Centos 6.5 配置hadoop2.7.1
|
1 Centos 6.5 编译hadoop2.7.1
主机配置:
sudo yum install gcc gcc-c++ sudo yum install ncurses-devel
sudo yum -y install lzo-devel zlib-devel autoconf automake libtool cmake openssl-devel
编译 mvn clean package -Pdist,native -DskipTests -Dtar
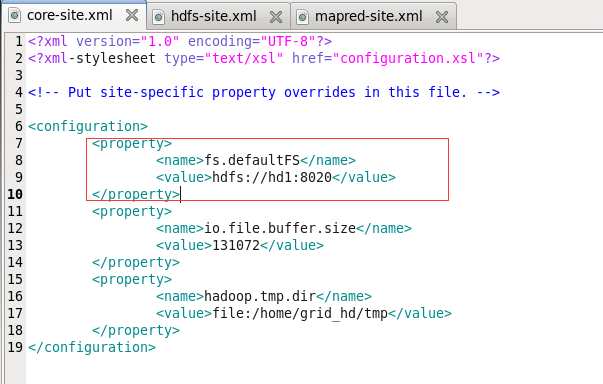
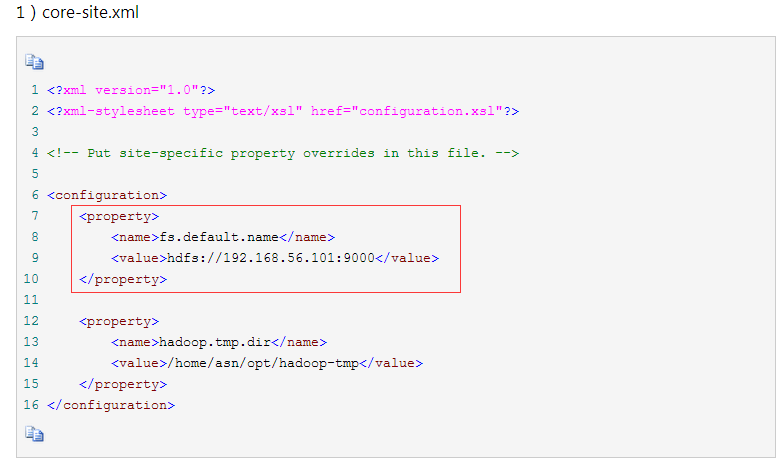
2配置hadoop2.7.1 1)core-site.xml (fs.defaultFS配置hdfs地址, DFS Master 端口)
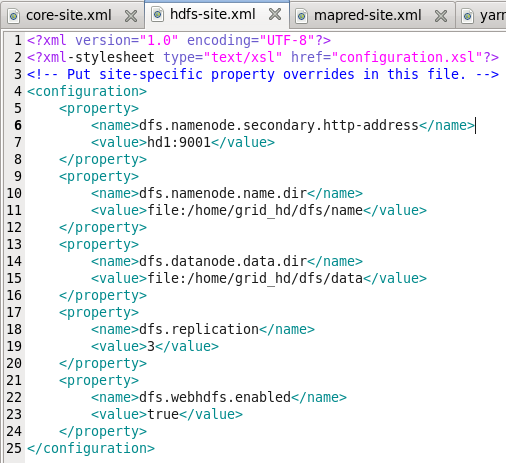
2)hdfs-site.xml
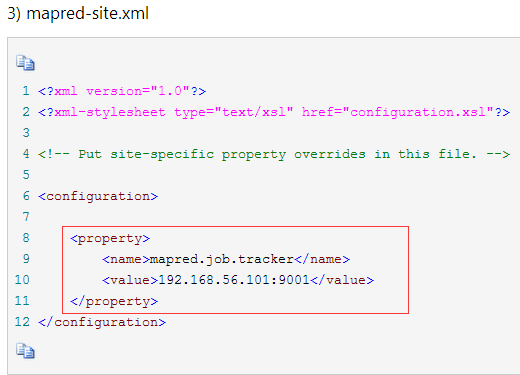
3)mapred-site.xml
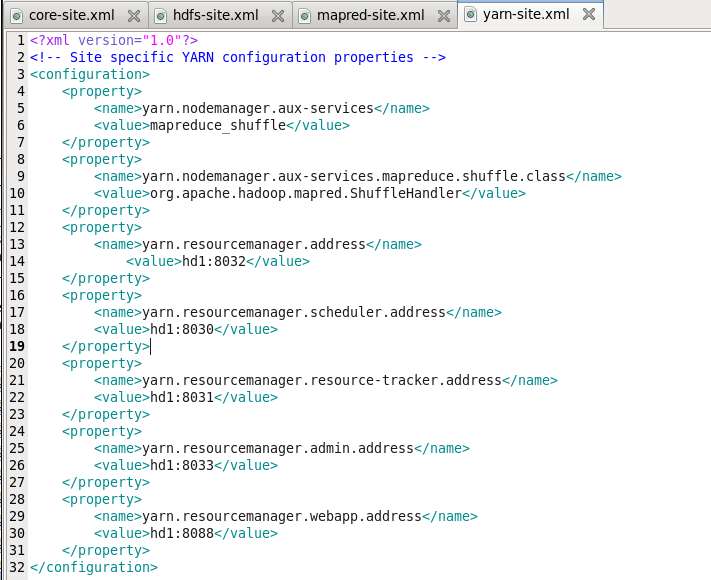
4)yarn-site.xml
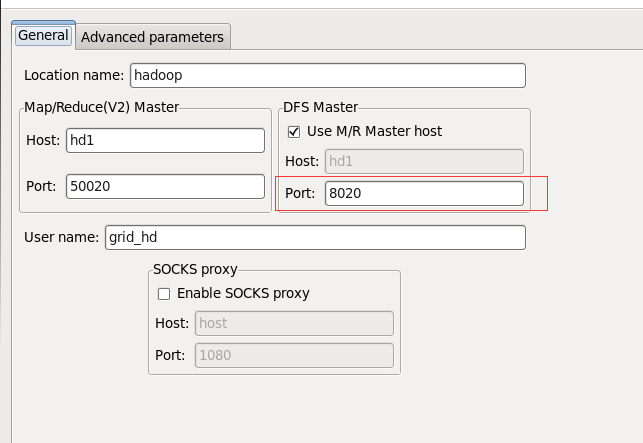
3 eclipse连接hdfs
DFS Master port 为 8020, 即hdfs://hd1:8020中配置的端口 在hadoop1中,左边是job.tracker的端口号,右边是hdfs的端口号
查看文件系统: bin/hadoop
hdfs dfs等价于hadoop fs[grid_hd@hd1 hadoop-2.7.1]$ bin/hdfs dfs Usage: hadoop fs [generic options] [-appendToFile <localsrc> ... <dst>] [-cat [-ignoreCrc] <src> ...] [-checksum <src> ...]
[-chgrp [-R] GROUP PATH...] ##改变文件的所属组 [-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...] ##改变文件的模式位 [-chown [-R] [OWNER][:[GROUP]] PATH...] ##改变文件的所有者
[-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>] [-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-moveFromLocal <localsrc> ... <dst>] [-moveToLocal <src> <localdst>]
[-count [-q] [-h] <path> ...]
[-createSnapshot <snapshotDir> [<snapshotName>]] [-deleteSnapshot <snapshotDir> <snapshotName>] [-renameSnapshot <snapshotDir> <oldName> <newName>]
[-df [-h] [<path> ...]] [-du [-s] [-h] <path> ...] [-expunge]
[-find <path> ... <expression> ...]
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] [-put [-f] [-p] [-l] <localsrc> ... <dst>]
[-getmerge [-nl] <src> <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]] [-mkdir [-p] <path> ...]
[-mv <src> ... <dst>] [-cp [-f] [-p | -p[topax]] <src> ... <dst>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...] [-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-getfacl [-R] <path>] [-getfattr [-R] {-n name | -d} [-e en] <path>]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]] [-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...] [-stat [format] <path> ...] [-tail [-f] <file>] [-test -[defsz] <path>] [-text [-ignoreCrc] <src> ...] [-touchz <path> ...] [-truncate [-w] <length> <path> ...] [-usage [cmd ...]]
Generic options supported are -conf <configuration file> specify an application configuration file 指定应用配置文件 -D <property=value> use value for given property 指定给定属性的值 -fs <local|namenode:port> specify a namenode -jt <local|resourcemanager:port> specify a ResourceManager -files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster 指定逗号分隔的文件,将被拷贝到集群 -libjars <comma separated list of jars> specify comma separated jar files to include in the classpath. -archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines.
The general command line syntax is bin/hadoop command [genericOptions] [commandOptions]
WordCount示例
运行输出: INFO - session.id is deprecated. Instead, use dfs.metrics.session-id INFO - Initializing JVM Metrics with processName=JobTracker, sessionId= WARN - No job jar file set. User classes may not be found. See Job or Job#setJar(String). INFO - Total input paths to process : 1 INFO - number of splits:1 INFO - Submitting tokens for job: job_local498662469_0001 INFO - The url to track the job: http://localhost:8080/ INFO - Running job: job_local498662469_0001 INFO - OutputCommitter set in config null INFO - File Output Committer Algorithm version is 1 INFO - OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter INFO - Waiting for map tasks INFO - Starting task: attempt_local498662469_0001_m_000000_0 INFO - File Output Committer Algorithm version is 1 INFO - Using ResourceCalculatorProcessTree : [ ] INFO - Processing split: hdfs://hd1:8020/input/file_test.txt:0+23 INFO - (EQUATOR) 0 kvi 26214396(104857584) INFO - mapreduce.task.io.sort.mb: 100 INFO - soft limit at 83886080 INFO - bufstart = 0; bufvoid = 104857600 INFO - kvstart = 26214396; length = 6553600 INFO - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer INFO - INFO - Starting flush of map output INFO - Spilling map output INFO - bufstart = 0; bufend = 39; bufvoid = 104857600 INFO - kvstart = 26214396(104857584); kvend = 26214384(104857536); length = 13/6553600 INFO - Finished spill 0 INFO - Task:attempt_local498662469_0001_m_000000_0 is done. And is in the process of committing INFO - map INFO - Task 'attempt_local498662469_0001_m_000000_0' done. INFO - Finishing task: attempt_local498662469_0001_m_000000_0 INFO - map task executor complete. INFO - Waiting for reduce tasks INFO - Starting task: attempt_local498662469_0001_r_000000_0 INFO - File Output Committer Algorithm version is 1 INFO - Using ResourceCalculatorProcessTree : [ ] INFO - Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@35cd1d03 INFO - MergerManager: memoryLimit=623902720, maxSingleShuffleLimit=155975680, mergeThreshold=411775808, ioSortFactor=10, memToMemMergeOutputsThreshold=10 INFO - attempt_local498662469_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events INFO - localfetcher#1 about to shuffle output of map attempt_local498662469_0001_m_000000_0 decomp: 37 len: 41 to MEMORY INFO - Read 37 bytes from map-output for attempt_local498662469_0001_m_000000_0 INFO - closeInMemoryFile -> map-output of size: 37, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->37 INFO - EventFetcher is interrupted.. Returning INFO - 1 / 1 copied. INFO - finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs INFO - Merging 1 sorted segments INFO - Down to the last merge-pass, with 1 segments left of total size: 29 bytes INFO - Merged 1 segments, 37 bytes to disk to satisfy reduce memory limit INFO - Merging 1 files, 41 bytes from disk INFO - Merging 0 segments, 0 bytes from memory into reduce INFO - Merging 1 sorted segments INFO - Down to the last merge-pass, with 1 segments left of total size: 29 bytes INFO - 1 / 1 copied. INFO - mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords INFO - Task:attempt_local498662469_0001_r_000000_0 is done. And is in the process of committing INFO - 1 / 1 copied. INFO - Task attempt_local498662469_0001_r_000000_0 is allowed to commit now INFO - Saved output of task 'attempt_local498662469_0001_r_000000_0' to hdfs://hd1:8020/output/count/_temporary/0/task_local498662469_0001_r_000000 INFO - reduce > reduce INFO - Task 'attempt_local498662469_0001_r_000000_0' done. INFO - Finishing task: attempt_local498662469_0001_r_000000_0 INFO - reduce task executor complete. INFO - Job job_local498662469_0001 running in uber mode : false INFO - map 100% reduce 100% INFO - Job job_local498662469_0001 completed successfully INFO - Counters: 35
File System Counters FILE: Number of bytes read=446 FILE: Number of bytes written=552703 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=46 HDFS: Number of bytes written=23 HDFS: Number of read operations=13 HDFS: Number of large read operations=0 HDFS: Number of write operations=4
Map-Reduce Framework Map input records=3 Map output records=4 Map output bytes=39 Map output materialized bytes=41 Input split bytes=100 Combine input records=4 Combine output records=3 Reduce input groups=3 Reduce shuffle bytes=41 Reduce input records=3 Reduce output records=3 Spilled Records=6 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=38 Total committed heap usage (bytes)=457703424
Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0
File Input Format Counters Bytes Read=23
File Output Format Counters Bytes Written=23
|


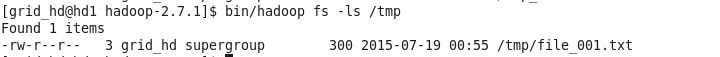

 浙公网安备 33010602011771号
浙公网安备 33010602011771号