泰坦尼克之灾是Kaggle上的一个入门级比赛项目,主要是利用监督式机器学习,对样本进行训练,建立分类模型,对未标记样本进行分类。
虽然这是一个“过时”的项目,但自己一步一步的做完,还是很有意义的。通过做项目,主要有3方面作用:
1.验证理论知识,加深对理论的理解。
2.掌握常用工具的使用,增加工具的熟练度。
3.了解项目完整流程,提高工程化思想。
我已经将代码放到了我的Github上,会持续更新,逐步优化。
基于模块化的思想,我在编写程序时,将功能分到多个文件中,以后版本更新会尽量保持模块的稳定(主程序是main.py):
v0.1版本,使用sk-learn建立基本的模型,使用的特征有:Pclass,Sex,Age,Fare以及类别标签Survived。
其中对于Sex将其进行one-hot编码,对于Age中的空值使用中位数填充。为了方便进行对比,本文仅使用逻辑回归(LR)模型进行训练。
作为最基本的模型,主要的目标是能够正常运行,因此本版本中使用的LR模型并未进行超参数调整,使用常规设置。
使用3折交叉验证,对训练样本的精度进行评估:[0.78787879 0.79124579 0.79124579]
最终上传到Kaggle上,准确率为:75.598%。
虽然准确率不是很高,但是此版本已经搭建好了基本的结构,为模型的进一步优化提供了良好的支撑。

v0.2版本,在v1.0的基础上增加了一个新特征Title,这个属性是从Name字段提取出来的,提取出信息后,转化为一个新的离散属性,包含5个类别:
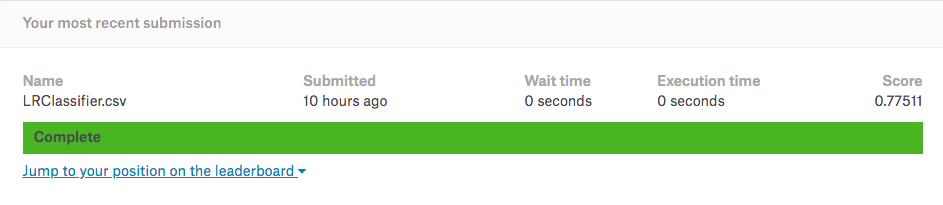
"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5,增加了这一个新的特征后,继续使用LR模型进行预测,准确率为77.511%,比之前提高了1.9%。
v0.3版本,参考Kaggle上的一个Kernel,在特征工程方面总共进行了如下的处理:
1.移除'Ticket'与'Cabin'两个属性。
2.将'Name'属性进行内容提取,转化为新属性'Title',包含5个类别:'Mr','Miss','Mrs','Master','Rare'。
3.将'Sex'属性从object类型(male,female)转化为数值型(0,1)。
4.使用中位数填充'Age'属性的空值。
5.将填充后的连续数值型的'Age'属性,进行离散化处理,分为5类:'<=16','>16 and <=32','>32 and <=48','>48 and <=64','>=64'。
6.将'SibSp'与'Parch'这两个属性值相加,产生新属性'FamilySize'。
7.根据'FamilySize'的数值产生新属性'IsAlone',表示是否是单独乘船。
8.将'Age'与'Pclass'两个属性相乘,产生新属性'Age*Class'。
9.将'Embarked'属性中的空值,使用出现次数最多的值'S'进行填充。
10.将'Embarked'属性进行数值化:S->0,C->1,Q->2。
11.将'Fare'属性中的空值,使用中位数填充。
12.将填充后的'Fare'属性进行离散化处理,分为4类:'<=7.91','>7.91 and <=14.454','>14.454 and <=31','>31'。
经过以上12种特征处理之后,分别使用9种模型进行训练,按照准确率由高到低进行排序:
Random Forrest :RandomForestClassifier(n_estimators=100)#随机森林
Decision Tree :DecisionTreeClassifier()#决策树
KNN or k-Nearest Neighbors :KNeighborsClassifier(n_neighbors = 3)#K近邻
Support Vector Machines :SVC()#支持向量机
Logistic Regression :LogisticRegression()#逻辑回归
Linear SVC :LinearSVC()#线性支持向量机
Stochastic Gradient Decent :SGDClassifier()#随机梯度下降
Perceptron :Perceptron()#感知机
Naive Bayes classifier :GaussianNB()#朴素贝叶斯
训练完毕后,对测试集进行预测并上传到Kaggle上进行检验,逻辑回归的准确率为76.076%,介于v0.1与v0.2之间。

而使用效果最好的决策树和随机森林模型,准确率都可以达到78.468%,比v0.2提高了0.96%,是目前最高的准确率。

虽然只是"照猫画虎"的比划了一下,但完成这个项目的过程中还是有一些心得体会的,现在做一个总结吧:
1.想要提升模型的效果,既需要敏锐的观察和仔细的分析,也需要多次的尝试和反复的验证。
2.特征工程与模型的选择密切相关,在进行数据处理的时候,可通过评估不同的模型寻找最佳特征。
3.从前辈们训练模型的经验中,可以选择出效果比较好的几种模型。
3.1逻辑回归是使用比较广泛的,执行效率不错,也比较稳定,可以作为基准模型。
3.2随机森林泛化性比较好,往往是最有可能达到最佳效果的模型,一般考虑作为最终模型,进一步微调。
3.3其他模型可能根据具体的数据而有不同的表现,在传统机器学习常用的分类模型中,总体而言:
3.3.1RandomForest多数情况优于DecisionTree,SVM多数情况优于Linear SVM。
3.3.2LR多数情况优于SGD,但SGD比较适合处理大数据集和稀疏型的数据。
3.3.3KNN是基于实例而非基于模型,与之前几种的原理不同,其表现不太确定。
3.3.4Naive Bayes是基于概率计算的,多数情况下表现不够理想。
3.3.5Perceptron是ANN的基本结构,对于一般线性分类优势不大,而对于复杂的非线性问题,可以考虑DNN,CNN,RNN等深层网络结构。
3.4因此,如果感觉9个模型太多,可以选择以下4个作为代表:LR、SVM、RandomForest、KNN,基本就够了。
4.如果数据量比较大,可以抽取出一个用于调试的小样本,减少数据加载和训练的时间。如果问题比较复杂,就直接使用Deep Learning吧。
5.机器学习流程不一定需要过多考虑设计模式,但"划分模块"、"单元测试"、"版本控制"等软件工程方法,有助于代码的复用,减少Bug,提高工作效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号