disruptor解读
本文基于disruptor 3.4.2进行源码解读。
disruptor结构如下图所示:
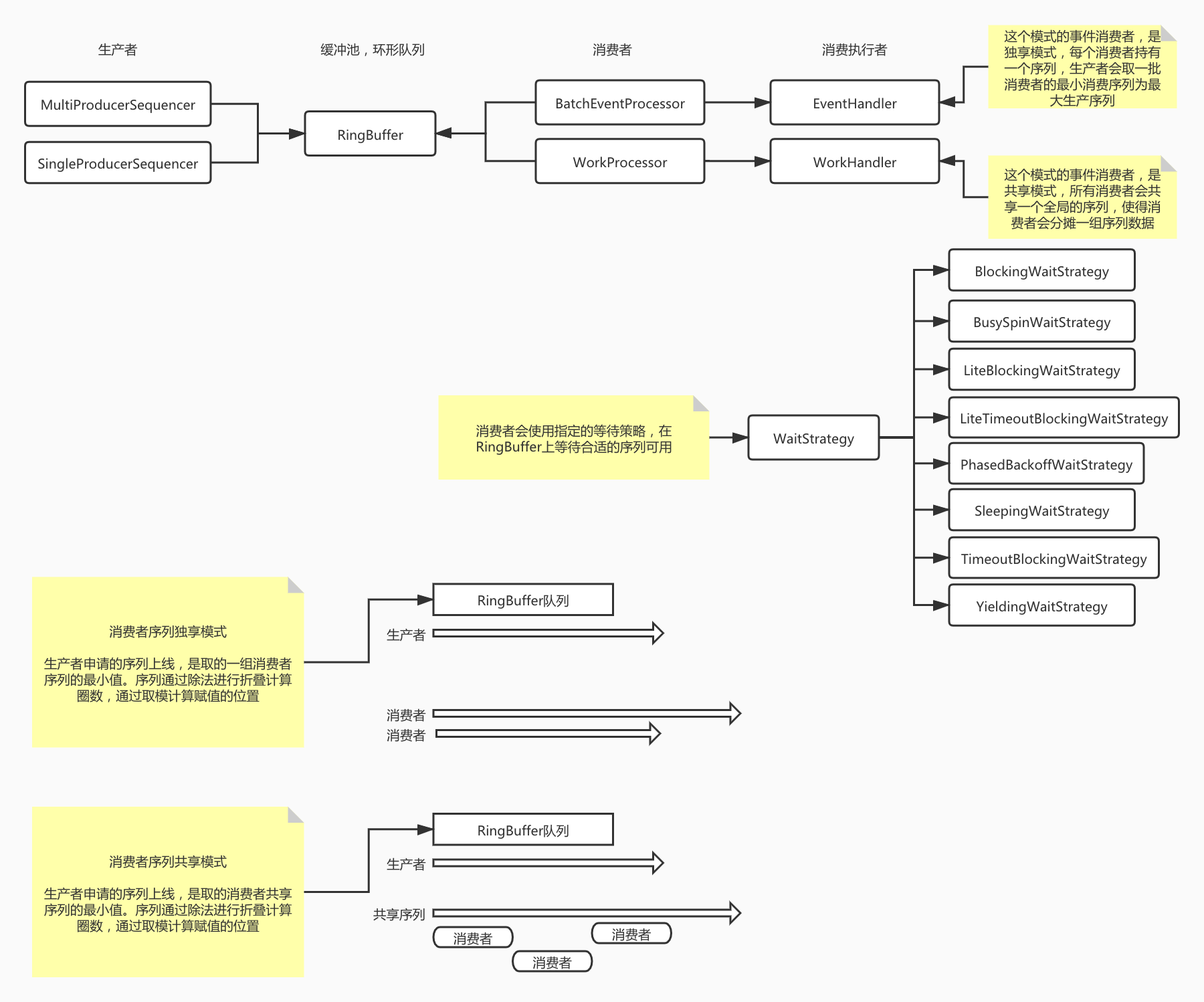
- disruptor如何解决伪共享问题?
- 什么是伪共享?
CPU从主存加载数据到工作内存时,是按缓存行的容量进行加载的。会按照空间临近的原则,加载变量所在缓存行的数据到工作内存。
当多个核心加载不同的变量处于同一个缓存行时,此时发生并发更新会导致工作内存竞争主存中同一个缓存行的写权限。这种情况称之为伪共享。
-
- 有什么办法解决?
因为缓存行一般是64个字节的宽度,故8个long类型的变量就可以填充一个缓存行了。
目前有2种策略来解决这个问题,
第一种:类似disruptor一样,使用继承模式,将关键变量嵌套在中间类上,使得其与其他变量分布在不同的缓存行上。
class LhsPadding { protected long p1, p2, p3, p4, p5, p6, p7; } class Value extends LhsPadding { protected volatile long value; } class RhsPadding extends Value { protected long p9, p10, p11, p12, p13, p14, p15; }
第二种:使用Java8提供的注解,配合JVM参数来实现。
@Contended
-XX:-RestrictContended
具体可以参考:https://www.cnblogs.com/asfeixue/p/11847753.html
- ringBuffer的容量为何要是2的幂次方?
disruptor支持单生产者&多生产者2种模式。
-
- 针对单生产者,这个容量基本就是用来方便快速定位下标用的
- 针对多生产者,这个容量就有2个用处
- 定位下标
- 标记圈数,用于消费者判断当前位置生产者是否有效投放
那基于上述需求,为2的幂次方,可以基于位运算来计算这些,性能比取模(%),整除(/)计算的性能要好。
- 为什么生产者申请到了空间,必须投放数据?
消费者在获取消费位置时,会检查该位置是否有效。
-
- 针对单生产者,其检查是否有效的逻辑是与游标进行比较。而游标受生产者申请空间&投放数据2个动作影响,如果仅申请,不投放,那消费者可能拿到过期非正确的数据。
- 针对多生产者,其检查是根据消费者申请的序列计算的圈数&当前逻辑位存储的圈数进行比较。如果生产者申请了空间,不投放数据,消费者会阻塞在这个位置,无法跳过,或者继续往后进行。
- 单生产者为何不能并发使用?
因为线程不安全。单生产者设计时,就没有考虑并发场景,其使用非同步的变量,非原子的操作进行,整个语义,都在一个线性,无并发的场景下进行的。如果并发使用,会导致数据丢失,覆盖,索引混乱等各种问题。
- StoreStore&StoreLoad的区别?
StoreStore屏障,对应代码:UNSAFE.putOrderedLong,UNSAFE.putOrderedObject,UNSAFE.putOrderedInt,该行为会将数据及时写入内存,但是不会触发可见性同步。
StoreLoad屏障,对应代码:UNSAFE.putLongVolatile,该行为会将数据及时写入内存,并触发可见性同步。
StoreStore的性能大约是StoreLoad的3倍。虽然不保证可见性,但保证及时写入内存,不会刷新工作内存的缓存行数据。这个延迟一般很短,几纳秒左右,对于高并发场景,只要做好check保护,这个延迟换并发性能还是有价值的。
- BlockingQueue&disruptor的RingBuffer区别?
- ArrayBlockingQueue&disruptor的区别
ArrayBlockingQueue内部使用数组,在操作队列头尾元素时,需要竞争锁,使得头尾形成相互热点。其数组没做缓存行填充保护,存在伪共享问题。
disruptor内部也是使用数组,但是生产者消费者的竞争是基于cas竞争序列位置,头尾不会有竞争导致的热点情况。其数组做了缓存行填充保护,其数据所在的缓存行,不会产生伪共享问题。
-
- LinkedBlockingQueue&disruptor的区别
LinkedBlockingQueue内部是使用的链表,其内部使用了2把锁,使得头尾不会相互竞争。但是插入删除元素时,头尾还是竞争热点,只是不相互干扰了。而且,因为链表的缘故,无法利用程序的局部性原理,使得整体的性能表现,要逊色于ArrayBlockingQueue。因为采用链表的缘故,增删节点会带来GC的问题。
disruptor同上。因为采用数组的缘故,disruptor本身占用的数组不受GC影响。
- SIMO & MIMO模型的区别?
disruptor支持单生产者,多生产者等2种模式。也支持共享序列&独享序列的event模式&work模式。
event模式&work模式的区别,在于序列是独享还是共享。在序列独享的情况下,每一个eventHandler都注册一个追踪序列到ringBuffer身上,生产者在检测可以使用的序列上限时,会取这一批追踪序列的最小值作为当前生产周期的最大值上限。
work模式,则会共享序列,那这种模式下,注册到ringBuffer上的追踪序列只有一个,所有的workHandler都共享这一个序列,每一个workHandler都会从序列中提取到一部分数据进行消费。
- disruptor的MIMO&批量消费?
有这样一种场景,业务存在一种整点批量抢券的场景,无论抢券成功与否,都需要及时反馈用户抢券结果。因为提前预热以及优惠力度较足的缘故,抢券接口的QPS会比较大。
有很多种解决思路,比如:
抢券动作直接进MQ,然后单独的线程消费这一批消息。这个要求业务方能接受一定的延迟。因为一般消息的消费都是逐条消费,可以改造为批量消费的模式,通过在业务维度的批量整合提升性能。
抢券动作直接进入内存,然后基于内存队列缓存抢券行为,然后再使用线程池消费这一组行为。在消费的时候还是基于业务维度进行批量整合,提升整体的QPS性能。这种模式相对能及时反馈状态,但是内存容量有限,需要根据QPS容量来规划集群规模。同时会有一定的超时失败的概率。
那基于disruptor框架,现有的BatchEventProcessor&WorkProcessor,都是逐个消息消费的,如何支持批量消费呢?参考这俩实现,自定义一个新的即可。
BatchEventProcessor是取到一个最大可用的序列值,然后逐个投递给eventHandler进行消费处理。完全可以扩展为一定规模上限的批量投递。
WorkProcessor是取到一个最大可用的序列值,然后逐个竞争后,在投递给workHandler进行消费处理。同样可以扩展为一定规模上限的批量投递消费。
基于work模式的批量实现代码如下:
public interface BatchWorkHandler<T>
{
/**
* Callback to indicate a unit of work needs to be processed.
*
* @param eventList published to the {@link RingBuffer}
* @throws Exception if the {@link WorkHandler} would like the exception handled further up the chain.
*/
void onEvent(List<T> eventList) throws Exception;
}
public class EventBatchConsumer implements BatchWorkHandler {
@Override
public void onEvent(List eventList) throws Exception {
System.err.println(Thread.currentThread().getName() + "-" + JSON.toJSONString(eventList));
Thread.sleep(150);
}
}
import com.lmax.disruptor.*;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.atomic.AtomicBoolean;
public class BatchWorkProcessor<T> implements EventProcessor {
private final AtomicBoolean running = new AtomicBoolean(false);
private final long maxBatchNum;
private final Sequence sequence = new Sequence(Sequencer.INITIAL_CURSOR_VALUE);
private final RingBuffer<T> ringBuffer;
private final SequenceBarrier sequenceBarrier;
private final BatchWorkHandler<? super T> batchWorkHandler;
private final ExceptionHandler<? super T> exceptionHandler;
private final Sequence workSequence;
private final TimeoutHandler timeoutHandler;
/**
* Construct a {@link WorkProcessor}.
*
* @param ringBuffer to which events are published.
* @param sequenceBarrier on which it is waiting.
* @param batchWorkHandler is the delegate to which events are dispatched.
* @param exceptionHandler to be called back when an error occurs
* @param workSequence from which to claim the next event to be worked on. It should always be initialised
* as {@link Sequencer#INITIAL_CURSOR_VALUE}
* @param maxBatchNum 批次最大数量
*/
public BatchWorkProcessor(
final RingBuffer<T> ringBuffer,
final SequenceBarrier sequenceBarrier,
final BatchWorkHandler<? super T> batchWorkHandler,
final ExceptionHandler<? super T> exceptionHandler,
final Sequence workSequence,
final long maxBatchNum) {
this.ringBuffer = ringBuffer;
this.sequenceBarrier = sequenceBarrier;
this.batchWorkHandler = batchWorkHandler;
this.exceptionHandler = exceptionHandler;
this.workSequence = workSequence;
this.maxBatchNum = maxBatchNum;
if (maxBatchNum < 1) {
throw new IllegalArgumentException("最小批次数量不能 < 1!");
}
timeoutHandler = (batchWorkHandler instanceof TimeoutHandler) ? (TimeoutHandler) batchWorkHandler : null;
}
@Override
public Sequence getSequence()
{
return sequence;
}
@Override
public void halt() {
running.set(false);
sequenceBarrier.alert();
}
@Override
public boolean isRunning()
{
return running.get();
}
/**
* It is ok to have another thread re-run this method after a halt().
*
* @throws IllegalStateException if this processor is already running
*/
@Override
public void run() {
if (!running.compareAndSet(false, true)) {
throw new IllegalStateException("Thread is already running");
}
sequenceBarrier.clearAlert();
notifyStart();
long cachedAvailableSequence = Long.MIN_VALUE;
SequenceContext sequenceContext = new SequenceContext();
processedSequence(sequenceContext);
while (true) {
try {
if (cachedAvailableSequence >= sequenceContext.getNextSequence()) {
List eventList = new ArrayList((int)sequenceContext.getBatchNum());
//申请到的整段,都是可以消费的
for (long index = sequenceContext.getStartIndex(); index <= sequenceContext.getNextSequence(); index++) {
T event = ringBuffer.get(index);
eventList.add(event);
}
if (!eventList.isEmpty()) {
batchWorkHandler.onEvent(eventList);
}
//申请的序列范围使用完成,申请新的序列
processedSequence(sequenceContext);
} else {
cachedAvailableSequence = sequenceBarrier.waitFor(sequenceContext.getNextSequence());
}
} catch (final TimeoutException e) {
notifyTimeout(sequence.get());
processedSequence(sequenceContext);
} catch (final AlertException ex) {
if (!running.get()) {
break;
}
processedSequence(sequenceContext);
} catch (final Throwable ex) {
// handle, mark as processed, unless the exception handler threw an exception
exceptionHandler.handleEventException(ex, sequenceContext.getNextSequence(), null);
processedSequence(sequenceContext);
}
}
notifyShutdown();
running.set(false);
}
/**
* 在申请下来下一阶段序列时,该序列值前批量数量值的队列内容一定是可读且未读的
* @param sequenceContext
*/
private void processedSequence(SequenceContext sequenceContext) {
long nextSequence;
long batchNum;
long startIndex;
do {
long nowSequence = workSequence.get();
long nowMaxSequence = sequenceBarrier.getCursor();
//最小为1,防止小流量场景下,死等最大容量批次。给一个较大值,并不会导致消费者跑到提供者前面,因为外层使用时有保护
batchNum = Math.min(maxBatchNum, (nowMaxSequence > nowSequence) ? (nowMaxSequence - nowSequence) : 1);
nextSequence = nowSequence + batchNum;
startIndex = nowSequence;
sequence.set(startIndex);
} while (!workSequence.compareAndSet(startIndex, nextSequence));
if (startIndex < 0) {
//因为游标是从-1开始,ringBuffer是从0开始的,故开始位置设置为0
sequenceContext.setStartIndex(0);
} else {
//因为workSequence之前get到的sequence已经被消费了,故需要从之前记录位置往前挪一位,防止重复消费
sequenceContext.setStartIndex(startIndex + 1);
}
sequenceContext.setBatchNum(batchNum);
sequenceContext.setNextSequence(nextSequence);
}
@Data
@NoArgsConstructor
private static class SequenceContext {
private long startIndex = 0L;
private long nextSequence;
private long batchNum = -1L;
}
private void notifyTimeout(final long availableSequence) {
try {
if (timeoutHandler != null) {
timeoutHandler.onTimeout(availableSequence);
}
} catch (Throwable e) {
exceptionHandler.handleEventException(e, availableSequence, null);
}
}
private void notifyStart() {
if (batchWorkHandler instanceof LifecycleAware) {
try {
((LifecycleAware) batchWorkHandler).onStart();
} catch (final Throwable ex) {
exceptionHandler.handleOnStartException(ex);
}
}
}
private void notifyShutdown() {
if (batchWorkHandler instanceof LifecycleAware) {
try {
((LifecycleAware) batchWorkHandler).onShutdown();
} catch (final Throwable ex) {
exceptionHandler.handleOnShutdownException(ex);
}
}
}
}
测试代码如下:
class BatchWorkProcessorTest { @Test public void test0() throws IOException { Sequence workSequence = new Sequence(Sequencer.INITIAL_CURSOR_VALUE); RingBuffer<ValueItem> ringBuffer = RingBuffer.createMultiProducer(() -> new ValueItem(), 64, new YieldingWaitStrategy()); ringBuffer.addGatingSequences(workSequence); ExceptionHandler exceptionHandler = new ExceptionHandlerWrapper<>(); SequenceBarrier sequenceBarrier = ringBuffer.newBarrier(new Sequence[0]); ExecutorService consumer = Executors.newFixedThreadPool(4); for (int num = 0; num < 2; num ++) { BatchWorkProcessor batchWorkProcessor = new BatchWorkProcessor(ringBuffer, sequenceBarrier, new EventBatchConsumer(), exceptionHandler, workSequence, 10); consumer.execute(batchWorkProcessor); } ExecutorService producer = Executors.newFixedThreadPool(10); for (int index = 0; index < 500; index++) { ValueItem value = new ValueItem(); value.setNum(index); producer.execute(() -> ringBuffer.publishEvent((event, sequence, arg0) -> event.setNum(arg0.getNum()), value)); } System.in.read(); } @Data @NoArgsConstructor public static class ValueItem { private Integer num; } }
work批量的模式下,可以基于压测瓶颈进行并发业务维度聚合,可以指定并发数,一次最大批次处理数量等,极大的提升处理性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号