
MySQL索引的认识
MySQL表的所有记录,是存储在磁盘中的。
当根据非索引字段进行查询时,MySQL 通常需要执行全表扫描,以查找满足查询条件的记录。全表扫描意味着 MySQL 必须逐一检查表中的每一行,以确定哪些行符合查询条件。
全表扫描会导致磁盘 I/O 次数增加,因为 MySQL 需要读取整个表的数据,这可能会导致性能下降,尤其是在大型表上。全表扫描是一种相对低效的查询方式,因为它需要逐行扫描并比较查询条件,而不是根据索引直接定位到匹配的行。
添加索引的最佳实践:
为经常查询的字段添加索引。为条件查询的字段添加索引。为JOIN操作的连接字段添加索引。为聚合函数的输入列添加索引。为分组查询的字段添加索引。为排序查询的字段添加索引。
索引(index)是一种用于提高MySQL查询性能的数据结构,减少了磁盘I/O,无需全表扫描。在数据库插入记录时,会维护对应列(column)的索引,而索引的部分数据会缓存在MySQL的内存中,因此根据索引查询指定的记录时,相比全表扫描的方式会快很多。
MySQL的索引采用B+树作为数据结构,因此B+树就是MySQL索引的具体实现。
认识B+树
根节点
└── 非叶子节点1
│ └── 叶子节点1
│ └── 数据1
│ └── 数据2
│ ...
└── 非叶子节点2
└── 叶子节点2
└── 数据1
└── 数据2
...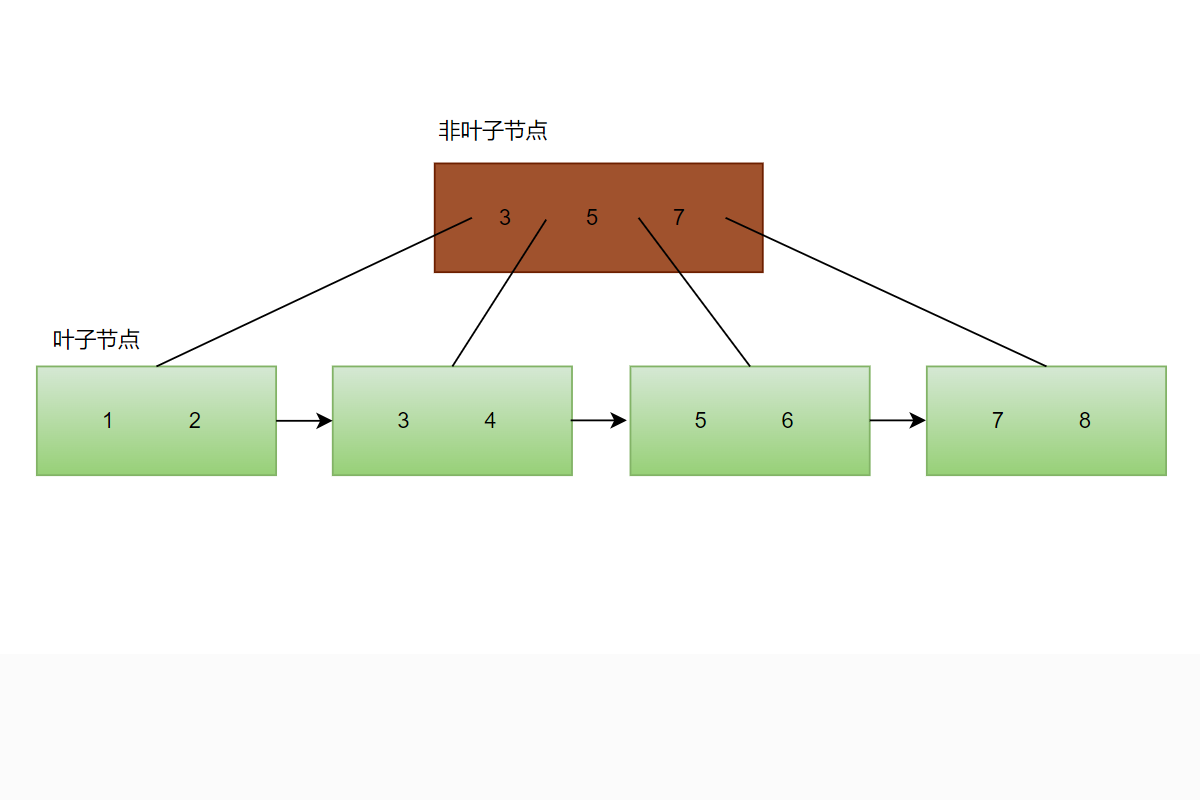
B+树的非叶子节点存储的是储索引字段的值,叶子节点存储多个数据行(数据行内容:索引字段的值和对应的记录指针)。
例如一张table表,其中id字段添加了主键索引,执行查询语句
SELECT id, name FROM table WHERE id = 6;
执行过程:
遍历非叶子节点确定符合条件的非叶子节点(通过比较id = 6与非叶子节点中的索引值来确定)
遍历叶子节点,找到id = 6的数据,读取对应的记录指针(叶子节点中的数据是有序的,切节点之间是相邻的)
MySQL 使用记录指针来查找实际的数据行(记录指针指向了数据行row存储在磁盘中的位置,因此 MySQL 可以快速读取相应的数据行row)
从图中我们可以看到,B+树的每节点通常存储多个数据,而不是只存储一个数据,这有助于降低 B+ 树的高度,在MySQL中,B+树的高度通常为2-3层,因此根据索引查询结果会很快。
在HashMap中,为了提高其查询性能,Java采用了红黑树的数据结构,但是当红黑树要存储的数据量增加时,树的高度会增加,而B+树将节点内的一个数据设计为一组数据,则巧妙地降低了树的高度,从根节点到叶子节点的距离就显著缩短了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号