
Machine Learning Week_9 Anomaly Detection and Recommend System
1. Anomaly Detection
I'd like to tell you about a problem called Anomaly Detection. This is a reasonably commonly usetype machine learning. And one of the interesting aspects is that it's mainly for unsupervised problem, that there's some aspects of it that are also very similar to sort of the supervised learning problem.
1.1 Algorithm
-
Training set:
Chose features
Choose features that might take on unusually large or small values in the event of an anomaly. -
Fit prarmeters
-
Given new example
Anomaly if
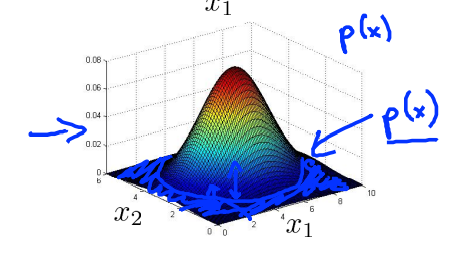
但是怎么选择
1.2 Developing and evaluating an anomaly detection system.
When developing a learning algorithm (choosing features, etc.), making decisions is much easier if we have a way of evaluating our learning algorithm.
Assume we have some labeled data, of anomalous and non-anomalous examples. (
Training set:
In anomaly detection, we fit a model
Cross validation set:
Test set:
1.2.1 For an Aircraft engines motivating example:
10000 good(normal) engines
20 flawed engines(anomalous)
Training set: 6000 good engines
CV: 2000 good engines (
Test: 2000 good engines (
Fit model
On a cross validation/test example
Give an parameter
- True positive, false positive, false negative, true negative.
- Rrecision/Recall
- F1-score
对于一系列的
where
anomaly and our algorithm correctly classified it as an anomaly.
an anomaly, but our algorithm incorrectly classified it as an anomaly.
anomaly, but our algorithm incorrectly classified it as not being anomalous.
tp = sum((predictions==1) & (yval==1));
fp = sum((predictions==1) & (yval==0));
fn = sum((predictions==0) & (yval==1));
1.3 Anomaly detection vs. supervised learning
| Anomaly detection | Supervised Learning |
|---|---|
| Very small number of positive examples |
Large number of positive and negative examples. |
| Many different “types” of anomalies. Hard for any algorithm to learn from positive examples what the anomalies look like; future anomalies may look nothing like any of the anomalous examples we've seen so far. | Enough posi-ve examples for algorithm to get a sense of what positive examples are like, future positive examples likely to be similar to ones in training set. |
| Fraud detection | Email spam classification |
| Manufacturing(e.g. aircraft engines) | Weather prediction(sunny/rainy/tec) |
| Monitoring machines in a data center | Cancer classification |
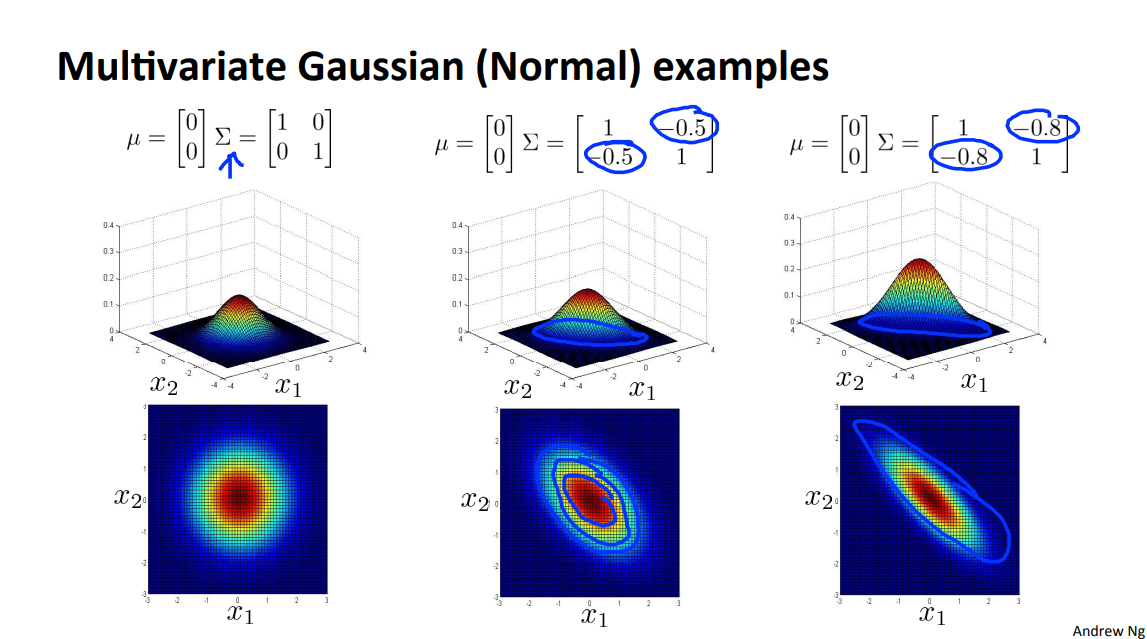
1.4 Multivariate Gaussian distribution
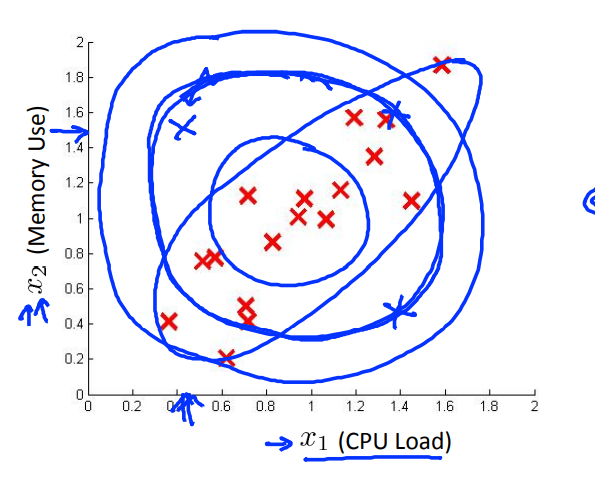
这种斜方向的分布是普通的高斯分布拟合不出来的,所以就要用到 Multivariate Gaussian distribution。
1.4.1 Algorithm
- Fit Model
- Given a new example
Flag an anomaly if
下面是一些图片,注意
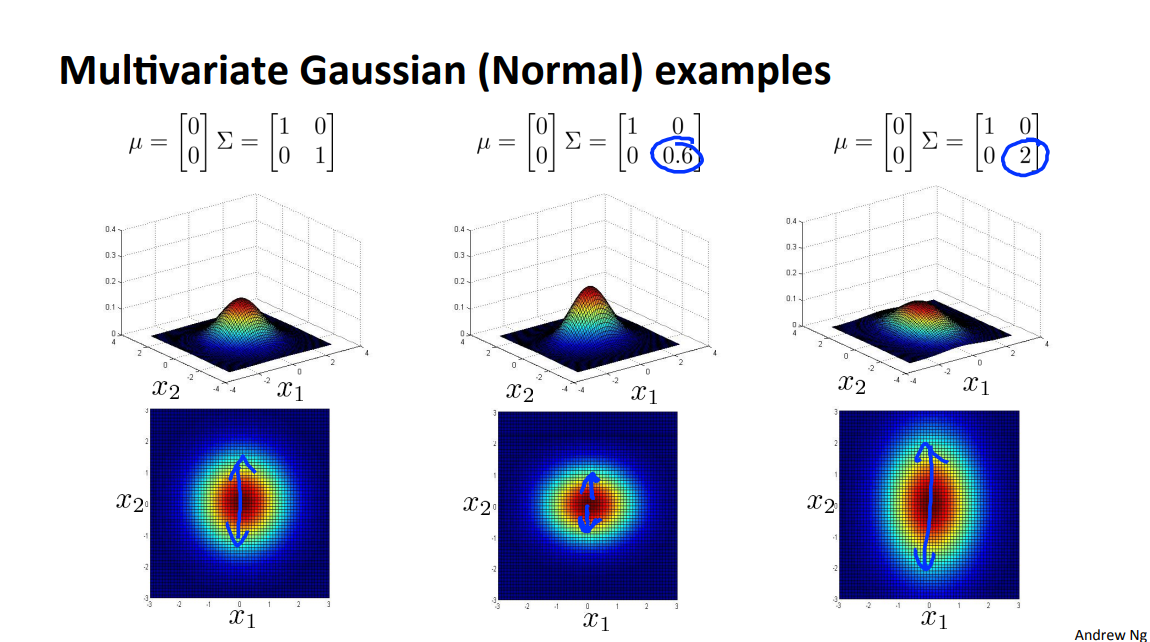
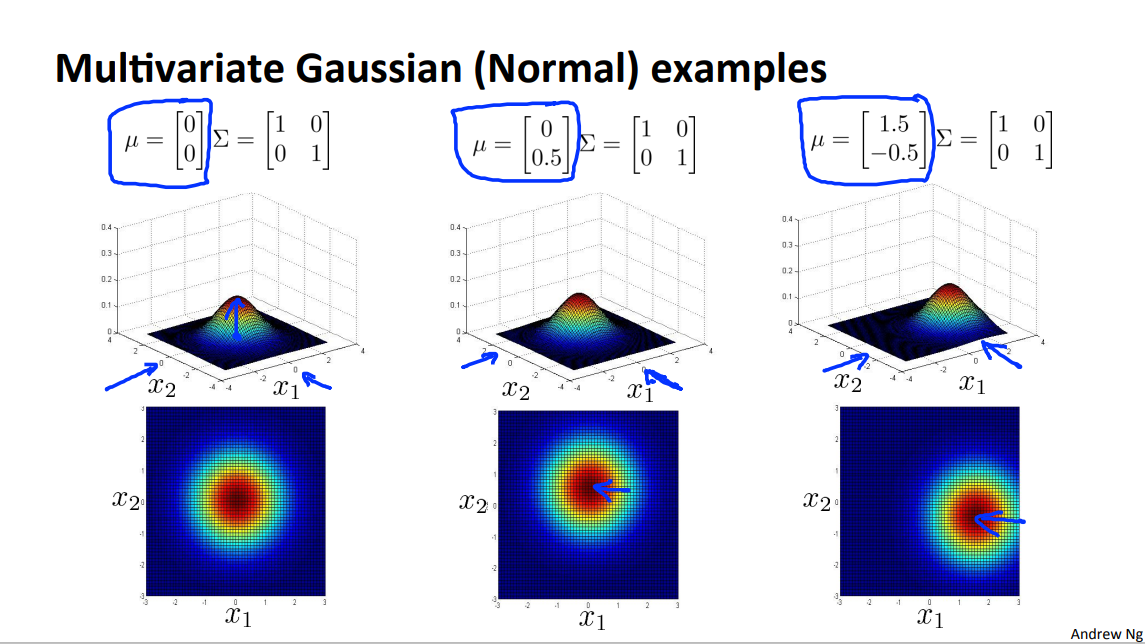

Orginal Model
-
-
Manually create features to capture anomalies where
values. -
Computationally cheaper ( alternatively, scales better to large n)
-
OK even if
Multivariate Guassian
-
-
Automatically captures correlations between features
-
Computationally more expensive
-
Must have
2 Rcommender system
2.1 Problem Formulation
In this next set of videos, I would like to tell you about recommender systems. There are two reasons, I had two motivations for why I wanted to talk about recommender systems.
The first is just that it is an important application of machine learning. Over the last few years, occasionally I visit different, you know, technology companies here in Silicon Valley and I often talk to people working on machine learning applications there and so I've asked people what are the most important applications of machine learning or what are the machine learning applications that you would most like to get an improvement in the performance of. And one of the most frequent answers I heard was that there are many groups out in Silicon Valley now, trying to build better recommender systems.
So, if you think about what the websites are like Amazon, or what Netflix or what eBay, or what iTunes Genius, made by Apple does, there are many websites or systems that try to recommend new products to use. So, Amazon recommends new books to you, Netflix try to recommend new movies to you, and so on. And these sorts of recommender systems, that look at what books you may have purchased in the past, or what movies you have rated in the past, but these are the systems that are responsible for today, a substantial fraction of Amazon's revenue and for a company like Netflix, the recommendations that they make to the users is also responsible for a substantial fraction of the movies watched by their users. And so an improvement in performance of a recommender system can have a substantial and immediate impact on the bottom line of many of these companies.
Recommender systems is kind of a funny problem, within academic machine learning so that we could go to an academic machine learning conference, the problem of recommender systems, actually receives relatively little attention, or at least it's sort of a smaller fraction of what goes on within Academia. But if you look at what's happening, many technology companies, the ability to build these systems seems to be a high priority for many companies. And that's one of the reasons why I want to talk about them in this class.
The second reason that I want to talk about recommender systems is that as we approach the last few sets of videos of this class I wanted to talk about a few of the big ideas in machine learning and share with you, you know, some of the big ideas in machine learning. And we've already seen in this class that features are important for machine learning, the features you choose will have a big effect on the performance of your learning algorithm. So there's this big idea in machine learning, which is that for some problems, maybe not all problems, but some problems, there are** algorithms that can try to automatically learn a good set of features for you.** So rather than trying to hand design, or hand code the features, which is mostly what we've been doing so far, there are a few settings where you might be able to have an algorithm, just to learn what feature to use, and the recommender systems is just one example of that sort of setting. There are many others, but engraved through recommender systems, will be able to go a little bit into this idea of learning the features and you'll be able to see at least one example of this, I think, big idea in machine learning as well.
2.2
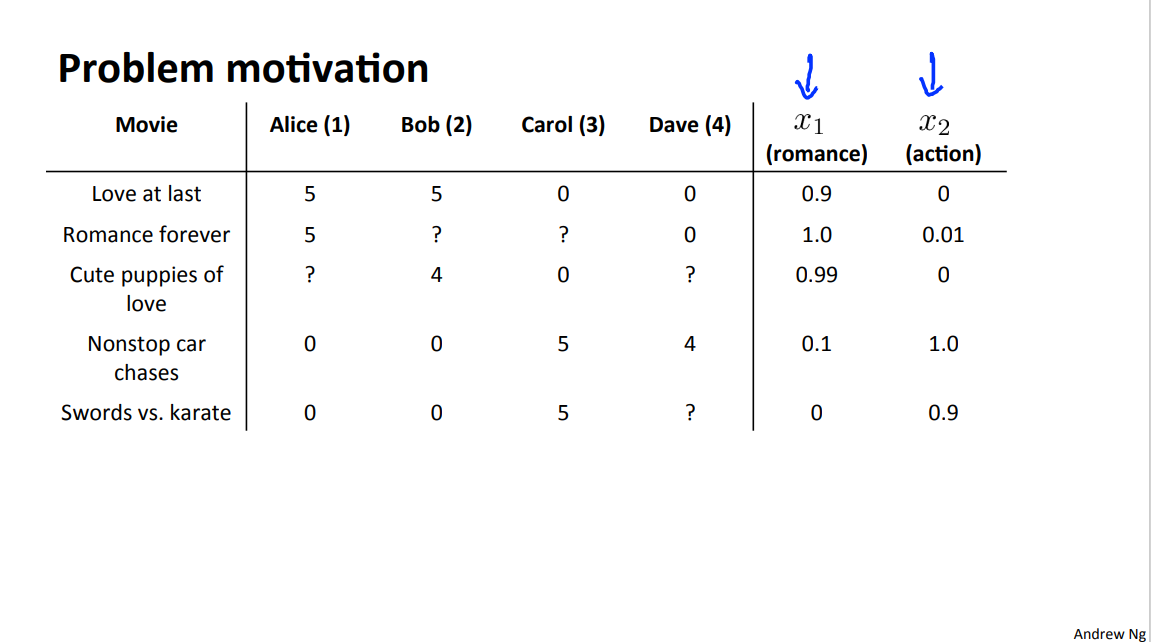
For user j movie i, predicted rating:
2.2.1 Optimization objective:
- To learn
只用用户评价过的电影来计算代价函数,
- To learn
- Given
- Given
Collaborative filtering optimization objective
Minimizing
Collaborative filtering algorithm
- Initialize
- Minimize
- For a user with parameters
J = (1/2) * sum(sum(((X*Theta' - Y).^2) .* R)) + (lambda/2)*sum(sum(Theta.^2)) + (lambda/2)*sum(sum(X.^2));
X_grad = (Theta' * ((Theta * X' - Y').* R'))' + lambda * X;
Theta_grad = (X' * ((X * Theta' - Y).* R ))' + lambda * Theta;
Reference
Andrew NG. Coursera Machine Learning Deep Learning. WEEK9.
文章会随时改动,要到博客园里看偶。一些网站会爬取本文章,但是可能会有出入。公式很难敲泪目。
转载请注明出处哦( ̄︶ ̄)↗
https://www.cnblogs.com/asmurmur/
大模型时代,文字创作已死。2025年全面停更了,世界不需要知识分享。
如果我的工作对您有帮助,您想回馈一些东西,你可以考虑通过分享这篇文章来支持我。我非常感谢您的支持,真的。谢谢!
作者:Dba_sys (Jarmony)
转载以及引用请注明原文链接:https://www.cnblogs.com/asmurmur/p/15678906.html
本博客所有文章除特别声明外,均采用CC 署名-非商业使用-相同方式共享 许可协议。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律