
一个汉字占用几个字节?3~4个!
先说答案,在UTF-8编码中,常用汉字通常占3个字节占用 4 个字节的汉字,通常是古籍用字、姓名冷僻字、地名/碑文/字典类汉字等,不属于日常常用字范畴。具体情况取决于该汉字的Unicode编码值。
要理清这个概念,需要知道人类所认知的数据(或者说信息)和计算机所理解的数据是不同的。
比如一句话(一个数据)汉语表达是“你好,世界”
英语中,“hello,world”
法语中,“Bonjour, le monde”
日语中,“こんにちは、世界”
但在计算机中,数据都变成了0和1,我们可以类比汉语中的汉字和句子,比如你好这两个字,由字你和好组成,那么转换成计算机能存储和传输的数据,就需要一张表来映射成数字(毕达哥拉斯:万物皆数),再将数字转换成二进制就变成了
11100100 10111101 10100000 // 你
11100101 10100101 10111101 // 好
由于计算机是在美国发明的,因此当时只考虑了美国人所常用的字符,那张表被称为ASCII表,如今这张表被无数人扩充变成了Unicode 符号表,UTF-8编码就是按照Unicode 符号表将字符转换为字节序列。
在线Unicode符号表查询 https://symbl.cc/ https://symbl.cc/cn/
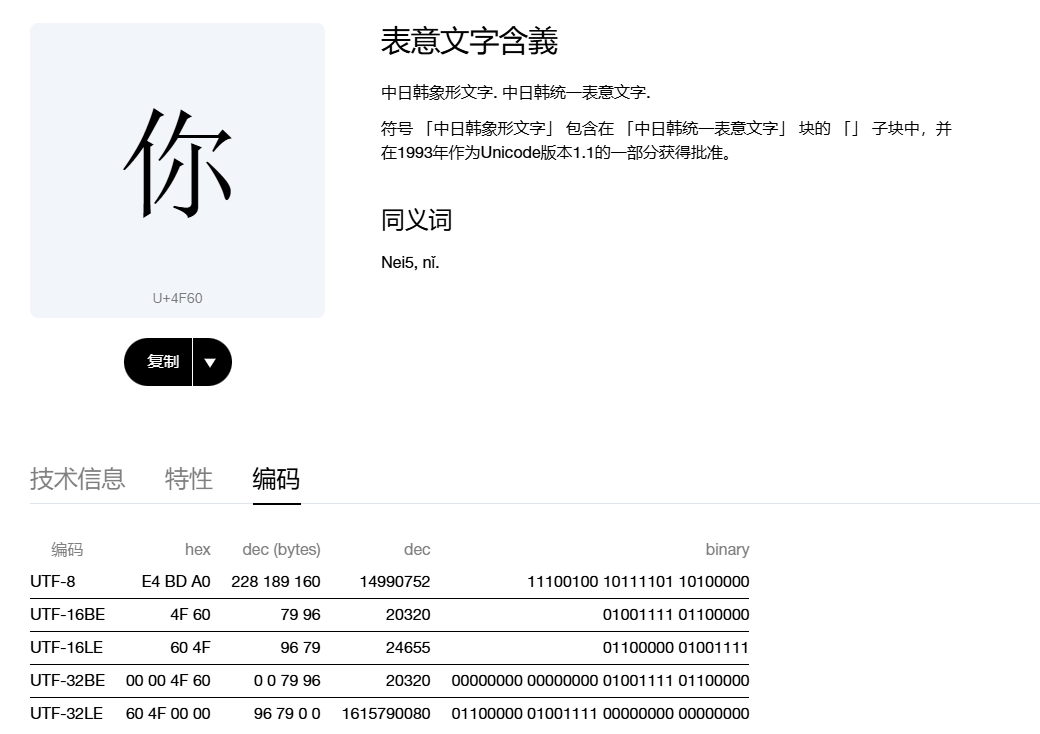
Unicode 符号表,作为人类定义出来表,其码值自然是十进制值。比如上图可以得知 f(你) = 14990752,但是计算机使用二进制,因此11100100 10111101 10100000才是计算机中你所对应的数据,但是这个表达对于人类而言又太过繁杂,因此人们常使用十六进制Hexadecimal(E4 BD A0)来表达一个字符(你)的对应的Unicode码值。
那么为什么11100100 10111101 10100000是3个字节呢?位(bit)是计算机中最小的数据单位,它只能表示0或1,也就是二进制的一个位。而字节(byte)则是8个位组成的,即8个位等于1个字节(8bit = 1byte),显然“你”这个汉字就是3个字节。
在计算机领域,人们表述十六进制、八进制值,是表示或解释这些二进制数据的一种方式
可以类比生活中的:一打,对应12支;一刻钟,对应15分钟;一年,对应365天……
简而言之,就是表述十六进制值只是为了方便(方便人类阅读和书写),实际上我们归根结底讨论的还是二进制值。
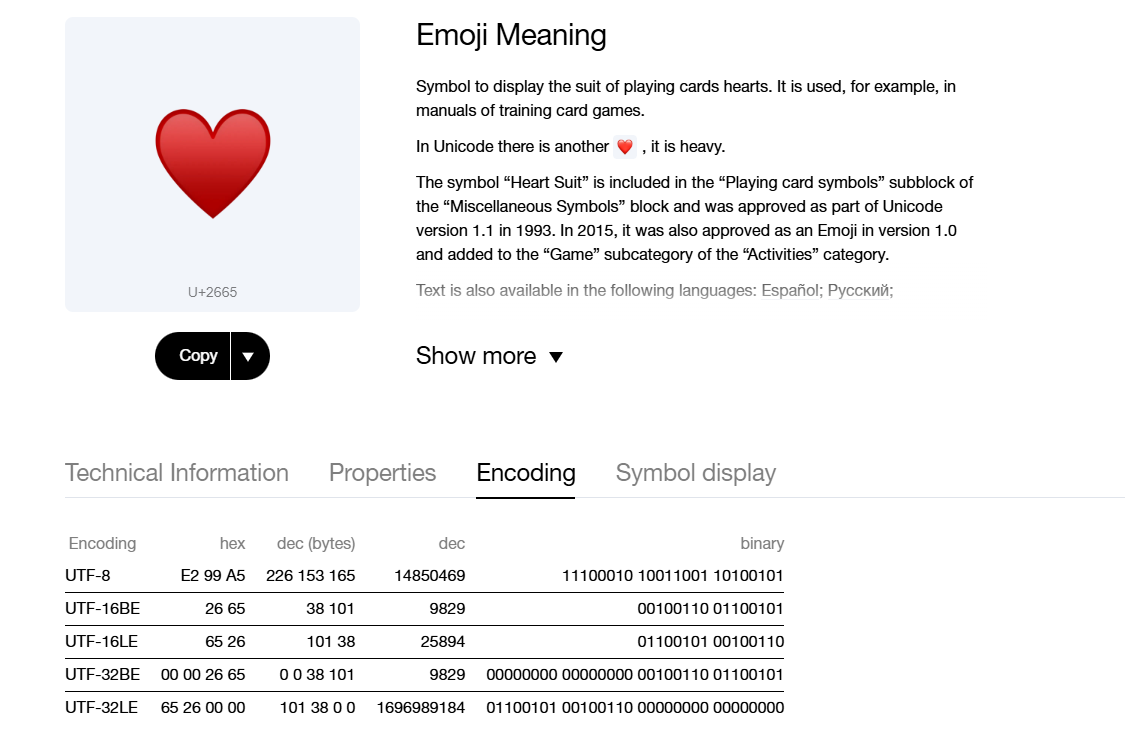
当出现新的字符需要被加入该符号表中时,就继续在表的尾部进行扩充。例如爱心在Unicode符号表中是这样的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号