MySQL——2、索引
1.1 *索引*
索引支持整个列,不支持局部索引
innoDB默认支持btree索引,memory默认支持hash索引

1.1.1 *聚集索引与非聚集索引的区别*
微软的SQL SERVER提供了两种索引:聚集索引(clustered index,也称聚类索引、簇集索引)和非聚集索引(nonclustered index,也称非聚类索引、非簇集索引)
我们的汉语字典的正文本身就是一个聚集索引。比如,我们要查“安”字,因为“安”的拼音是“an”,而按照拼音排序汉字的字典是以英文字母“a”开头并以“z”结尾的,那么“安”字就自然地排在字典的前部。如果您翻完了所有以“a”开头的部分仍然找不到这个字,那么就说明您的字典中没有这个字。也就是说,字典的正文部分本身就是一个目录,您不需要再去查其他目录来找到您需要找的内容。我们把这种正文内容本身就是一种按照一定规则排列的目录称为“聚集索引”。
如果遇到不认识的字,不知道它的发音,这时候,需要去根据“偏旁部首”查到您要找的字,然后根据这个字后的页码直接翻到某页来找到您要找的字。但您结合“部首目录”和“检字表”而查到的字的排序并不是真正的正文的排序方法,比如您查“张”字,我们可以看到在查部首之后的检字表中“张”的页码是672页,检字表中“张”的上面是“驰”字,但页码却是63页,“张”的下面是“弩”字,页面是390页。很显然,这些字并不是真正的分别位于“张”字的上下方,现在您看到的连续的“驰、张、弩”三字实际上就是他们在非聚集索引中的排序,是字典正文中的字在非聚集索引中的映射。我们可以通过这种方式来找到您所需要的字,但它需要两个过程,先找到目录中的结果,然后再翻到您所需要的页码。我们把这种目录纯粹是目录,正文纯粹是正文的排序方式称为“非聚集索引”。
通过以上例子,我们可以理解到什么是“聚集索引”和“非聚集索引”。进一步引申一下,我们可以很容易的理解:每个表只能有一个聚集索引,因为目录只能按照一种方法进行排序。
区别:
聚集索引一个表只能有一个,而非聚集索引一个表可以存在多个
聚集索引存储记录是物理上连续存在,而非聚集索引是逻辑上的连续,物理存储并不连续
聚集索引:物理存储按照索引排序;聚集索引是一种索引组织形式,索引的键值逻辑顺序决定了表数据行的物理存储顺序。
非聚集索引:物理存储不按照索引排序;非聚集索引则就是普通索引了,仅仅只是对数据列创建相应的索引,不影响整个表的物理存储顺序。
索引是通过二叉树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
优势与缺点:
聚集索引插入数据时速度要慢(时间花费在“物理存储的排序”上,也就是首先要找到位置然后插入),查询数据比非聚集数据的速度快。
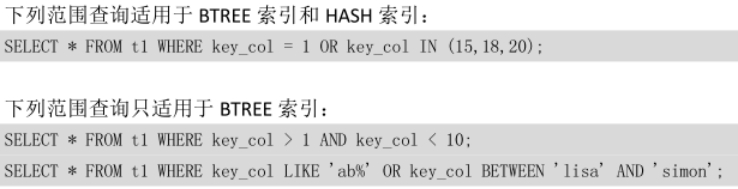
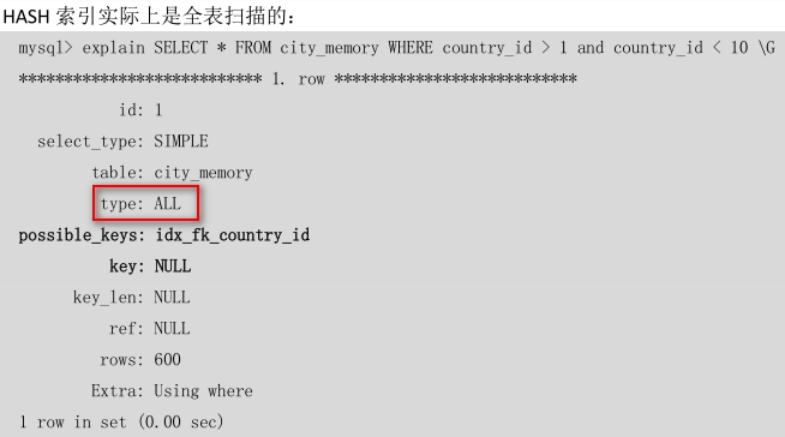
1.1.2 *BTREE索引与Hash索引*
hash索引的特点:




1.1.1 *四种索引类型*
*索引(Index)是帮助DBMS高效获取数据的数据结构。*
分类:普通索引/唯一索引/主键索引/全文索引
普通索引:允许重复的值出现
唯一索引:除了不能有重复的记录外,其它和普通索引一样(用户名、用户身份证、email,tel)
主键索引:是随着设定主键而创建的,也就是把某个列设为主键的时候,数据库就会給该列创建索引。这就是主键索引.唯一且没有null值
全文索引:用来对表中的文本域(char,varchar,text)进行索引, 全文索引针对MyIsam
explain select * from articles where match(title,body) against(‘database’);【会使用全文索引】
1.1.3 *索引使用小技巧?*
索引弊端
1.占用磁盘空间。
2.对dml(插入、修改、删除)操作有影响,变慢。
使用场景:
a: 肯定在where条件经常使用,如果不做查询就没有意义
b: 该字段的内容不是唯一的几个值(sex)
c: 字段内容不是频繁变化.
具体技巧:
\1. 对于创建的多列索引(复合索引),不是使用的第一部分就不会使用索引。
alter table dept add index my_ind (dname,loc); // dname 左边的列,loc就是右边的列
explain select * from dept where dname='aaa'\G 会使用到索引
explain select * from dept where loc='aaa'\G 就不会使用到索引
\2. 对于使用like的查询,查询如果是’%aaa’不会使用到索引,而‘aaa%’会使用到索引。
explain select * from dept where dname like '%aaa'\G不能使用索引
explain select * from dept where dname like 'aaa%'\G使用索引.
所以在like查询时,‘关键字’的最前面不能使用 % 或者 _这样的字符.,如果一定要前面有变化的值,则考虑使用 全文索引->sphinx.
\3. 如果条件中有or,即使其中有条件带了索引,也不会使用。
\4. 如果列类型是字符串,那一定要在条件中将数据使用引号引用起来。否则不使用索引。
expain select * from dept where dname=’111’;
expain select * from dept where dname=111;(数值自动转字符串)
expain select * from dept where dname=qqq;报错
也就是,如果列是字符串类型,无论是不是字符串数字就一定要用 ‘’ 把它包括起来.
\5. 如果mysql估计使用全表扫描要比使用索引快,则不使用索引。
表里面只有一条记录


 浙公网安备 33010602011771号
浙公网安备 33010602011771号