spark 在yarn模式下提交作业
1、spark在yarn模式下提交作业需要启动hdfs集群和yarn,具体操作参照:hadoop 完全分布式集群搭建
2、spark需要配置yarn和hadoop的参数目录
将spark/conf/目录下的spark-env.sh.template文件复制一份,加入配置:
YARN_CONF_DIR=/opt/hadoop/hadoop-2.8.3/etc/hadoop
HADOOP_CONF_DIR=/opt/hadoop/hadoop-2.8.3/etc/hadoop
3、将spark整个目录分发到hdfs集群中每台机器上,分发命令可以参考:linux rsync
如果不想用rsync也可以直接用scp -r拷贝,测试环境下差别不大。
4、提交作业测试
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client ./examples/jars/spark-examples_2.11-2.4.4.jar 200
正常情况下很快就能计算完成:

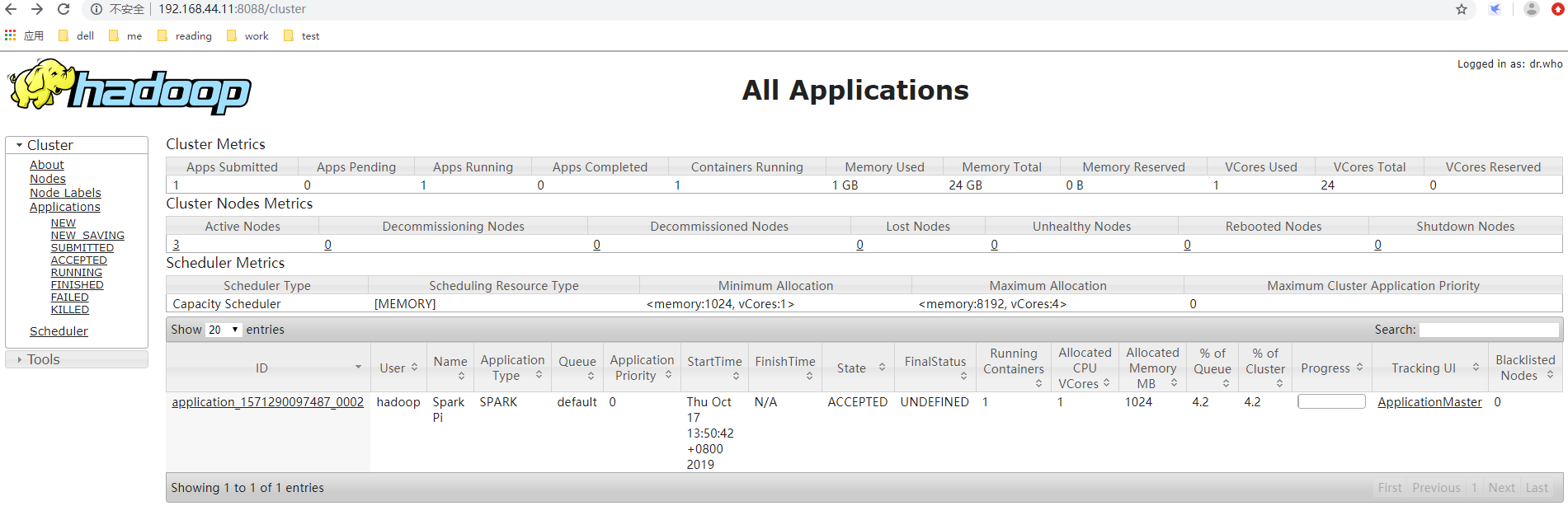
在yarn的UI可以监控到执行的作业:
5、spark参数优先级
Spark加载属性参数的优先顺序是:
(1)直接在SparkConf设置的属性参数
(2)通过 spark-submit 或 spark-shell 方式传递的属性参数
(3)最后加载 spark-defaults.conf 配置文件的属性参数
如果在程序里指定了SparkConf的参数,则spark缺省参数以及命令行参数都将失效,如果想灵活一下,我们可以在SparkConf加载缺省配置(spark-defaults.conf),然后在命令方式下覆盖参数。
val conf: SparkConf = new SparkConf(true).setAppName("SparkWordCount")
master这个参数就可以指定local或者yarn等模式,但是name参数在命令指定是无效的,因为已经内置了。
bin/spark-submit --master yarn --name myWordCount --class com.home.spark.WordCount --executor-memory 512M ~/sparkWordCount.jar hdfs://vmhome10.com:9000/input

 浙公网安备 33010602011771号
浙公网安备 33010602011771号