MySQL——3、索引结构
1.1 索引结构
1.1.1 Mysql索引为什么不用红黑树或者二叉排序树?
根据树的高度有关,B+树是一棵多路搜索树可以降低树的高度,提高查找效率
如果要存储1万条数据,B+树只有一两层,而红黑树有几十层,直接影响数据库查询性能
理解:
答:这个问题是数据结构对比问题,树的查询时间跟树的高度有关,B+树是一棵多路搜索树可以降低树的高度,提高查找效率
考虑到极端情况下,每次插入的数据都比上一次插入的数据大,那么用平衡二叉树就会以线性方式进行存储,时间复杂度为O (n)。 数据量很大时,在mysql中一张表存储百万条数据是很正常的一件事,这样会导致树的深度更深,mysql读取时消耗大量io。
而红黑树(Red Black Tree)是一种自平衡二叉查找树。
1.1.2 B+树的多链路查找
描述多链路查找的查找流程:多链路查找,指的是树往下有多个子节点,这个图就有三条链路
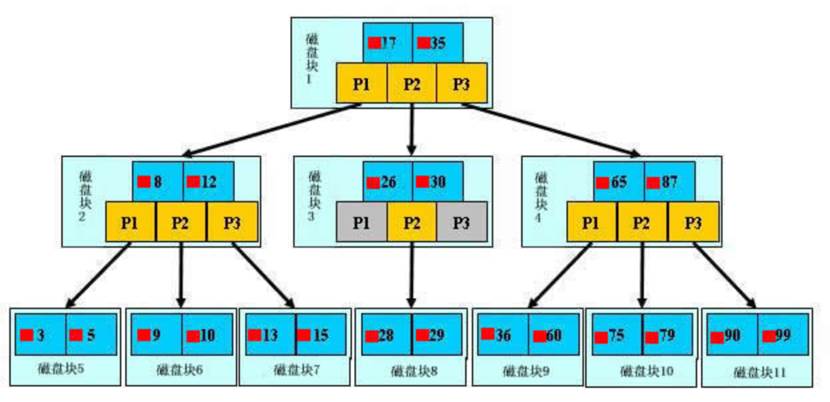
图中比如根结点,其中17表示一个磁盘文件的文件名;小红方块表示这个17文件的内容在硬盘中的存储位置;p1表示指向17左子树的指针。
叶子节点存放所有的数据,中间节点只用作查询,不用做数据保存
现在我们模拟查找文件29的过程:
(1) 根据根结点指针找到文件目录的根磁盘块1,将其中的信息导入内存。【磁盘IO操作1次】
(2) 此时内存中有两个文件名17,35和三个存储其他磁盘页面地址的数据。根据算法我们发现17<29<35,因此我们找到指针p2。
(3) 根据p2指针,我们定位到磁盘块3,并将其中的信息导入内存。【磁盘IO操作2次】
(4) 此时内存中有两个文件名26,30和三个存储其他磁盘页面地址的数据。根据算法我们发现26<29<30,因此我们找到指针p2。
(5) 根据p2指针,我们定位到磁盘块8,并将其中的信息导入内存。【磁盘IO操作3次】
(6) 此时内存中有两个文件名28,29。根据算法我们查找到文件29,并定位了该文件内存的磁盘地址。
1.1.3 索引是建的越多越好吗
答案自然是否定的,大小受磁盘页控制
\1) 数据量小的表不需要建立索引,建立会增加额外的索引开销
\2) 不经常引用的列不要建立索引,因为不常用,即使建立了索引也没有多大意义
\3) 经常频繁更新的列不要建立索引,因为肯定会影响插入或更新的效率
\4) 数据重复且分布平均的字段,建立索引就没有太大的效果(例如性别字段,只有男女,不适合建立索引)
\5) 数据变更需要维护索引,意味着索引越多维护成本越高。
\6) 更多的索引也需要更多的存储空间
内存的访问速度是远远大于外存(IO)访问的速度的,因此,当m阶B树的m越大,单一节点的元素树越多,B树的高度就越低,IO访问的次数就越少。但是,也不是m越大越好,当m大到m个数据,外存一个磁盘页装不下就糟了。因此m是受磁盘页大小限制的
1.1.4 B+树和B树相比有何优势呢?
B+树适用于范围查找,性能稳定,查找一定落在叶子节点
1.2 联合索引
1.2.1 聚集索引与非聚集索引
聚集索引:内容按照一定规则排列的
类似于根据拼音目录查文字,一个表只能有一个,如果没有创建索引,mysql中会默认将表的主键作为聚集索引
非聚集索引:就是除了聚集索引以外都是非聚集索引
一个表可以定义多个非聚集索引,分成普通索引,唯一索引,全文索引。
如果非要把非聚集索引类比成现实生活中的东西,那么非聚集索引就像新华字典的偏旁字典,他结构顺序与实际存放顺序不一定一致。
聚集索引在物理上是连续存在的,非聚集索引是逻辑上连续的
聚族索引:InnoDB的聚族索引保存了B-Tree索引和数据行,聚族索引不是一种单独的索引类型,而是一种数据存储方式。
术语“聚族”表示数据行和相邻的键值紧凑地存储在一起。数据行存放在索引的叶子页中。
1.2.2 联合索引
命名规则:表名_字段名
1、需要加索引的字段,要在where条件中
2、数据量少的字段不需要加索引
3、如果where条件中是OR关系,加索引不起作用
4、符合最左原则
联合索引又叫复合索引。对于复合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。例如索引是key index (a,b,c). 可以支持a | a,b| a,b,c 3种组合进行查找,但不支持 b,c进行查找 .当最左侧字段是常量引用时,索引就十分有效。
1.2.3 联合索引为什么有最左匹配
联合索引 (a,b,c)
联合索引 (a,b,c) 实际建立了 (a)、(a,b)、(a,b,c) 三个索引
我们可以将组合索引想成书的一级目录、二级目录、三级目录,如index(a,b,c),相当于a是一级目录,b是一级目录下的二级目录,c是二级目录下的三级目录。要使用某一目录,必须先使用其上级目录,一级目录除外。
如下:

1.2.4 联合索引的优势
1) 减少开销
建一个联合索引 (a,b,c) ,实际相当于建了 (a)、(a,b)、(a,b,c) 三个索引。每多一个索引,都会增加写操作的开销和磁盘空间的开销。对于大量数据的表,使用联合索引会大大的减少开销!
2)覆盖索引
对联合索引 (a,b,c),如果有如下 sql 的,
SELECT a,b,c from table where a='xx' and b = 'xx';
那么 MySQL 可以直接通过遍历索引取得数据,而无需回表,这减少了很多的随机 io 操作。减少 io 操作,特别是随机 io 其实是 DBA 主要的优化策略。
所以,在真正的实际应用中,覆盖索引是主要的提升性能的优化手段之一。
3)效率高
索引列多,通过联合索引筛选出的数据越少。比如有 1000W 条数据的表,有如下SQL:
select col1,col2,col3 from table where col1=1 and col2=2 and col3=3;
假设:假设每个条件可以筛选出 10% 的数据。
A. 如果只有单列索引,那么通过该索引能筛选出 1000W10%=100w 条数据,然后再回表从 100w 条数据中找到符合 col2=2 and col3= 3 的数据,然后再排序,再分页,以此类推(递归);
B. 如果是(col1,col2,col3)联合索引,通过三列索引筛选出 1000w10% 10% *10%=1w,效率提升可想而知!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号