spark Normalizer 规范化 归一化
1、概念
将某个特征向量(由所有样本某一个特征组成的向量)计算其p-范数,然后对该每个元素除以p-范数。将原始特征Normalizer以后可以使得机器学习算法有更好的表现。
当p取1,2,∞的时候分别是以下几种最简单的情形: 1-范数(L1):║x║1=│x1│+│x2│+…+│xn│ 2-范数(L2):║x║2=(│x1│²+│x2│²+…+│xn│²)然后开根号 ∞-范数(L∞):║x║∞=max(│x1│,│x2│,…,│xn│)
单位P-范数定义如下:
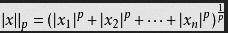
1.1 背景
为什么数据需要归一化?以房价预测为案例,房价(y)通常与离市中心距离(x1)、面积(x2)、楼层(x3)有关,设y=ax1+bx2+cx3,
那么abc就是我们需要重点解决的参数。但是有个问题,面积一般数值是比较大的,100平甚至更多,而距离一般都是几公里而已,b参数只要一点变化都能对房价产生巨大影响,而a的变化对房价的影响相对就小很多了。
显然这会影响最终的准确性,毕竟距离可是个非常大的影响因素。
所以, 需要使用特征的归一化, 取值跨度大的特征数据, 我们浓缩一下, 跨度小的括展一下, 使得他们的跨度尽量统一。 归一化就是将所有特征值都等比地缩小到0-1或者-1到1之间的区间内。其目的是为了使特征都在相同的规模中。
2、code
package com.home.spark.ml import org.apache.spark.SparkConf import org.apache.spark.ml.feature.Normalizer import org.apache.spark.ml.linalg.Vectors import org.apache.spark.sql.SparkSession /** * @Description: 使用给定的p范数对向量进行归一化,使其具有单位范数 **/ object Ex_Normalizer { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf(true).setMaster("local[2]").setAppName("spark ml") val spark = SparkSession.builder().config(conf).getOrCreate() val dataFrame = spark.createDataFrame(Seq( (0, Vectors.dense(1.0, 0.5, -1.0)), (1, Vectors.dense(2.0, 1.0, 1.0)), (2, Vectors.dense(4.0, 10.0, 2.0)) )).toDF("id", "features") val normalizer = new Normalizer().setInputCol("features").setOutputCol("normFeatures").setP(1.0) val l1NormData = normalizer.transform(dataFrame) println("Normalized using L^1 norm") l1NormData.show(false) val l2NormData = normalizer.transform(dataFrame,normalizer.p->2) println("Normalized using L^2 norm") l2NormData.show(false) val linfiData = normalizer.transform(dataFrame,normalizer.p->Double.PositiveInfinity) println("Normalized using L^inf norm") linfiData.show(false) spark.stop() } }
Normalized using L^1 norm
+---+--------------+------------------+
|id |features |normFeatures |
+---+--------------+------------------+
|0 |[1.0,0.5,-1.0]|[0.4,0.2,-0.4] |
|1 |[2.0,1.0,1.0] |[0.5,0.25,0.25] |
|2 |[4.0,10.0,2.0]|[0.25,0.625,0.125]|
+---+--------------+------------------+
Normalized using L^2 norm
+---+--------------+-----------------------------------------------------------+
|id |features |normFeatures |
+---+--------------+-----------------------------------------------------------+
|0 |[1.0,0.5,-1.0]|[0.6666666666666666,0.3333333333333333,-0.6666666666666666]|
|1 |[2.0,1.0,1.0] |[0.8164965809277261,0.4082482904638631,0.4082482904638631] |
|2 |[4.0,10.0,2.0]|[0.3651483716701107,0.9128709291752769,0.18257418583505536]|
+---+--------------+-----------------------------------------------------------+
Normalized using L^inf norm
+---+--------------+--------------+
|id |features |normFeatures |
+---+--------------+--------------+
|0 |[1.0,0.5,-1.0]|[1.0,0.5,-1.0]|
|1 |[2.0,1.0,1.0] |[1.0,0.5,0.5] |
|2 |[4.0,10.0,2.0]|[0.4,1.0,0.2] |
+---+--------------+--------------+

 浙公网安备 33010602011771号
浙公网安备 33010602011771号