

Hadoop的MapReducer初步学习
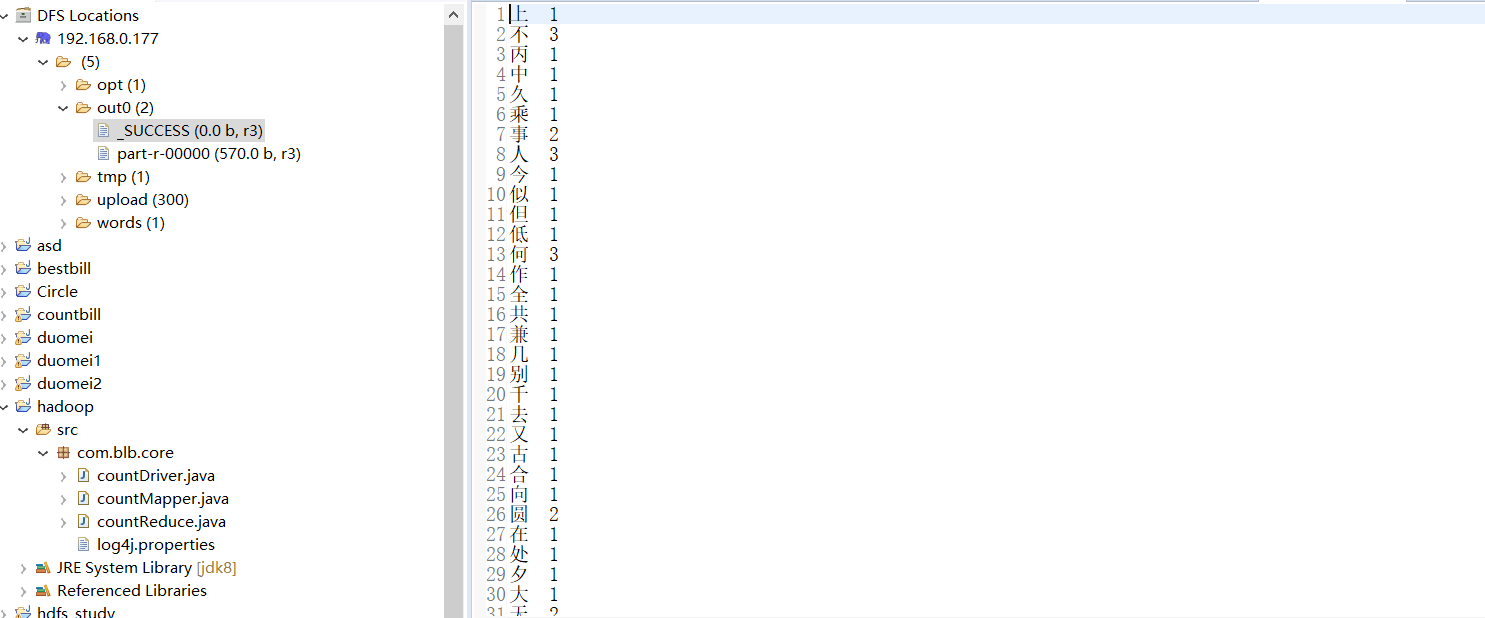
统计一段文字每个字的个数
丙辰中秋,欢饮达旦,大醉,作此篇,兼怀子由。
明月几时有?把酒问青天。不知天上宫阙,今夕是何年。我欲乘风归去,
又恐琼楼玉宇,高处不胜寒。起舞弄清影,何似在人间。
转朱阁,低绮户,照无眠。不应有恨,何事长向别时圆?人有悲欢离合,
月有阴晴圆缺,此事古难全。但愿人长久,千里共婵娟。
一、导入需要的jar包
commons文件夹下的所有的jar包
HDFS文件夹下的所有的jar包
mapreduce文件下的所有jar包
yarn文件夹下的所有的jar包
二、Map类
1.Map类会输出成一个文件 temp.html
Map类 规范 必须得 继承Mapper类 并且重写mapper方法
2.Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
KEYIN :表示我们当前读取一个文件[qqq.txt] 读到多少个字节了 数量词
VALUEIN :表示我们当前读的是文件的多少行 逐行读取 表示我们读取的一行文字
KEYOUT: 我们执行MAPPER之后 写入到文件中KEY的类型
VALUEOUT :我们执行MAPPER之后 写入到文件中VALUE的类型
3.在我们用MAPREDUCE编程的时候 MAPREDUCE有一套自己的数据类型
字符串 Text 提供Java的数据类型可以和MapReduce的类型做一个数据转换
整数 IntWritable ShortWritable LongWritbale
浮点数 FloatWritable DoubleWritable
字符串类型 Text Text.toString转换为字符串 new Text("") 把字符串转换为Text
整数类型 IntWritable get() 转换为int new IntWritable(1) 把Java类型转换为MapReduce的类型
4.Mapper阶段 产生一个临时文件,Reduce 读取Mapper生成的那个临时文件
import java.io.IOException; import java.util.ArrayList; import java.util.List; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class countMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private static List<String> bill=new ArrayList<>(); static { //初始化快只会执行一次 bill.add("。"); bill.add(","); bill.add("?"); }//提前加入除汉字外的标点字符 public void map(LongWritable ikey, Text ivalue, Mapper<LongWritable,Text,Text,IntWritable>.Context context) throws IOException, InterruptedException { String line=ivalue.toString();//读取文件的每一行数据 //明月几时有?把酒问青天。不知天上宫阙,今夕是何年。我欲乘风归去 char[] cs=line.toCharArray();//把每个字拆开 for(char c:cs) { if(!bill.contains(c+"")) //把每个新数据加写到临时文件中 { //key value //明 1 //月 1 //几 1 //时 1 //有 1 context.write(new Text(c+""), new IntWritable(1)); } } } }
三、Reducer类
Reduce类 规范 必须得 继承Reducer类 并且重写Reducer方法
Reducer会把我们Mapper执行后的那个临时文件 作为他的输入,使用之后会把这个临时文件给删除掉
Reducer<Text,IntWritable, Text,IntWritable>
KEYIN Text
VALUEIN IntWritbale
KEYOUT Text :我们Reduce之后 这个文件中内容的 Key是什么
VALUEOUT IntWritable :这个文件中内容Value是什么
import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class countReduce extends Reducer<Text,IntWritable,Text,IntWritable>{ @Override protected void reduce(Text key,Iterable<IntWritable> values,Reducer<Text,IntWritable,Text,IntWritable>.Context context)throws IOException, InterruptedException{ //Reduce获取数据的时候 当前我们Mapper类生成的临时文件 中的所有的key会做一个合并处理 //Reduce获取的数据应该Mapper类执行后的结果 //把会结果自动合并 把KEY值会自动合并 把VALUE放到一个List集合中 //明 1 //明 1 //明 1 //明 1 //明 [1,1,1,1] 预处理 Reduce获取结果的时候 数据已经被预处理过了 int sum=0; for(IntWritable value:values) { sum+=value.get(); } context.write(key, new IntWritable(sum)); } }
四、Driver类
Driver这个类 用来执行一个任务 Job
任务=Mapper+Reduce+HDFS把他们3者 关联起来
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class countDriver { public static void main(String[] args) { Configuration conf=new Configuration(); conf.set("fs.defaultFS","hdfs://192.168.0.177:9000"); try { Job job=Job.getInstance(conf); job.setJarByClass(countDriver.class);//给当前任务取一个名称 job.setMapperClass(countMapper.class);//当前的任务Mapper类是谁 job.setMapOutputKeyClass(Text.class);//Mapper任务输出的文件的Key值类型 job.setMapOutputValueClass(IntWritable.class);//Mapper任务输出端文件的Value值类型 job.setReducerClass(countReduce.class);//当前任务的Reducer类是谁 job.setOutputKeyClass(Text.class);//Reducer任务输出文件的Key值类型 job.setMapOutputValueClass(IntWritable.class);//Reducer任务输出的文件的Value值类型 FileInputFormat.setInputPaths(job, new Path("/words"));//关联HDFS文件 HDFS文件的绝对路径 //输入的路径是文件夹 把这个文件夹下面的所有文件 都执行一遍 FileOutputFormat.setOutputPath(job, new Path("/out/"));//最终要有一个结果 我最终计算完成生成的结果存放在HDFS上的哪里 //Mapper执行的后的结果是一个临时文件 这个文件存放在本地 //Reducer执行后的结果自动的上传到HDFS之上 并且还会把Mapper执行后的结果给删除掉 job.waitForCompletion(true); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (ClassNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
五、运行
1.导出成jar包
右键项目-->export-->java-->JAR file
2.上传到虚拟机
3.yarn框架 要开启
start-yarn.sh
4.hadoop jar jar包名称 主类[带main方法的那个类]
hadoop jar count.jar com.blb.core.countDriver

 浙公网安备 33010602011771号
浙公网安备 33010602011771号