size:" + list_1.estimateSize());
}
执行结果:

从结果我们看到,tryAdvance()只是对第一个元素(index=0)进行了操作,而forEachRemaining()就从第二个元素(index=1)开始对未消费的元素进行遍历输出,它的index也随着增加,最后遍历完为11,剩余的size也变为0。
好了,关于ArrayList的继承关系我们就介绍到这里,下面开始对ArrayList进行正式分析!
ArrayList分析
ArrayList的数据结构是以数组为基础构建的,每个元素都存储到了数组当中,ArrayList的size就是此数组的长度。这里我针对ArrayList中的主要功能点做个简要介绍。
数组扩容:
数组初始化时默认数组为空对象DEFAULTCAPACITY_EMPTY_ELEMENTDATA,当添加第一个元素时,对数组进行扩容操作,默认扩容大小为10(DEFAULT_CAPACITY)。
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
// minCapacity = size + 1
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
扩容操作采用Arrays.copyOf(elementData, newCapacity),其底层是数组的copy:
System.arraycopy(original, 0, copy, 0, Math.min(original.length, newLength));
ArrayList中对数据的扩容、缩容或者截取都是采用此方法操作。它是一个JVM提供的高效数组拷贝实现,至于它为什么高效,请参考这篇:System.arraycopy为什么快。
另外,在正常的扩容过程中,数组容积以1/2的长度进行增长,一直到达Integer.MAX_VALUE - 8。对于Integer.MAX_VALUE - 8的解释,JDK指出原因是一些VM会在数组中保留一些header words,导致超出内存空间而出现OutOfMemoryError。
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
数组缩容:
数组缩容操作时(例如删除),ArrayList中会找到需要移除的index,从index位置开始,将index+1后面的所有元素重新拷贝,同时,最后一位置为null,等待GC回收。
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
数组遍历:
我们通常使用到的数组遍历都是采用的iterator()方法获取Iterator对象,向后逐个遍历,其实你也可以采用listIterator()方法获得一个ListIterator对象实现向前遍历。
public ListIterator<E> listIterator() {
return new ListItr(0);
}
public ListIterator<E> listIterator(int index) {
if (index < 0 || index > size)
throw new IndexOutOfBoundsException("Index: "+index);
return new ListItr(index);
}
"Fail-Fast"机制
ArrayList中通过modCoun来实现"Fail-Fast"的错误检测机制,当多个线程对同一集合的内容进行操作时,可能就会产生异常。
在ArrayList的迭代器初始化时,会赋值expectedModCount,在迭代过程中判断modCount和expectedModCount是否一致。比如当A通过iterator去遍历某集合的过程中,线程B修改了此集合,此时就会出现modCount和expectedModCount不一致,而导致抛出ConcurrentModificationException异常。
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
集合区段操作
通过subList(int fromIndex, int toIndex)方法我们就可以获得指定索引区段的集合对象SubList。这是一个偏移量控制的集合区段,可以理解为fromIndex-offset变为0后的一个新集合,但要注意,任何对SubList对象的修改操作,都将导致原集合对象修改,因为它们使用的是同一个地址。
public List<E> subList(int fromIndex, int toIndex) {
subListRangeCheck(fromIndex, toIndex, size);
return new SubList(this, 0, fromIndex, toIndex);
}
集合分隔操作
当我们需要对集合对象进行多线程操作时,可以考虑将集合分隔,采用spliterator()方法获取到Spliterator对象,利用其trySplit()方法将其分隔开来,分别进行元素操作,分隔方式即为二分法。
同样,我们要注意,Spliterator对象的任何修改,都将导致原集合元素的修改。
public Spliterator<E> spliterator() {
return new ArrayListSpliterator<>(this, 0, -1, 0);
}
个人网址:http://wxson.cn(待开通)
-----------------------------------------------------------

