【学习笔记】用numpy实现多项式逻辑回归(PolynomialLogisticRegression)
多项式逻辑回归就是在逻辑回归的基础上将高次项作为特征加进去,以实现高维特征的提取
一、模型构建
多项式逻辑回归模型是由三个子模型组成:
(1)添加多项式特征
(2)标准化
(3)逻辑回归
添加多项式特征
将各个特征之间相乘得到新的特征,比如原来的特征是\([x_0,x_1]\)
二次多项式特征是\([1,x_0,x_1,x_0^2,x_0x_1,x_1^2]\)
三次多项式特征是\([1,x_0,x_1,x_0^2,x_0x_1,x_1^2,x_0^3,x_0^2x_1,x_0x_1^2,x_1^3]\)
def poly_transform(X):
XX=X.T
ret=[np.repeat(1.0,XX.shape[1]),XX[0],XX[1]]
for i in range(2,degree+1):
for j in range(0,i+1):
ret.append(XX[0]**(i-j)*XX[1]**j)
return np.array(ret).T
超参数设置:
degree=3
标准化
将样本缩放到均值为0,标准差为1,变换公式为\(\Large x=\frac{x-\mu}{\sigma}\)
坑点:
(1)标准差有可能为0,转换的时候会出现分母为0的情况,需要将其转化为非零的数
(2)只需要对训练数据fit一遍,测试的时候按照训练时的均值和标准差变换就行了,否则会出现偏差
def scaler_fit(X):
global mean,scale
mean=X.mean(axis=0)
scale=X.std(axis=0)
scale[scale<np.finfo(scale.dtype).eps]=1.0
def scaler_transform(X):
return (X-mean)/scale
逻辑回归
模型的核心部分,训练过程由前向传播、计算损失和反向传播三部分构成:
前向传播
由输入数据计算输出概率\(p(x)\)
def sigmoid(x):
return 1/(1+exp(-x))
def forward(x):
return sigmoid(w@x.T)
从意义上来说\(p(x)\)代表\(x\)被判别为第1类的概率
按理说可以再加上一个偏置项\(b\),对有些数据效果可能会更好一些
计算损失
假设上一步已经得到了训练数据\(x\)的概率\(p=p(x)\)
对于单个训练数据\([p,y]\)损失函数为:
采用MBGD,一次取多个训练数据,对于一组具有m个训练数据的batch有:
为防止\(w\)的权值过度膨胀(因为\(w\)各项权值的绝对值越大,\(p\)的值越接近0或1),加入L1正则项,因此最终的损失函数为:
def compute_loss(p,y):
return np.mean(-(y*log(p)+(1-y)*log(1-p)),axis=0)+k*np.linalg.norm(w,ord=1)
反向传播+更新参数
计算损失函数\(J\)对\(w\)各个权值的偏导数
为方便思考,先只考虑单个数据\([p,y]\)时的情况:
因此有
对于m个训练数据:
加入正则项之后:
写成向量的形式就是:
在反向传播的同时更新参数,即:
\(\alpha\)代表学习率
def backward(p,x,y):
global w
w-=learning_rate*np.mean((p-y).reshape(-1,1)*x,axis=0)+k*sign(w)
训练
采用MBGD进行训练,设学习率为learning_rate,正则项权重为k,一个批次的训练数据规模为batch_size,迭代轮次为epoch_num:
def logistic_fit(X,Y):
global w
XX=X.copy()
YY=Y.copy()
w=random.randn(XX[0].shape[0])*0.01
I=list(range(len(XX)))
LOSS=[]
for epoch in range(epoch_num):
random.shuffle(I)
XX=XX[I]
YY=YY[I]
for i in range(0,len(XX),batch_size):
x=XX[i:i+batch_size]
y=YY[i:i+batch_size]
p=forward(x)
loss=compute_loss(p,y)
LOSS.append(loss)
backward(p,x,y)
return LOSS
超参数设置:
learning_rate=0.9
k=0.005
batch_size=32
epoch_num=50
二、生成训练数据
生成训练数据集\(X\)和\(Y\),其中\(X=\{x\}\),\(Y=\{y\}\),\(x=[x_0,F(x_0)]\),\(x_0∈[l,r]\),标签为\(y\),数据集大小为n
def generate_data(F,l,r,n,y):
x=np.linspace(l,r,n)
X=np.column_stack((x,F(x)))
Y=np.repeat(y,n)
return X,Y
三、模型训练及预测
训练
输入训练样本\((X,Y)\),更新scaler及logisticregression的参数并绘制出loss曲线,无返回值
def train(X,Y):
XX=poly_transform(X)
scaler_fit(XX)
XX=scaler_transform(XX)
LOSS=logistic_fit(XX,Y)
plt.plot(list(range(len(LOSS))),LOSS,color='r')
plt.show()
预测
输入预测样本\(X\),返回预测结果\(\hat Y\)
def predict(X):
XX=scaler_transform(poly_transform(X))
return logistic_predict(XX)
绘制判别界面
输入预测样本\((X,Y)\),散点图、及判别界面
def plot_decision_boundary(X,Y):
global predY1
x0_min,x0_max=X[:,0].min()-1,X[:,0].max()+1
x1_min,x1_max=X[:,1].min()-1,X[:,1].max()+1
m=500
x0,x1=np.meshgrid(
np.linspace(x0_min,x0_max,m),
np.linspace(x1_min,x1_max,m)
)
XX=np.c_[x0.ravel(),x1.ravel()]
Y_pred=predict(XX)
Z=Y_pred.reshape(x0.shape)
plt.contourf(x0,x1,Z,cmap=plt.cm.Spectral)
plt.scatter(X[:,0],X[:,1],c=Y,cmap=plt.cm.Spectral)
plt.show()
四、主程序
random.seed(114514)
data_size=200
X1,Y1=generate_data(lambda x:x**2+2*x-2+random.randn(data_size)*0.8,-3,1,data_size,0)
X2,Y2=generate_data(lambda x:-x**2+2*x+2+random.randn(data_size)*0.8,-1,3,data_size,1)
X=np.vstack((X1,X2))
Y=np.hstack((Y1,Y2))
train(X,Y)
plot_decision_boundary(X,Y)
loss曲线:
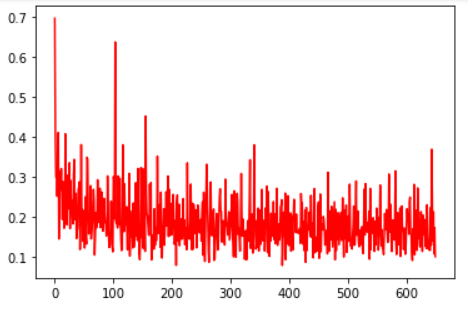
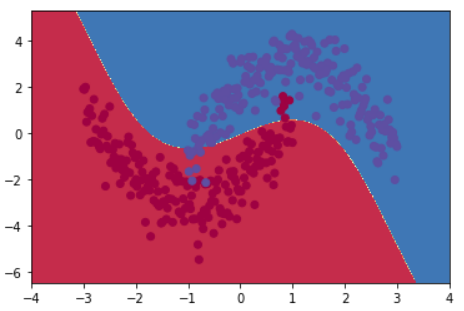
判别界面:
五、完整代码
导入依赖包
import numpy as np
from numpy import exp,log,sign,random
from matplotlib import pyplot as plt
模型构建
# LogisticRegression
learning_rate=0.9
k=0.005
batch_size=32
epoch_num=50
def sigmoid(x):
return 1/(1+exp(-x))
def forward(x):
return sigmoid(w@x.T)
def compute_loss(p,y):
return np.mean(-(y*log(p)+(1-y)*log(1-p)),axis=0)+k*np.linalg.norm(w,ord=1)
def backward(p,x,y):
global w
w-=learning_rate*np.mean((p-y).reshape(-1,1)*x,axis=0)+k*sign(w)
def logistic_fit(X,Y):
global w
XX=X.copy()
YY=Y.copy()
w=random.randn(XX[0].shape[0])*0.01
I=list(range(len(XX)))
LOSS=[]
for epoch in range(epoch_num):
random.shuffle(I)
XX=XX[I]
YY=YY[I]
for i in range(0,len(XX),batch_size):
x=XX[i:i+batch_size]
y=YY[i:i+batch_size]
p=forward(x)
loss=compute_loss(p,y)
LOSS.append(loss)
backward(p,x,y)
return LOSS
def logistic_predict(X):
return np.where(forward(X)>0.5,1,0)
# StandardScaler
def scaler_fit(X):
global mean,scale
mean=X.mean(axis=0)
scale=X.std(axis=0)
scale[scale<np.finfo(scale.dtype).eps]=1.0
def scaler_transform(X):
return (X-mean)/scale
# PolynomialFeatures
degree=3
def poly_transform(X):
XX=X.T
ret=[np.repeat(1.0,XX.shape[1]),XX[0],XX[1]]
for i in range(2,degree+1):
for j in range(0,i+1):
ret.append(XX[0]**(i-j)*XX[1]**j)
return np.array(ret).T
模型训练及预测
def train(X,Y):
XX=poly_transform(X)
scaler_fit(XX)
XX=scaler_transform(XX)
LOSS=logistic_fit(XX,Y)
plt.plot(list(range(len(LOSS))),LOSS,color='r')
plt.show()
def predict(X):
XX=scaler_transform(poly_transform(X))
return logistic_predict(XX)
def plot_decision_boundary(X,Y):
global predY1
x0_min,x0_max=X[:,0].min()-1,X[:,0].max()+1
x1_min,x1_max=X[:,1].min()-1,X[:,1].max()+1
m=500
x0,x1=np.meshgrid(
np.linspace(x0_min,x0_max,m),
np.linspace(x1_min,x1_max,m)
)
XX=np.c_[x0.ravel(),x1.ravel()]
Y_pred=predict(XX)
Z=Y_pred.reshape(x0.shape)
plt.contourf(x0,x1,Z,cmap=plt.cm.Spectral)
plt.scatter(X[:,0],X[:,1],c=Y,cmap=plt.cm.Spectral)
plt.show()
生成训练数据
def generate_data(F,l,r,n,y):
x=np.linspace(l,r,n)
X=np.column_stack((x,F(x)))
Y=np.repeat(y,n)
return X,Y
主程序
random.seed(114514)
data_size=200
X1,Y1=generate_data(lambda x:x**2+2*x-2+random.randn(data_size)*0.8,-3,1,data_size,0)
X2,Y2=generate_data(lambda x:-x**2+2*x+2+random.randn(data_size)*0.8,-1,3,data_size,1)
X=np.vstack((X1,X2))
Y=np.hstack((Y1,Y2))
train(X,Y)
plot_decision_boundary(X,Y)
参考资料
- [1] 机器学习:逻辑回归(使用多项式特征)
- [2] 深度学习PyTorch极简入门教程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号