[DL学习笔记]从人工神经网络到卷积神经网络_2_卷积神经网络
先一层一层的说卷积神经网络是啥:
1:卷积层,特征提取
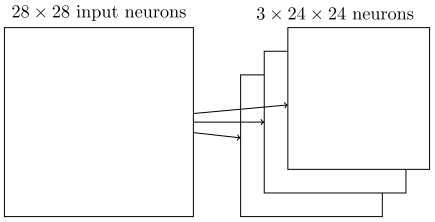
我们输入这样一幅图片(28*28):

如果用传统神经网络,下一层的每个神经元将连接到输入图片的每一个像素上去,但是在卷积神经网络中,我们只把输入图像的一部分连接到下一层的神经元上。
比如每个神经元连接对应的一个5*5的区域:
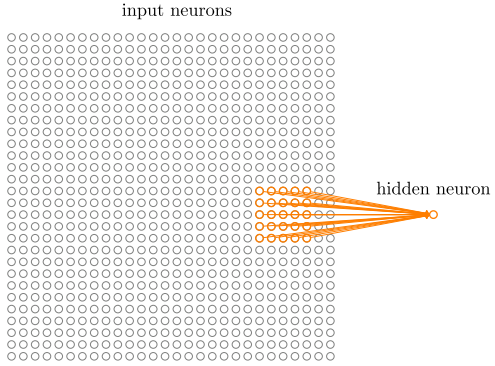
这个输入图像的区域被称为隐藏神经元的局部感受野(local receptive fields),它是输入像素上的一个小窗口。每个连接学习一个权重。而隐藏神经元同时也学习一个总的偏置。可以把特定的隐藏神经元看作是在学习分析它对应的那个局部感受野。
然后我们在整个图像上移动局部感受野,移动的步长可以设定,假如每次移动一格,图像数据和权重的对应元素相乘并求和就得到了下一层神经元的值:
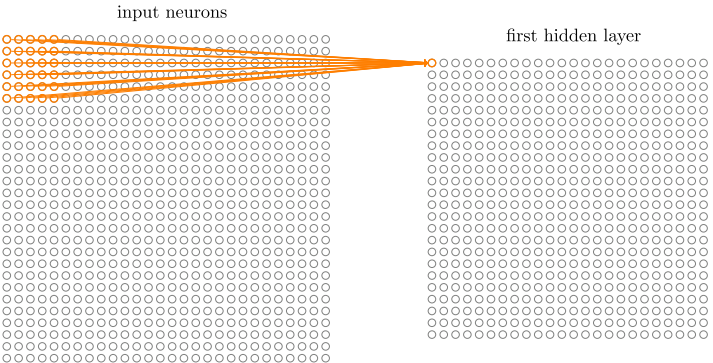
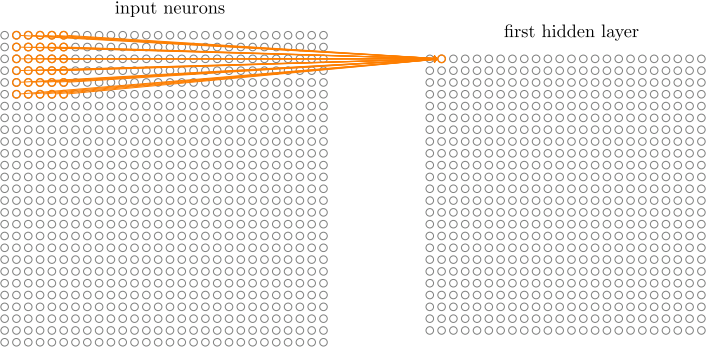
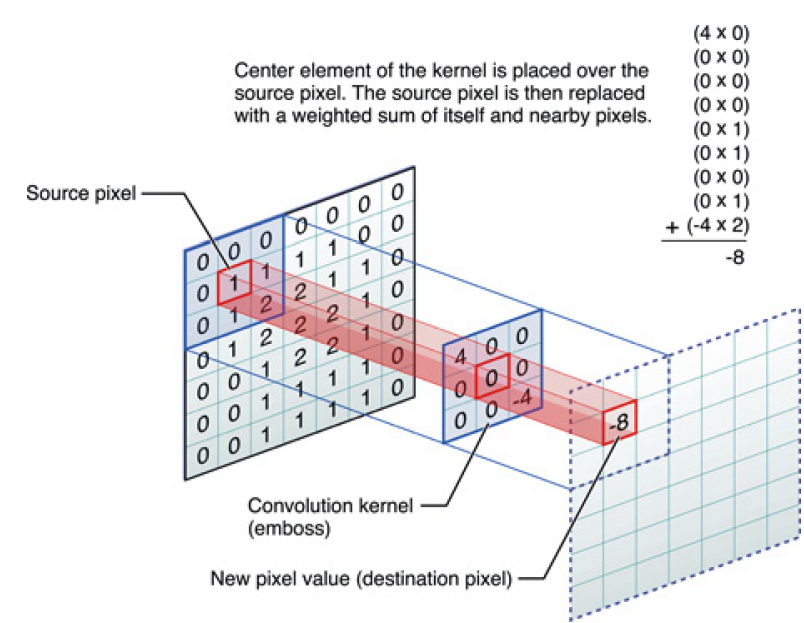
这样我们就得到了一个24*24的特征图,注意生成这个特征图时用的5*5的权重和偏置是固定的,这就是共享权重和偏置。这种方法可以降低参数量,同时还可以认为是一种特征的提取。在人工神经网络中,如果输入一幅图片中有一盘烧鸡在图片的角落中,那么输出的烧鸡得分可能不会高,因为图像的大部分信息都和烧鸡无关,但CNN使用这种滑动卷积核寻找特征的方式,无论你这只鸡在哪里,都能提取出他的特征不是吗。图像这个东西,本身就是一个区域的信息更有说服力,一张图的左上角和右上角两块可能真是没什么实际关系,但一张图中间的某一个区域的像素就关系很大了,比如对一张烧鸡的图片截取其中一小块,人也能通过色泽啊肉质判断出来一点点这最起码是禽类的肉而不是哺乳动物的肉,但随机的在图中取一堆点让人判断这是啥就很难了。这是我对CNN处理图像问题优越性的一个认识吧,可能不够严谨,还请高人指教。。。
或者可以理解为,这个5*5的参数就好像是一个人的世界观,他通过逐行查看这个图片,得出了一个结论就是特征图。CNN通常会设定好多个卷积层(好多个特征图),比如一张特征图专门用来查看图像的边缘信息,另一张专门查看图像的对比度信息,还有查看图像里有没有耳朵等等。
图:一个完整的卷积层通常由若干个不同的特征映射组成
这些特征映射的参数并不是人工决定的,而也是通过优化损失函数自动学习得到的,所以在CNN中不是每个特征都是可以用人话描述清楚的。
这就是卷积层,也是卷积神经网络的核心方法。卷积层的每一个特征图中的每个神经元也需要经过一个激活函数的计算以做非线性的映射,这个激活函数通常使用ReLU:
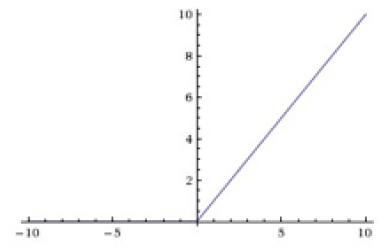
从一些大神口中得知CNN激励函数一定不能使用sigmoid(太容易饱和了,除非你再加一层把所有的值都归一化到0和1之间),优先使用ReLU,如果ReLU训练不下去,就使用Leaky ReLU。
2:Pooling layer
这个层是夹在连续的卷积层之间的一个压缩数据用的层,功能很简单,就是把feature map缩小,有时此层又叫subsampling层,假设有一个特征图如下,使用2*2的max pool来压缩:
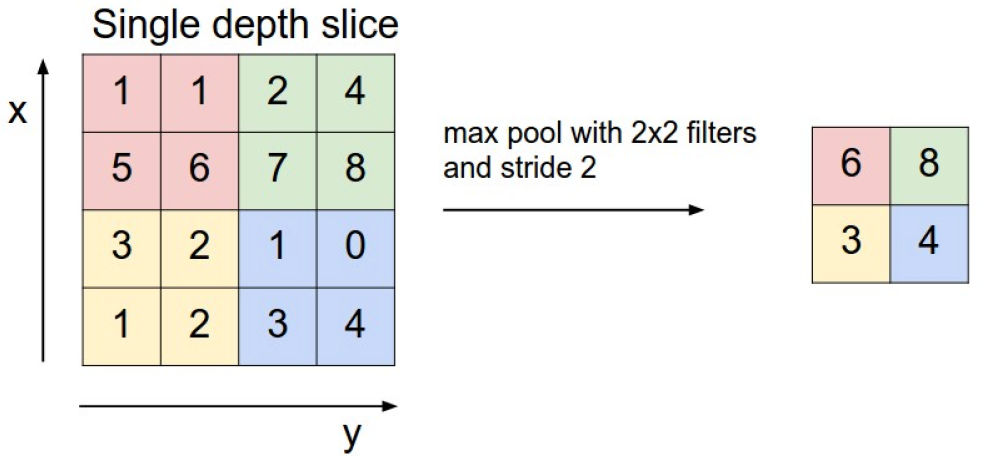
同时还可以用L2池化,均值池化,功能都是一样的。
为什么要有这个层呢?我的理解是这样的:首先对于一个feature map,把它缩小后依旧可以判断出这个特征来,就比如一张红色的图,缩小后它还是红色的,其次这样可以缩小卷积层的层数,如果没有池化,那么一层一层卷积层叠起来,最终连接到最后一层全连接层时候,卷积神经网络的深度将很深,也对训练带来了很大的难度。
CNN就是卷积、池化、卷积、卷积这样组合起来的,到了特征图很小的时候,再链接一个全连接层,就可以做分类问题了下图就是一个卷积神经网络的基本组成:
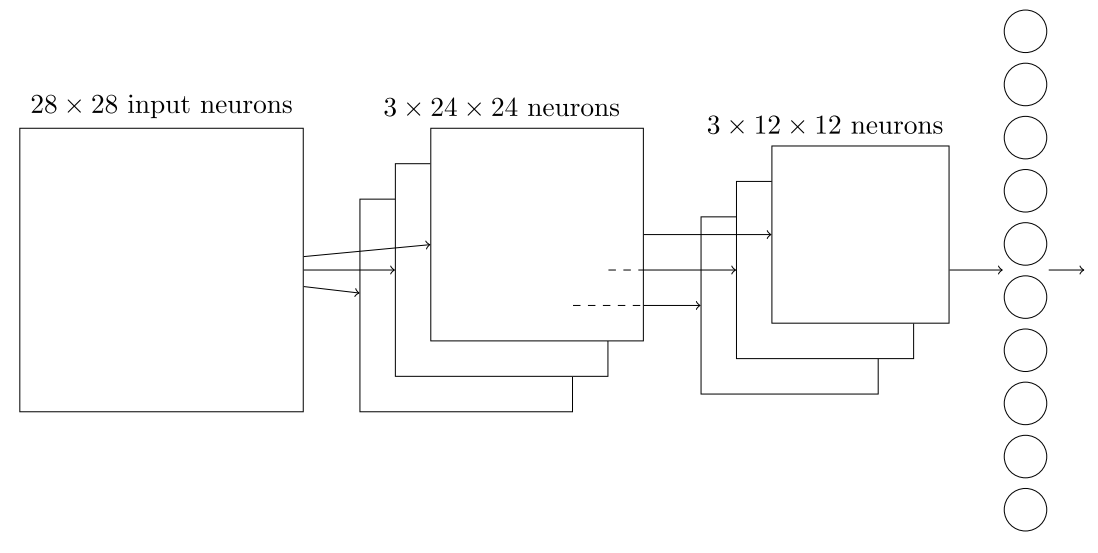
训练卷积神经网络的方法和人工神经网络是一样的,都是先写出来cost function,使用BP求损失函数对各个参数的偏导数,在应用SGD算法迭代得出最优的参数组合。
对于ANN和CNN的原理解析到此为止,从现在开始将使用一些成熟的CNN模型和DL框架实现深度学习的一些功能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号