Spark MinMaxScaler 归一化之最小最大值标准化
1、概述
MinMaxScaler转换Vector行的数据集,将每个要素重新缩放到特定范围(通常为[0,1])。它带有参数:
最小值:默认为0.0。转换后的下限,由所有功能共享。
最大值:默认为1.0。转换后的上限,由所有功能共享。
MinMaxScaler计算数据集的摘要统计信息并生成MinMaxScalerModel。然后,模型可以分别变换每个特征,以使其处于给定范围内。
特征E的重定比例值计算为:
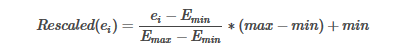
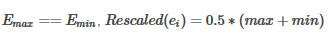
请注意,由于零值可能会转换为非零值,所以即使对于稀疏输入,转换器的输出也将是DenseVector。
2、code
package com.home.spark.ml import org.apache.spark.SparkConf import org.apache.spark.ml.feature.MinMaxScaler import org.apache.spark.ml.linalg.Vectors import org.apache.spark.sql.SparkSession /** * @Description: 使用列摘要统计信息将每个特征分别线性地缩放到公共范围[min,max] *,也称为最小-最大规格化或重新缩放 * 由于零值可能会转换为非零值,因此即使对于稀疏输入,转换器的输出也将是DenseVector **/ object Ex_MinMaxScaler { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf(true).setMaster("local[2]").setAppName("spark ml") val spark = SparkSession.builder().config(conf).getOrCreate() val dataFrame = spark.createDataFrame(Seq( (0, Vectors.dense(1.0, 0.1, -1.0)), (1, Vectors.dense(2.0, 1.1, 1.0)), (2, Vectors.dense(3.0, 10.1, 3.0)) )).toDF("id", "features") val scaler = new MinMaxScaler().setInputCol("features").setOutputCol("scaledFeatures") val model = scaler.fit(dataFrame) val scaledData = model.transform(dataFrame) println(s"Features scaled to range: [${scaler.getMin}, ${scaler.getMax}]") scaledData.select("features", "scaledFeatures").show() spark.stop() } }
Features scaled to range: [0.0, 1.0]
+--------------+--------------+
| features|scaledFeatures|
+--------------+--------------+
|[1.0,0.1,-1.0]| [0.0,0.0,0.0]|
| [2.0,1.1,1.0]| [0.5,0.1,0.5]|
|[3.0,10.1,3.0]| [1.0,1.0,1.0]|
+--------------+--------------+

 浙公网安备 33010602011771号
浙公网安备 33010602011771号