Mysql——8、mysql主从
1 mysql主从
1.1 主从复制原理
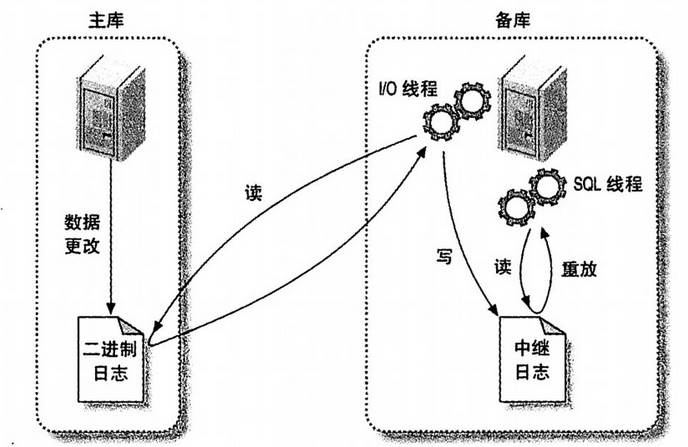
默认是异步复制的
1.主库记录binlog日志
在每次准备提交事务完成数据更新前,主库将数据更新的事件记录到二进制日志binlog中。主库上的sync_binlog参数控制binlog日志刷新到磁盘。
2.从库IO线程将主库的binlog日志,复制到其本地的中继日志relay log中
从库会启动一个IO线程,IO线程会跟主库建立连接,然后主库会启动一个特殊的二进制转储线程(binlog dump),二进制转储线程会读取主库上binlog中的事件,它不会一直对事件进行轮询,当它追赶上了主库就会进入睡眠状态,直到主库发送信号量,通知其有新事件产生才会被唤醒。
3.从库的SQL线程进行重放
从库的SQL线程从中继日志relay log中读取事件,并在从库执行,从而实现从库数据的更新。
主库增删改,会产生binlog日志,主库有io线程,将binlog日志发送到从库IO线程,从库写入relay日志,
SQL线程将relay日志转化为数据存库,从库读binlog,写relay日志,
落库过程是串行的,主库是并发的。高版本的从库。读binlog是并行的
1.2 主从备份的优点
\1) mysql的主从复制的主要优点是同步"备份", 在从机上的数据库就相当于一个(基本实时)备份库.
\2) 在主从复制基础上, 通过mysqlproxy可以做到读写分离, 由从机分担一些查询压力.
\3) 做一个双向的主从复制, 两台机器互相为主机从机, 这样, 在任何一个机器的库中写入, 都会"实时"同步到另一台机器, 双向的优点在于当一台主机发生故障时, 另一台主机可以快速的切换过来继续服务.
1.3 Mysql的bin文件
MySql中有一种日志叫做bin日志(二进制日志)。这个日志会记录下所有修改了数据库的SQL语句(insert,update,delete,ALTER,TABLE,grant等等)。
主从复制的原理其实就是把主服务器上的bin日志,复制到从服务器上执行一遍,这样,从服务器上的数据就和主服务器上的数据相同了
mysql的mysql-bin是数据库的操作日志文件,如果不做主从复制的话,基本上是没用的。
例如UPDATE一个表,或者DELETE一些数据,即使该语句没有匹配的数据,这个命令也会存储到日志文件中,还包括每个语句执行的时间,也会记录进去的。
这样做主要有以下两个目的:
\1) 数据恢复如果你的数据库出问题了,而你之前有过备份,那么可以看日志文件,找出是哪个命令导致你的数据库出问题了,想办法挽回损失。
\2) 主从服务器之间同步数据主服务器上所有的操作都在记录日志中,从服务器可以根据该日志来进行,以确保两个同步。举例:当单一的mysql服务器服务使用时,可以将相应的 log-bin=/program/mysql/mysql-bin 该项注释掉,加 “#”号然后重启 mysql 服务。
1.4 主从复制的配置
接下来讲下具体的实现步骤:
修改主数据库根目录下的my.ini配置文件,添加server-id=1 , 设置服务器id,配置需要备份的数据库(binlog-do-db=库名),设置不需要备份的数据库(binlog-ignore-db=库名) ,开启二进制日志(log-bin=mysql-bin),然后重启数据库
理解:
将主库和从库的数据保持一致,主要实现的方法是
(1)第一种方法将锁定主表让数据保持现在状态,具体操作为以下几步:
a) MYSQL-A 下执行SQL命令:flush tables with read lock;目的是锁表
b) MYSQL-B下面执行命令:mysqldump -h10.0.0.2 -uroot -proot virt > var/backup/virtback.sql;备份数据;
c) MYSQL-A下执行SQL命令:unlock tables;解除锁定。
d) MYSQL-B 执行命令:mysql -uroot -proot virt < var/backup/virtback.sql;还原数据
(2)第二种方法就是使用复制数据,将主库copy一份到从库
1、主库: 1. 注册一个用户 % 表示所有客户端都能连
\2. 登录主服务器的mysql,查询master的状态 show master status;
从库: 1.配置从服务器Slave: change master to master_host='192.168.145.222',master_user='mysync',master_password='q123456',
master_log_file='mysql-bin.000004',master_log_pos=308; //注意不要断开,308数字前后无单引号。
2.start slave; //开启从服务器复制功能
3.检查从服务器复制功能状态 show slave status

红框标注的值都为YES 说明配置成功。自己可以选择配置的数据库表中添加数据进行测试。
1.5 mysql主从复制存在的问题
mysql主从复制存在的问题
a) 主库宕机后,数据可能丢失
b) 从库只有一个sql Thread,主库写压力大,复制很可能延时
解决方法:
a) 半同步复制---解决数据丢失的问题
b) 并行复制----解决从库复制延迟的问题
1.6 主从延时
1.6.1 如何查看主从是否延时
可以通过监控 show slave status 命令输出的Seconds_Behind_Master参数的值,来检测主从延时:
NULL:表示io_thread或是sql_thread有任何一个发生故障;
0:该值为零,表示主从复制良好;
正值:表示主从已经出现延时,数字越大,表示从库延迟越严重。
1.6.2 为什么会造成主从延时
由于主库上可以多客户端并发的写入,当主库的TPS较高时,由于从库的SQL线程是单线程的,导致从库处理速度,可能会跟不上主库的处理速度,从而造成了延迟。
1.6.3 并发与主从延时的时间
\1) 主库并发达到1000/s时,从库的延时会有几毫秒,几乎可以忽略。
\2) 主库并发达到2000/s时,从库的延时会有几十毫秒。
\3) 主库并发达到4000/s,6000/s,8000/s时,此时主库的压力很大,都快挂了。从库的延时会达到几秒。
1.6.4 主从延时造成的现象
刚刚写入库的数据去查,却没有查到,可能是发生了主从延时,
比如:刚插入一条订单数据,然后立即根据id查询,有很大概率是取不到任何数据的,因为从库没来得及更新
注意:
实际上要虑好应该在什么场景下来用这个mysql主从同步,建议是一般在读远远多于写,而且读的时候一般对数据时效性要求没那么高的时候,才用mysql主从同步
所以通常来说,对于那种写了之后,立马就要保证可以查到的场景,采用强制读主库的方式,或数据库中间件,这样,就可以保证你肯定的可以读到数据
1.6.5 如何解决主从延时
1、分库,将主库拆分成多个;
2、重写代码,插入数据后,不要立即查询,如果需要立即查询的,直接读主库
i. 主库查询的Sql查询语句上加上/master/标识
ii. 使用mybatis插件,new MasterQueryRouter,start和end方法内的全走主库
MasterQueryRouter内部使用了threadlocal
3、开启并行复制
Mysql5.7的版本开启并行复制
通过设置参数slave_parallel_workers>0并且global.slave_parallel_type=‘LOGICAL_CLOCK’开启并行复制
理解:
一般来说,如果主从延迟较为严重:
\1) 架构层面:分库,将一个主库拆分为多个。
比如将1个库拆为4个主库,每个主库的写并发就500/s,此时主从延迟可以忽略不计。
\2) 开启mysql支持的并行复制,多个库并行复制。
但如果说某个库的写入并发就是特别高,单库写并发达到了2000/s,并行复制还是没意义。28法则,很多时候比如说,就是少数的几个订单表,写入了2000/s,其他几十个表10/s。
\3) 代码层面:重写代码。
写代码的同学,要慎重。当时我们其实短期是让那个同学重写了一下代码,插入数据之后直接就更新,不要查询。
\4) 直连主库。
如果确实存在插入后立马要求就查询到,然后根据结果(比如某个状态)反过来执行一些操作,则可以对这个查询设置【直连主库】。
但不推荐这种方法,这么搞导致读写分离的意义就丧失了。
1.6.6 如何强制主库查询
1、走主库查询的SQL上加/master/标识
2、使用mybatis插件,new MasterQueryRouter,start和end方法内的全走主库
理解:
一般的业务系统,对于数据库的读操作会远远大于写操作,为了提高查询性能,降低写库的压力,DBA团队一般会引入数据库中间件实现读写分离,比如atlas。
这种引入中间件的方式,对上层应用是透明的,对于应用层来说,就像连接了一个mysql实例。当SQL请求打到数据库中间件上时,查询的SQL会被自动路由到从库(多个从库均衡分配),写SQL会被路由到主库。
因为主从同步一定会存在延迟,所以在某些场景下,会出现SQL查询无法获取最新数据的情况,比如刚插入一条订单数据,然后立即根据id查询,有很大概率是取不到任何数据的,因为从库没来得及更新。
解决方法也很直接,强制查询走主库,atlas中间件就提供了这样的机制,在SQL前加上/master/,就会被路由到主库。
方法一:在需要走主库查询的SQL上加/master/标识
采用这种方式,我们的mybatis mapper文件可能存在一些重复的代码,比如给某些查询写一些强制走主库的版本,如下:
在业务处理中,也可能要写多个版本的方法,来区分是否强制查询走主库。
(推荐)方法二:通过mybatis插件机制动态修改SQL
期望业务代码可以这样写:
public void foo() {
MasterQueryRouter router = new MasterQueryRouter();
router.start(); // start和end方法之间的所有SQL查询均走主库
// sqlQuery1
// sqlQuery2
router.end(); // end方法之后的SQL查询仍然是默认走从库
// sqlQuery3
// some code
}
sqlQuery1, sqlQuery2查询走主库。sqlQuery3查询默认走从库。
MasterQueryRouter类通过ThreadLocal保证线程安全,且不需要到处传递是否强制主库查询的标识,在这一点上借鉴了Spring @Transaction的实现。
public class MasterQueryRouter implements Closeable { private static ThreadLocal
为了及时清理是否走主库的标识,这儿特意实现了Closeable接口,调用方需要保证在当前线程执行完毕后,清理资源。
结合lombok,代码会更加简洁,如下:
public void foo() { @Cleanup // try...finally... MasterQueryRouter router = new MasterQueryRouter(); router.start(); // start和end方法之间的所有SQL查询均走主库 // some code, contains sql query router.end(); // end方法之后的SQL查询仍然是默认走从库 // some code }
@Cleanup表示不需要手动通过try-finally来关闭资源,
这个方案,还可以再进一步,比如可以创建一个注解类@ForceMasterQuery,在需要强制主库查询的方法上加上这个注解,然后通过AOP的方式,在方法执行前开启主库查询,方法结束后关闭主库查询。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号