
Hadoop的MapReduce的插件使用
一、下载hadoop-eclipse-plugin-2.7.3.jar插件放到eclipse的plugins的目录下
二、把Window编译后的hadoop的文件放到 hadoop的bin目录下

三、添加环境变量的支持
HADOOP_HOME=e:hadoop/hadoop-2.7.7
Path=%HADOOP_HOME%/bin;%HADOOP_HOME%/sbin; 都配置进去
四、在属性里加hadoop
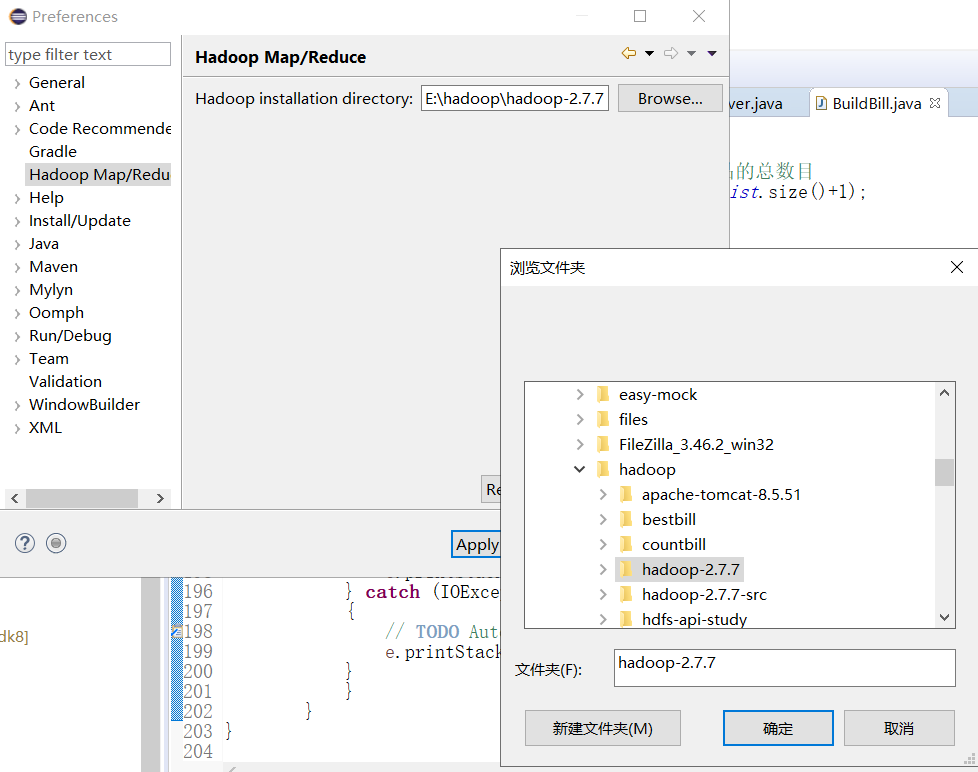
切换到Map/Reduce视图

点New Hadoop Location添加新hadoop连接
五、开发完了之后 都是直接把项目打包 rz到linux上去执行,HDFS必须开放一下权限,配置hdfs-site.xml
<property> <name>dfs.permission</name> <value>false<alue> </property>
六、项目实例
荆州市洪湖市万全镇张当村共有300户居民 因疫情原因隔离在家 现在要求代购下面的商品
随机构造一些商品 数量随机
1.洗漱用品 脸盆、杯子、牙刷和牙膏、毛巾、肥皂(洗衣服的)以及皂盒、洗发水和护发素、沐浴液...
2.床上用品 比如枕头、枕套、枕巾、被子、被套、棉被、毯子、床垫、凉席等。
3.家用电器 比如电磁炉、电饭煲、吹风机、电水壶、豆浆机、台灯等。
4.厨房用品 比如锅、碗、瓢、盆、灶、所有的厨具,柴、米、油、盐、酱、醋
代购员需要到超市购买 以下的商品 但是统计问题非常困难 需要我们的的帮助
项目 1.生成模拟的数据 bestbill
import java.io.BufferedWriter; import java.io.File; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.OutputStreamWriter; import java.io.UnsupportedEncodingException; import java.util.ArrayList; import java.util.List; import java.util.Random; /** * 300户 每户都会有一个清单文件 * 商品是随机 数量也是随机 * 洗漱用品 脸盆、杯子、牙刷和牙膏、毛巾、肥皂(洗衣服的)以及皂盒、洗发水和护发素、沐浴液 [1-5之间] * 床上用品 比如枕头、枕套、枕巾、被子、被套、棉被、毯子、床垫、凉席 [0 1之间] * 家用电器 比如电磁炉、电饭煲、吹风机、电水壶、豆浆机、台灯等 [1-3之间] * 厨房用品 比如锅、碗、瓢、盆、灶 [1-2 之间] * 柴、米、油、盐、酱、醋 [1-6之间] * 要生成300个文件 命名规则 1-300来表示 * @author Administrator * */ public class BuildBill { private static Random random=new Random(); //要还是不要 private static List<String> washList=new ArrayList<>(); private static List<String> bedList=new ArrayList<>(); private static List<String> homeList=new ArrayList<>(); private static List<String> kitchenList=new ArrayList<>(); private static List<String> useList=new ArrayList<>(); static{ washList.add("脸盆"); washList.add("杯子"); washList.add("牙刷"); washList.add("牙膏"); washList.add("毛巾"); washList.add("肥皂"); washList.add("皂盒"); washList.add("洗发水"); washList.add("护发素"); washList.add("沐浴液"); /////////////////////////////// bedList.add("枕头"); bedList.add("枕套"); bedList.add("枕巾"); bedList.add("被子"); bedList.add("被套"); bedList.add("棉被"); bedList.add("毯子"); bedList.add("床垫"); bedList.add("凉席"); ////////////////////////////// homeList.add("电磁炉"); homeList.add("电饭煲"); homeList.add("吹风机"); homeList.add("电水壶"); homeList.add("豆浆机"); homeList.add("电磁炉"); homeList.add("台灯"); ////////////////////////// kitchenList.add("锅"); kitchenList.add("碗"); kitchenList.add("瓢"); kitchenList.add("盆"); kitchenList.add("灶 "); //////////////////////// useList.add("米"); useList.add("油"); useList.add("盐"); useList.add("酱"); useList.add("醋"); } //确定是否需要 1/2 private static boolean iswant() { int num=random.nextInt(1000); if(num%2==0) { return true; } else { return false; } } /** * 表示我要几个,返回一个小于sum的随机数 * @param sum * @return */ private static int wantNum(int sum) { return random.nextInt(sum); } public static void main(String[] args) { for(int i=1;i<=300;i++) //循环三百次,生成三百个清单 { try { //字节流 FileOutputStream out=new FileOutputStream(new File("E:\\tmp\\"+i+".txt")); //转换流 可以将字节流转换字符流 设定编码格式 //字符流 BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(out,"UTF-8")); boolean iswant1=iswant();//先确定是否需要 if(iswant1) { //我要几个 不能超过该类商品的总数目 int wantNum = wantNum(washList.size()+1); //3 for(int j=0;j<wantNum;j++) { String product=washList.get(random.nextInt(washList.size()));//从列表里随机获取一个商品 writer.write(product+"\t"+(random.nextInt(5)+1)); writer.newLine(); } } boolean iswant2=iswant(); if(iswant2) { //我要几个 不能超过该类商品的总数目 int wantNum = wantNum(bedList.size()+1); //3 for(int j=0;j<wantNum;j++) { String product=bedList.get(random.nextInt(bedList.size())); writer.write(product+"\t"+(random.nextInt(1)+1)); writer.newLine(); } } boolean iswant3=iswant(); if(iswant3) { //我要几个 不能超过该类商品的总数目 int wantNum = wantNum(homeList.size()+1); //3 for(int j=0;j<wantNum;j++) { String product=homeList.get(random.nextInt(homeList.size())); writer.write(product+"\t"+(random.nextInt(3)+1)); writer.newLine(); } } boolean iswant4=iswant(); if(iswant4) { //我要几个 不能超过该类商品的总数目 int wantNum = wantNum(kitchenList.size()+1); //3 for(int j=0;j<wantNum;j++) { String product=kitchenList.get(random.nextInt(kitchenList.size())); writer.write(product+"\t"+(random.nextInt(2)+1)); writer.newLine(); } } boolean iswant5=iswant(); if(iswant5) { //我要几个 不能超过该类商品的总数目 int wantNum = wantNum(useList.size()+1); //3 for(int j=0;j<wantNum;j++) { String product=useList.get(random.nextInt(useList.size())); writer.write(product+"\t"+(random.nextInt(6)+1)); writer.newLine(); } } writer.flush(); writer.close(); } catch (FileNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (UnsupportedEncodingException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } }
先给hdfs中的文件加权限
hadoop fs -chmod 777 /upload
上传生成的300个数据文件到hdfs的/upload

项目 2.MapReduce去统计 countbill
右键新建项目-->other-->选中新建Map/Reduce 项目
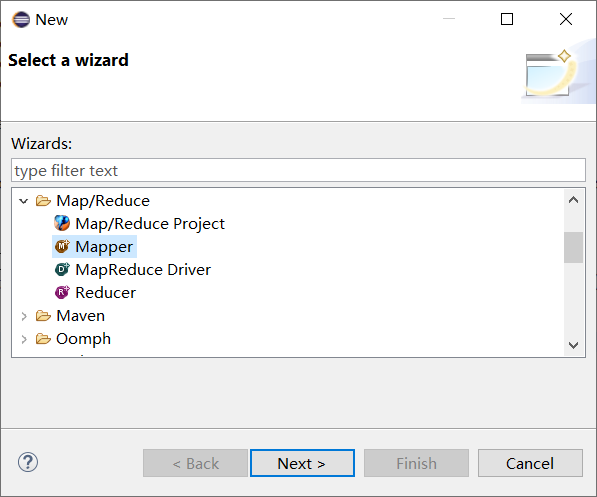
右键项目新建Mapper类
import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class BillMapper extends Mapper<LongWritable, Text, Text, IntWritable> { public void map(LongWritable ikey, Text ivalue, Context context) throws IOException, InterruptedException { //读取一行 String line = ivalue.toString(); String[] words=line.split("\t"); context.write(new Text(words[0]),new IntWritable(Integer.parseInt(words[1]))); } }
右键项目新建Reduce类
import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class BillReducer extends Reducer<Text, IntWritable, Text, IntWritable> { //盐 2 //油 2 //油 3 //油 [2,3] //盐 [2] public void reduce(Text _key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { // process values // process values int sum=0; for (IntWritable val : values) { int i = val.get(); sum+=i; } context.write(_key,new IntWritable(sum)); } }
右键项目新建Driver类
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class BillDriver { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.set("fs.defaultFS","hdfs://hdp01:9000"); Job job = Job.getInstance(conf, "BillDriver"); job.setJarByClass(BillDriver.class); // TODO: specify a mapper job.setMapperClass(BillMapper.class); // TODO: specify a reducer job.setReducerClass(BillReducer.class); //如果当前 reducer的key和Map的key是一样 可以不用写MapOutputKeyClass //如果当前 reducer的value和Map的value是一样 可以不用谢MapOutputValueClass // TODO: specify output types job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // TODO: specify input and output DIRECTORIES (not files) //执行的时候 要开启 start-yarn.sh yarn框架打开 FileInputFormat.setInputPaths(job, new Path("/upload")); //输出的结果一定这个文件夹是不存在的 FileOutputFormat.setOutputPath(job, new Path("/out/")); if (!job.waitForCompletion(true)) return; } }
直接在Driver类右键运行选中Run On Hadoop


 浙公网安备 33010602011771号
浙公网安备 33010602011771号