【学习笔记】用numpy实现一个简单的MLP
【学习笔记】用numpy实现一个简单的MLP
之前我用numpy实现了多项式逻辑回归,这次打算用同样的数据在MLP上试试
模型结构很简单,就是一个双层的MLP,输入是二维的向量,隐藏层是由三个神经元组成的全连接层(激活函数是tanh),最后通过logistic回归输出类别\(\hat y\)
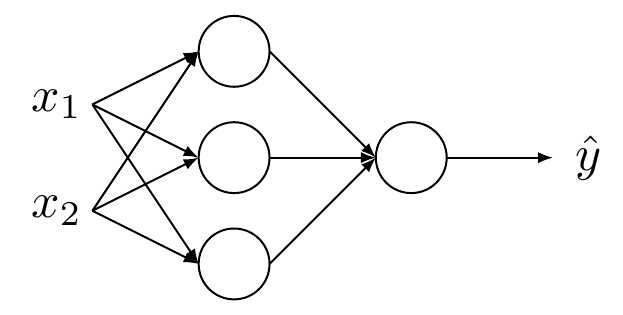
正向及反向传播公式如下:
正向传播
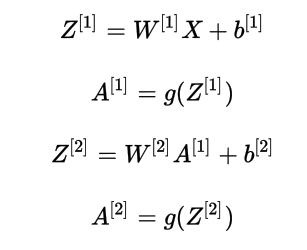
反向传播
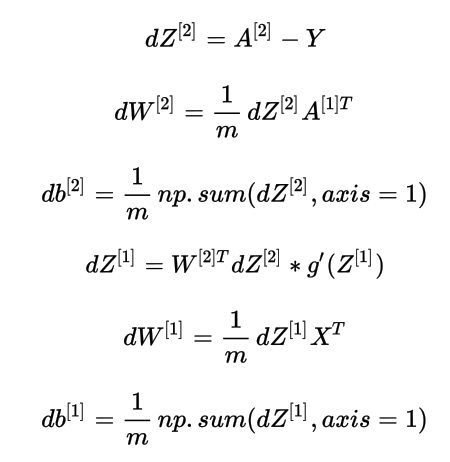
然后是代码实现:
MLP:
# MLP
learning_rate=0.9
k=1e-3
batch_size=32
epoch_num=200
input_size=2
output_size=3
def sigmoid(x):
return 1/(1+exp(-x))
def forward(x):
w1=mp['w1']
b1=mp['b1']
w2=mp['w2']
b2=mp['b2']
# b1*=0
# b2*=0
z1=w1@x+b1
a1=tanh(z1)
z2=w2@a1+b2
a2=sigmoid(z2)
mp['z1']=z1
mp['a1']=a1
mp['z2']=z2
mp['a2']=a2
return a2
def compute_loss(y):
w1=mp['w1']
w2=mp['w2']
a2=mp['a2']
return np.mean(-(y*log(a2)+(1-y)*log(1-a2)))+k*(np.linalg.norm(w1,ord=1)+np.linalg.norm(w2,ord=1))
def backward(x,y):
w1=mp['w1']
b1=mp['b1']
w2=mp['w2']
b2=mp['b2']
z1=mp['z1']
a1=mp['a1']
z2=mp['z2']
a2=mp['a2']
dz2=a2-y
dw2=dz2@a1.T/x.shape[1]
db2=np.mean(dz2,axis=1,keepdims=True)
da1=w2.T@dz2
dz1=(1-a1*a1)*da1
dw1=dz1@x.T/x.shape[1]
db1=np.mean(dz1,axis=1,keepdims=True)
w2-=learning_rate*dw2+k*sign(w2)
b2-=learning_rate*db2
w1-=learning_rate*dw1+k*sign(w1)
b1-=learning_rate*db1
mp['w1']=w1
mp['b1']=b1
mp['w2']=w2
mp['b2']=b2
def mlp_fit(X,Y):
global mp
mp={}
XX=X.copy()
YY=Y.copy()
w1=(random.randn(input_size,output_size)*0.01).T
b1=(random.randn(1,output_size)*0.01).T
w2=(random.randn(output_size,1)*0.01).T
b2=(random.randn(1,1)*0.01).T
mp['w1']=w1
mp['b1']=b1
mp['w2']=w2
mp['b2']=b2
I=list(range(len(XX)))
LOSS=[]
for epoch in range(epoch_num):
loss=0
random.shuffle(I)
XX=XX[I]
YY=YY[I]
for i in range(0,len(XX),batch_size):
x=XX[i:i+batch_size].T
y=YY[i:i+batch_size].reshape(1,-1)
forward(x)
loss+=compute_loss(y)
backward(x,y)
LOSS.append(loss)
# print('epoch',epoch,':')
# print(mp['w1'])
# print(mp['b1'])
return LOSS
def mlp_predict(X):
return np.where(forward(X.T)>0.5,1,0).T
数据标准化:
# StandardScaler
def scaler_fit(X):
global mean,scale
mean=X.mean(axis=0)
scale=X.std(axis=0)
scale[scale<np.finfo(scale.dtype).eps]=1.0
def scaler_transform(X):
return (X-mean)/scale
训练及预测:
def train(X,Y):
XX=X.copy()
scaler_fit(XX)
XX=scaler_transform(XX)
LOSS=mlp_fit(XX,Y)
plt.plot(list(range(len(LOSS))),LOSS,color='r')
plt.show()
def predict(X):
XX=scaler_transform(X)
return mlp_predict(XX)
def plot_decision_boundary(X,Y):
x0_min,x0_max=X[:,0].min()-1,X[:,0].max()+1
x1_min,x1_max=X[:,1].min()-1,X[:,1].max()+1
m=500
x0,x1=np.meshgrid(
np.linspace(x0_min,x0_max,m),
np.linspace(x1_min,x1_max,m)
)
XX=np.c_[x0.ravel(),x1.ravel()]
Y_pred=predict(XX)
Z=Y_pred.reshape(x0.shape)
plt.contourf(x0,x1,Z,cmap=plt.cm.Spectral)
plt.scatter(X[:,0],X[:,1],c=Y,cmap=plt.cm.Spectral)
plt.show()
生成训练数据:
def generate_data(F,l,r,n,y):
x=np.linspace(l,r,n)
X=np.column_stack((x,F(x)))
Y=np.repeat(y,n)
return X,Y
主程序:
random.seed(114514)
data_size=200
X1,Y1=generate_data(lambda x:x**2+2*x-2+random.randn(data_size)*0.8,-3,1,data_size,0)
X2,Y2=generate_data(lambda x:-x**2+2*x+2+random.randn(data_size)*0.8,-1,3,data_size,1)
X=np.vstack((X1,X2))
Y=np.hstack((Y1,Y2))
train(X,Y)
plot_decision_boundary(X,Y)
loss曲线及判别界面:
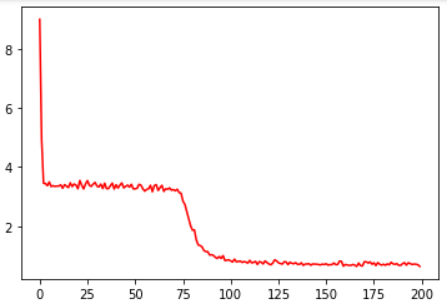
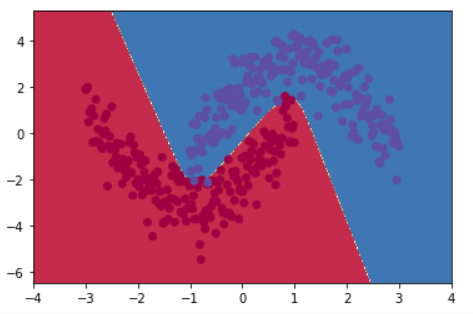
自己的一些思考:
1.关于全连接层的作用,我个人感觉每个神经元就像是一块“挡板”,将两类点从左右两侧分隔开,就像上述分类结果中有三条折线,分别对应三个挡板,而激活函数tanh的作用就是将挡板两侧的点往外推,挡板的能量越高(向量范数越大),点受到的作用力就越强,被推的距离就越大
为形象理解,我绘制了原数据通过全连接层之后转化为三维空间中的点的分布情况,代码如下:
fig=plt.figure()
ax3=plt.axes(projection='3d')
ax3.set_xlabel("X")
ax3.set_ylabel("Y")
ax3.set_zlabel("Z")
w1=mp['w1']
b1=mp['b1']
w2=mp['w2']
b2=mp['b2']
XX=scaler_transform(X)
z1=w1@XX.T+b1
a1=tanh(z1)
z2=w2@a1+b2
a2=sigmoid(z2)
Z=a1
ax3 = plt.axes(projection='3d')
ax3.set_xlabel("X")
ax3.set_ylabel("Y")
ax3.set_zlabel("Z")
ax3.scatter(Z[0],Z[1],Z[2],c=Y,cmap=plt.cm.Spectral)
ax3.view_init(90,0)
plt.show()
ax3 = plt.axes(projection='3d')
ax3.set_xlabel("X")
ax3.set_ylabel("Y")
ax3.set_zlabel("Z")
ax3.scatter(Z[0],Z[1],Z[2],c=Y,cmap=plt.cm.Spectral)
ax3.view_init(0,0)
plt.show()
ax3 = plt.axes(projection='3d')
ax3.set_xlabel("X")
ax3.set_ylabel("Y")
ax3.set_zlabel("Z")
ax3.scatter(Z[0],Z[1],Z[2],c=Y,cmap=plt.cm.Spectral)
ax3.view_init(0,90)
plt.show()
ax3 = plt.axes(projection='3d')
ax3.set_xlabel("X")
ax3.set_ylabel("Y")
ax3.set_zlabel("Z")
ax3.scatter(Z[0],Z[1],Z[2],c=Y,cmap=plt.cm.Spectral)
xx=np.arange(-1,1,0.01)
yy=np.arange(-1,1,0.01)
X2,Y2=np.meshgrid(xx, yy)
Z2=(w2[0,0]*X2+w2[0,1]*Y2+b2[0,0])/(-w2[0,2])
ax3.plot_surface(X2,Y2,Z2,cmap='rainbow')
plt.show()
绘制结果:
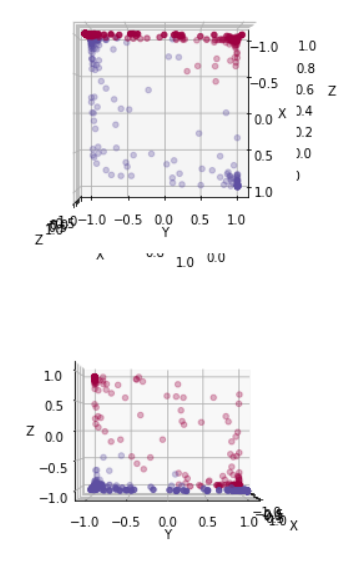
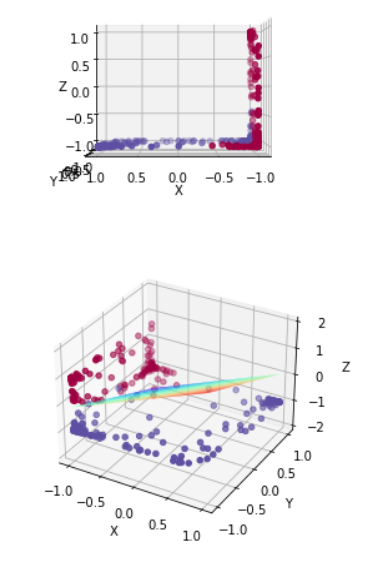
可以看出,tanh函数将两类点分别拉向z=-1及x=-1侧,从而使得两类点可以被线性划分(通过Logistic回归)
2.第75次训练时loss曲线突然急剧下降,这点非常有意思,自己暂时没有搞清楚原因,留待以后探究
3.对w初始化的时候,各个神经元的初始权重要互不相同,否则后面的梯度都是一样的,可能就无法收敛了(随机失活或许也可以,不过我还没试过)
参考资料:深度学习PyTorch极简入门教程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号