MySQL——5、B+树索引
mysql数据库中的索引是基于hash表或B+树
1.1 *H**ash索引*
哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法,即可立刻定位到相应的位置,速度非常快。
1.1.1 *B+树索引和哈希索引区别*
B+树索引和哈希索引的明显区别是:
1、 如果是等值查询,那么哈希索引明显有绝对优势,
因为只需要经过一次算法即可找到相应的键值;当然了,这个前提是,键值都是唯一的。如果键值不是唯一的,就需要先找到该键所在位置,然后,再根据链表往后扫描,直到找到相应的数据;
2、 如果是范围查询检索,这时候哈希索引就毫无用武之地了
因为原先是有序的键值,经过哈希算法后,有可能变成不连续的了,就没办法再利用索引完成范围查询检索;
3、 同理,哈希索引也没办法利用索引完成排序,以及like ‘xxx%’ 这样的部分模糊查询(这种部分模糊查询,其实本质上也是范围查询);
Hash支持“<=>”,b+树支持“<=>like in or between ”
4、 哈希索引也不支持多列联合索引的最左匹配规则;
5、 B+树索引的关键字检索效率比较平均,不像B树那样波动幅度大,在有大量重复键值情况下,哈希索引的效率也是极低的,因为存在所谓的哈希碰撞问题。
1.1.2 *M**ysql中应用*
在MySQL中,只有HEAP/MEMORY引擎表才能显式支持哈希索引(NDB也支持,但这个不常用),InnoDB引擎的自适应哈希索引(adaptive hash index)不在此列,因为这不是创建索引时可指定的。
还需要注意到:HEAP/MEMORY引擎表在mysql实例重启后,数据会丢失。
通常,B+树索引结构适用于绝大多数场景
1.1 *B+树索引*
1.1.1 *B-树/B树*
1.1.1.1 *索引为什么使用树结构*
要弄明白B+树,先要弄明白B-树,B-树就是B树,中间的横线不是减号
1、数据库索引为什么要使用树结构进行存储?
树的查询效率高,并且可以保持有序
2、为什么没有使用二叉查找树树来实现?
二叉查找树查询的时间复杂度是O(logN),从算法逻辑上来讲,二叉查找树的查找速度和比较次数都是最小的,但需要考虑一个现实问题:磁盘IO
数据库索引是存储在磁盘上的,当数据量比较大的时候,索引的大小可能有几个G,甚至更多
当我们利用索引查询的时候,不能将整个索引全部加载到内存中,能做的只有逐一加载每一个磁盘页,这里的磁盘页就对应着索引树的节点

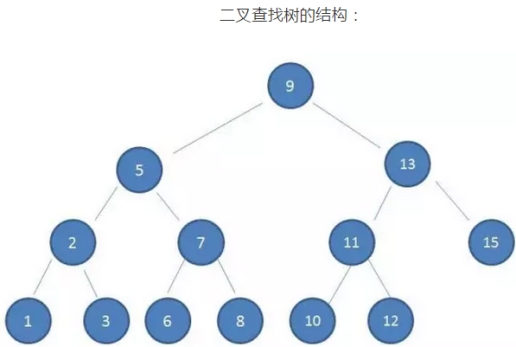
如果利用二叉查找树作为索引结构,假设树的高度是4,查找的值是10,则流程如下:
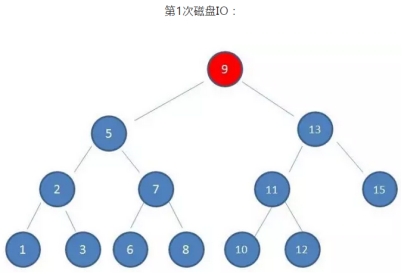
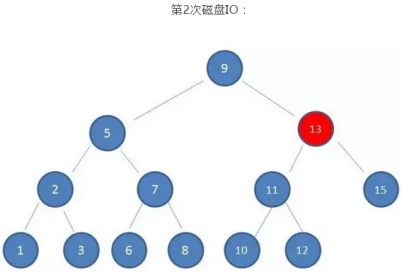
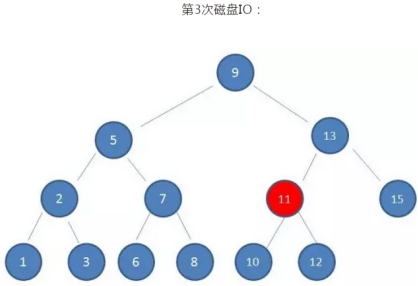
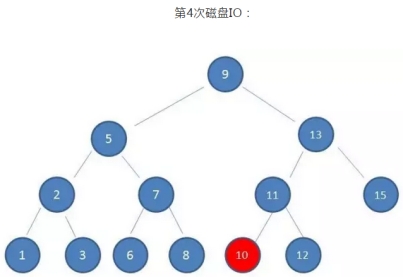
可以看到:
磁盘IO的次数由索引树的高度决定,即最坏查找情况下,磁盘IO的次数等于索引树的高度
为了减少磁盘IO的次数,就需要将将原本“瘦高”的树结构变得“矮胖”,这就是B树的特征之一
1.1.1.2 *B树的特征*
B树是一种多路平衡查找树,它的每一个节点最多包含K个孩子,K被称为B树的阶,K的大小取决于磁盘页的大小
一个m阶的B树具有如下几个特征:
1、 根结点至少有两个子女。
2、 每个中间节点都包含k-1个元素和k个孩子,其中 m/2 <= k <= m
3、 每一个叶子节点都包含k-1个元素,其中 m/2 <= k <= m
4、 所有的叶子结点都位于同一层。
5、 每个节点中的元素从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域分划。
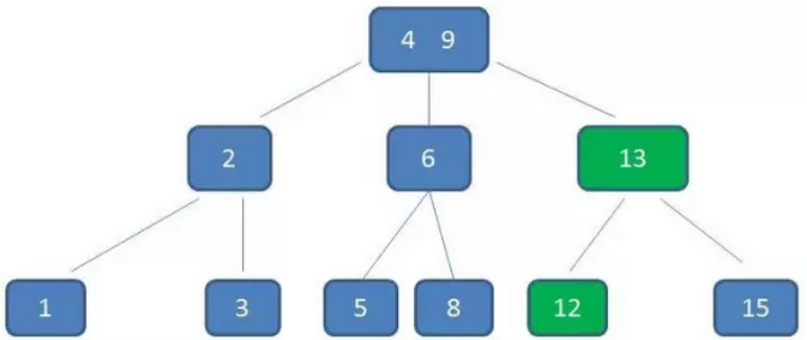
示例:以一个3阶B树为例:
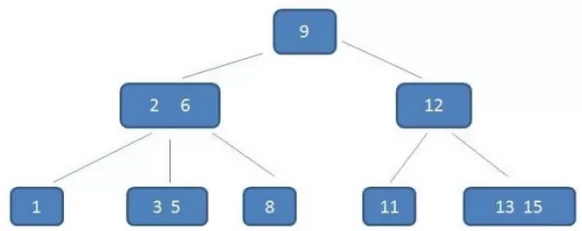
重点看(2,6)节点:
该节点中有两个元素2,6,有三个孩子1,(3,5),8
其中1小于元素2,(3,5)在元素2,6之间,8大于(3,5)(规则5)
均符合B树的几条特征
1.1.1.3 *B树的查询过程*
B树的查询过程如下:如果B树中查询数值5
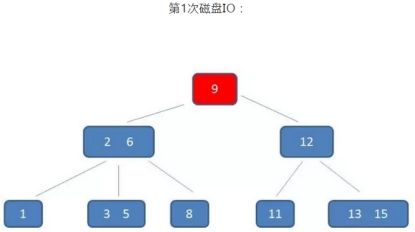
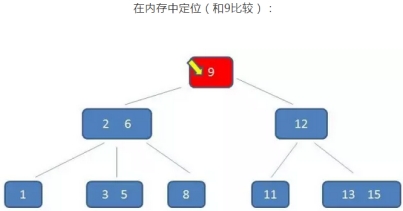
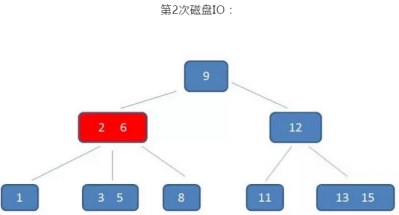
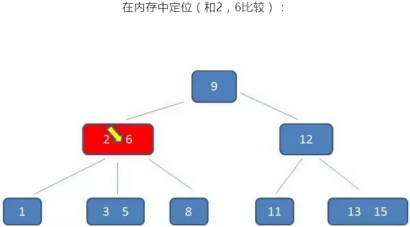
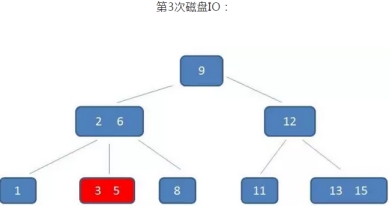
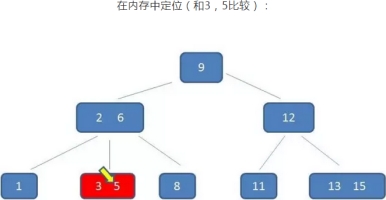
整个流程中,我们可以看出:
B树中的查询次数并不比二叉查找树少,尤其当单一节点中的元素数量很多时,可以相比磁盘IO的速度,内存中的比较耗时,可以忽略不计,
即次数查找是在磁盘IO中查找的,元素比较是在内存中进行的
磁盘读取时,不是按需读取的,而是读取当前数据,并向后读取一段数据,将这段数据加载到内存中,默认这段数据为一页,或页的整数倍,
B树添加节点的时候,默认申请一个磁盘页的空间,用来存储一个节点的数据,这样每个节点只需要一次IO,就可以完全载入
一个节点的数据需要通过一次磁盘IO进行读取,读取到内存中,节点中的数据比较,则是在内存中进行
只要树的高度足够低,IO的次数足够少,就可以提升查找性能。节点内部元素多一些,没有关系,仅仅是多了几次内存交互而已,只要不超过磁盘页的大小即可,这也是B树的优势之一
1.1.1.4 *B树的插入过程*
B树的插入删除过程比较复杂,可以看一个典型的例子:
示例:加入插入的值4:
自顶向下查找4的节点位置,发现4应当插入到节点元素3,5之间。
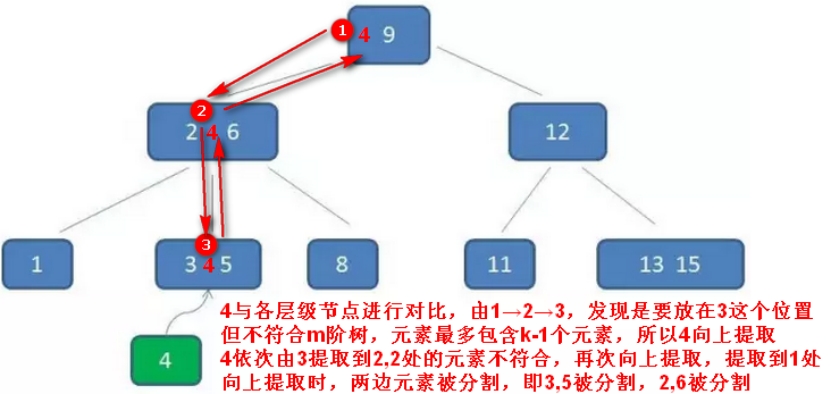
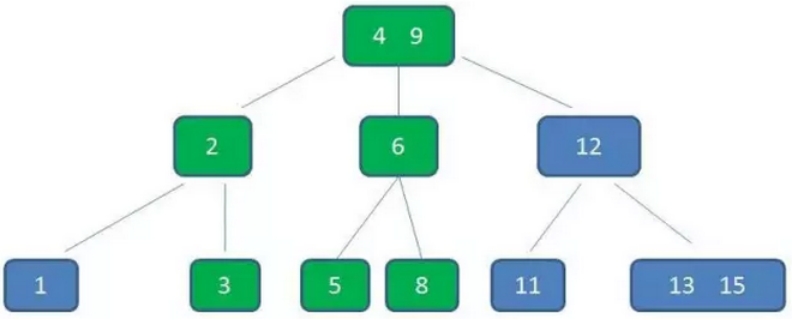
动画演示:https://www.cnblogs.com/vincently/p/4526560.html
可以看到:
为了插入一个元素,整个B树中,很多节点都发生了连锁改变,但这也是B树的一大特点,始终能够维持多路平衡,即自平衡
1.1.1.5 *B树的删除过程*
示例:删除元素11
自顶向下查找元素11的节点位置。
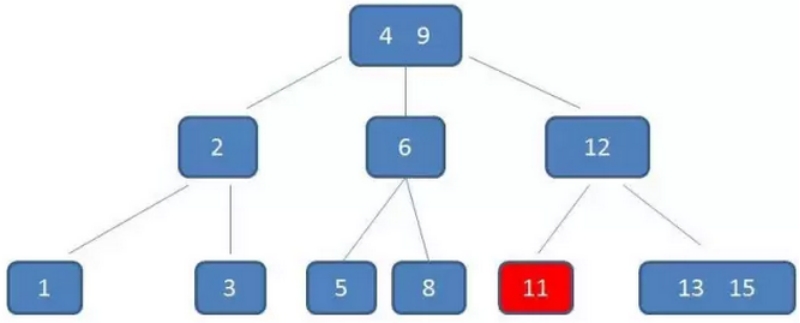
删除11后,节点12只有一个孩子,不符合B树规范。因此找出12,13,15三个节点的中位数13,取代节点12,而节点12自身下移成为第一个孩子。(这个过程称为左旋)
1.1.1.6 *B树的实际应用*
B树主要应用与文件系统,以及部分数据索引,如非关系型数据库MongoDB,大部分关系型数据库,如MySql,使用B+树作为索引
1.1.2 *B+树实现细节是什么样?*
1.1.2.1 *B+树的特征*
一个m阶的B+树具有如下几个特征:
1、 有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。
2、 所有的叶子结点中包含了全部元素的信息,及指向这些元素的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
3、 所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。
示例:
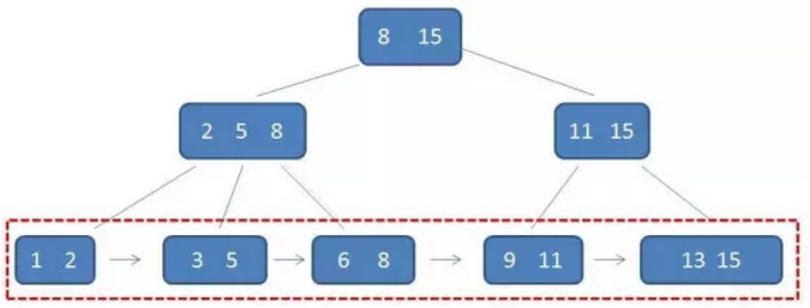
可以看到:
每一个父节点的元素都出现在了子节点,是子节点中的最大(或最小)元素
根节点的最大元素,就等同于整个B+树的最大元素
由于父节点的元素都包含在了子节点中,因此所有叶子节点包含了全量元素信息
每一个叶子节点都带有指向下一个节点的指针,形成了一个有序链表
B+树有卫星数据,即索引元素所指向的数据记录,比如数据库中的某一行,
在B-树中,无论中间节点还是叶子节点,都带有卫星数据
B+树中,只有叶子节点带有卫星数据,其他中间节点仅仅是索引,没有任何数据关联
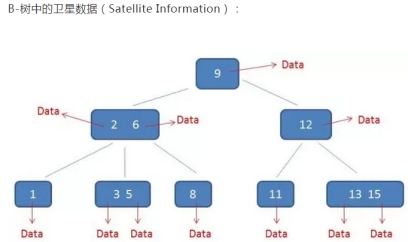
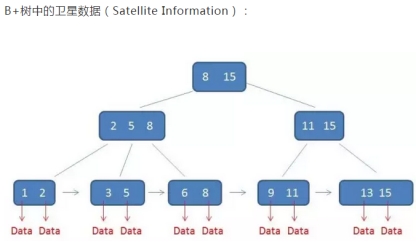
在数据库的聚集索引中,叶子节点直接包含卫星数据,在非聚集索引中,叶子节点带有指向卫星数据的指针
1.1.2.2 *B+树的查询*
B+树的好处主要体现在查询性能上
2 *单行查询*
在单元素查询的时候,B+树会自顶向下逐层查找节点,最终找到匹配的叶子节点
示例:查找元素3
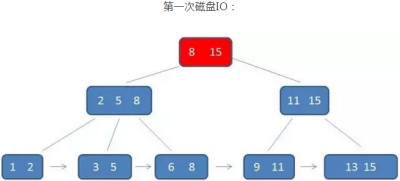
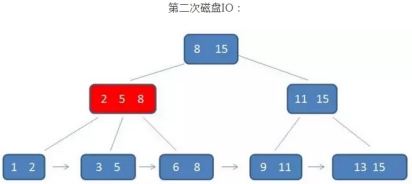
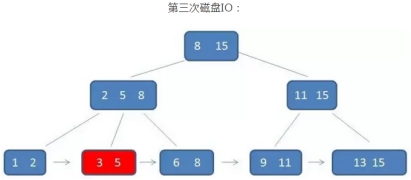
注意:B+树的查询看起来与B树差不多,但实际上有两点不同:
1、 B+树的中间节点没有卫星数据,所以,同样大小的磁盘页,B+树的磁盘页可以容纳更多的节点数据
即数据量相同的情况下,B+树的结构比B-树更加“矮胖”,因此,查询时,IO次数更少
2、 B+树的查询必须通过查找叶子节点,而B树只需要找到元素即可,无论匹配的元素是处于中间节点,还是叶子节点
因此,B树的查找性能不稳定,最好的情况是查找到根节点,最坏的情况是查找到叶子节点
而B+树的查找性能是稳定的,每一次都固定查找到叶子节点
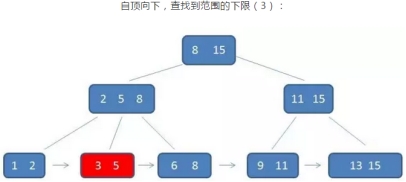
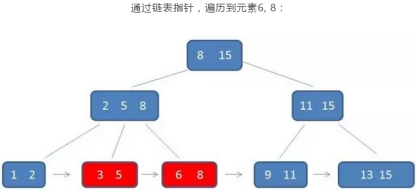
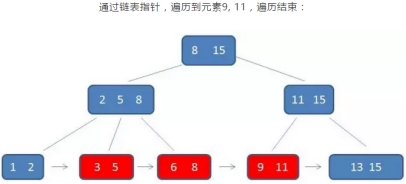
3 *范围查询*
B+树的范围查询,要远远好于B树的范围查询
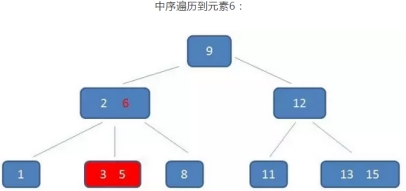
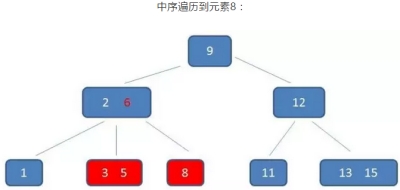
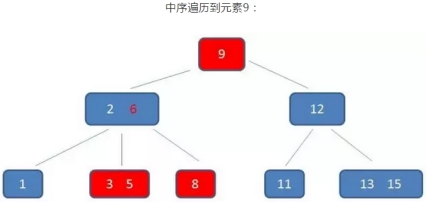
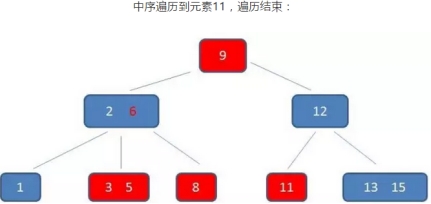
示例:查询3到11的元素
B树的查找过程:
需要依靠繁琐的中序遍历
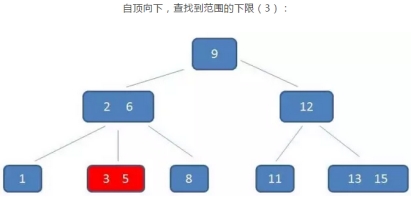
B+树的查找过程:
只需要在叶子节点的链表上做遍历即可
B+树相对于B树而言,优势有:
1、 IO次数更少;
2、 查询性能更稳定;
3、 范围查询简便;
3.0.1 *B-树与B+树的区别?*
B+树相对于B树的优势:
1.单一节点存储更多的元素,使得查询的IO次数更少。
2.所有查询都要查找到叶子节点,查询性能稳定。
3.所有叶子节点形成有序链表,便于范围查询。
B+树是以空间换时间啊 ,因为子节点都包含父节点的元素。树的层数和一个节点被重复存储成线性关系
的确是以空间换时间。父节点元素在子节点重复出现,增加了少量空间,换来的是范围查询的便利。
那还要B-树有何用?
B-树的好处是,虽然查询性能不稳定,但平均的查询速度快一些(不用每次都查找到叶子节点为止)
为什么要强调B+树查询性能稳定呢?有特殊的应用场合么?
B+树的查询每次都查到叶子节点,所以IO次数稳定。试想一个数据库的查询,有时候执行10毫秒,有时候执行100毫秒,肯定是不太合适的。还不如每次都执行30毫秒
3.0.2 *联合索引在B+树中如何存储?*
简单的说,联合索引就是把多个索引值拼接成一个字符串A,字符串A像普通索引一样保存在索引树中。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号