唯一ID生成_Java实现
最近在接入接口时,需要提供一个客户端生成的唯一ID,因此写了一个简单的唯一ID生成的工具类(有bug请勿使用)
public class IdGenerator{
/**
* CAS计数器
*/
private static AtomicInteger counter = new AtomicInteger(0);
/**
* 通过使得每个线程都有自己的SimpleDateFormat实例,确保线程安全
*/
private static ThreadLocal<SimpleDateFormat> dateFormatThreadLocal = ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyyMMddHHmmss"));
/**
* 前缀
*/
private static String prefix = "ASHE_";
static {
try {
// 可见分布式环境中唯一性依赖于实例节点ip的hashcode值
prefix = prefix + Inet4Address.getLocalHost().hashcode();
} catch (Exception e) {
// ignore
}
}
/**
* 唯一ID
* 格式:固定前缀_年月日时分秒_4位UUID+原子类计数器
*/
public static String getId() {
// currentCounter是当前线程期望值,counter的值是主内存的值(原子类的value被volatile修饰,在主内存中实时读取)
int currentCounter;
// 更新值
int newCounter;
/*
* compareAndSet会比较期望值与主内存中的值是否一致
* 不一致,发生自旋
* 一致,执行后续操作
*/
do {
currentCounter = counter.get();
newCounter = currentCounter + 1;
} while (!counter.compareAndSet(currentCounter, newCounter));
String random = UUID.randomUUID().toString().replaceAll("-", "0").subString(0, 4) + currentCounter;
String timestamp = dateFormatThreadLocal.get().format(new Date());
return String.format("%s_%s_%s", prefix, timestamp, random);
}
}根据代码可以看出为了提供分布式唯一ID,依赖了分布式实例节点IP,时间戳,UUID,CAS计数器组合字符串来确保ID的唯一性。
----------------------------------
不难发现,当不断发生并发请求时,CAS计数器所得出的数字长度将无限递增长度(+上述以及提及——仅适用于服务实例分别部署于不同服务器的特殊场景),因此该设计方案是存在缺陷的。最近看了雪花算法的设计,发现其设计居然和我的这个设计存在很多不谋而合之处(难道我真的是天才?)
在此简要介绍一下雪花算法是如何保证生成ID的唯一性:
时间戳部分+机器ID部分+序列号部分
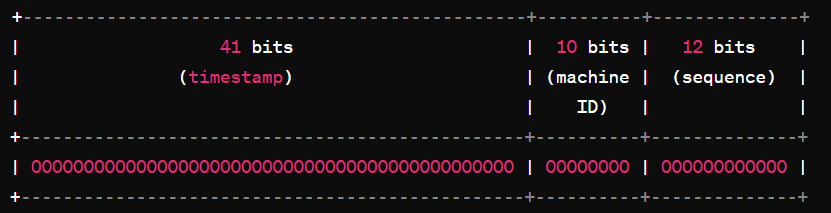
在具体的实现中,这个ID是一个64位的二进制数:
-
时间戳部分 (41 bits):
- 这部分存储自定义的起始时间到当前时间的毫秒数。
- 可以表示约69年的时间范围(2^41 / (1000 * 60 * 60 * 24 * 365) ≈ 69)。
-
机器ID部分 (10 bits):
- 用于表示不同的机器或节点。
- 可以支持最多1024台机器(2^10 = 1024)。
-
序列号部分 (12 bits):
- 用于在同一毫秒内生成多个ID。
- 可以在每毫秒生成最多4096个不同的ID(2^12 = 4096)。
合在一起,这些部分组成了一个64位的唯一ID。每个部分都通过位移和位运算进行组合,从而生成一个唯一且有序的ID。
在雪花算法的具体实现中:
1、考虑了时钟回拨问题。
2、通过机器ID(每个节点分配唯一的机器ID)规避了多个服务实例的并发场景下,生成相同ID的情况。
2、当时间戳变化后,会对序列号进行重置,避免了序列号的无限递增。
3、当时间戳未发生变化,序列号已经递增至阈值,巧妙的利用了循环来等待时间戳发生变化再生成ID(规避序列号超出阈值长度)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号