(2024年11月)ORB_SLAM3复现记录 : 配置环境->跑EuRoC->跑自己的数据集->理解代码
配置环境
虚拟机安装+ubuntu20镜像
看我的这个博客就行,注意把18换成20即可,下载的是一样的iso文件和17的VMware
下面这个超级重要!!!
sudo apt-get autoremove open-vm-tools
sudo apt-get install open-vm-tools-desktop
源码编译安装各种库ORB-SLAM3
注释ORB-SLAM3 - Example文件夹
ORB_SLAM3运行EuRoC、TUM数据集和自己准备的单目鱼眼相机图像
ORB-SLAM3配置及安装教程(2023.3)
Ubuntu20.04 —— 新系统从头安装ORB-SLAM3过程(2022年)
小白问题:源码编译之后的源文件原来是可以删掉的吗?2024-11-21
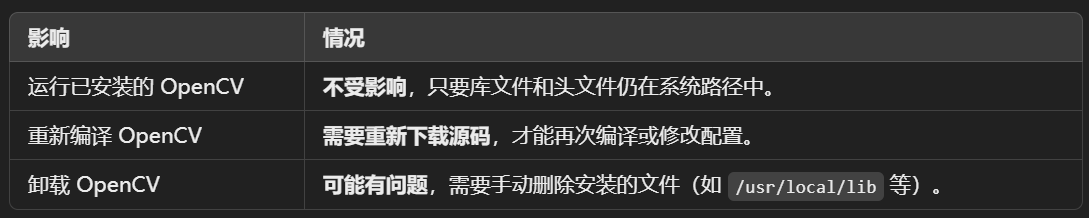
是的,在 源码编译之后的源文件 是可以安全删除的,只要你已经通过 make install 安装了编译结果,并且不需要再次修改或重新编译时,删除源文件通常不会有问题。
为什么源文件可以删掉?
1.源码文件的作用:
用于编译生成二进制文件(如动态库 libopencv_core.so、静态库等)以及头文件。
如果编译成功且通过 make install 安装到了系统路径中(如 /usr/local/lib 和 /usr/local/include),这些编译产物就已经独立存在,不依赖源码。
2.安装后的独立性:
make install 会将所有需要的文件(库文件、头文件、CMake 配置文件等)复制到指定的系统目录(默认 /usr/local)。
编译后的库文件和头文件会被链接器(ld)、pkg-config 或 CMake 查找,不依赖原始源码路径。
3.结果:
如果你只是使用 OpenCV 而不需要重新编译,可以删除源码以节省磁盘空间。
什么情况下不建议删除源码?
需要重新编译或修改配置: 如果你计划修改 OpenCV 的编译选项(例如,启用额外模块、优化参数等),删除源码后会导致需要重新下载。
需要卸载 OpenCV:
源码编译安装的 OpenCV 没有统一的包管理工具记录安装文件(如 apt 或 yum)。
如果需要卸载,通常需要回到原来的源码目录运行 make uninstall。删除源码会导致无法自动卸载,需要手动删除安装的文件。
删除源码的影响
如何判断是否可以删除源码?
检查是否安装成功
1.验证动态库是否已安装:ldconfig -p | grep opencv
输出应包含类似以下内容:libopencv_core.so.3.4 (libc6,x86-64) => /usr/local/lib/libopencv_core.so.3.4
2.验证 pkg-config 配置:pkg-config --modversion opencv
输出应返回 OpenCV 的版本号(如 3.4.3)。
make -j4 ORB_SLAM3时出的错误
/root/autodl-tmp/ORB_SLAM3/Examples_old/Monocular-Inertial/mono_inertial_tum_vi.cc:211:26: error: ‘std::chrono::monotonic_clock’ has not been declared
211 | std::chrono::monotonic_clock::time_point t2 = std::chrono::monotonic_clock::now();
| ^~~~~~~~~~~~~~~
/root/autodl-tmp/ORB_SLAM3/Examples_old/Stereo-Inertial/stereo_inertial_tum_vi.cc: In function ‘int main(int, char**)’:
/root/autodl-tmp/ORB_SLAM3/Examples_old/Stereo-Inertial/stereo_inertial_tum_vi.cc:207:26: error: ‘std::chrono::monotonic_clock’ has not been declared
207 | std::chrono::monotonic_clock::time_point t1 = std::chrono::monotonic_clock::now();
| ^~~~~~~~~~~~~~~
/root/autodl-tmp/ORB_SLAM3/Examples_old/Stereo-Inertial/stereo_inertial_tum_vi.cc:216:26: error: ‘std::chrono::monotonic_clock’ has not been declared
216 | std::chrono::monotonic_clock::time_point t2 = std::chrono::monotonic_clock::now();
| ^~~~~~~~~~~~~~~
/root/autodl-tmp/ORB_SLAM3/Examples_old/Monocular-Inertial/mono_inertial_tum_vi.cc:219:87: error: ‘t2’ was not declared in this scope; did you mean ‘tm’?
219 | double ttrack= std::chrono::duration_cast<std::chrono::duration
| ^~
| tm
/root/autodl-tmp/ORB_SLAM3/Examples_old/Stereo-Inertial/stereo_inertial_tum_vi.cc:224:87: error: ‘t2’ was not declared in this scope; did you mean ‘tm’?
224 | double ttrack= std::chrono::duration_cast<std::chrono::duration
| ^~
| tm
/root/autodl-tmp/ORB_SLAM3/Examples_old/Monocular-Inertial/mono_inertial_tum_vi.cc:219:92: error: ‘t1’ was not declared in this scope; did you mean ‘y1’?
219 | double ttrack= std::chrono::duration_cast<std::chrono::duration
| ^~
| y1
/root/autodl-tmp/ORB_SLAM3/Examples_old/Stereo-Inertial/stereo_inertial_tum_vi.cc:224:92: error: ‘t1’ was not declared in this scope; did you mean ‘y1’?
224 | double ttrack= std::chrono::duration_cast<std::chrono::duration
| ^~
| y1
make[2]: *** [CMakeFiles/stereo_inertial_realsense_D435i_old.dir/build.make:63: CMakeFiles/stereo_inertial_realsense_D435i_old.dir/Examples_old/Stereo-Inertial/stereo_inertial_realsense_D435i.cc.o] Error 1
make[1]: *** [CMakeFiles/Makefile2:188: CMakeFiles/stereo_inertial_realsense_D435i_old.dir/all] Error 2
make[1]: *** Waiting for unfinished jobs....
make[2]: *** [CMakeFiles/stereo_inertial_tum_vi_old.dir/build.make:63: CMakeFiles/stereo_inertial_tum_vi_old.dir/Examples_old/Stereo-Inertial/stereo_inertial_tum_vi.cc.o] Error 1
make[1]: *** [CMakeFiles/Makefile2:269: CMakeFiles/stereo_inertial_tum_vi_old.dir/all] Error 2
make[2]: *** [CMakeFiles/mono_inertial_tum_vi_old.dir/build.make:63: CMakeFiles/mono_inertial_tum_vi_old.dir/Examples_old/Monocular-Inertial/mono_inertial_tum_vi.cc.o] Error 1
make[1]: *** [CMakeFiles/Makefile2:242: CMakeFiles/mono_inertial_tum_vi_old.dir/all] Error 2
[ 41%] Linking CXX executable ../Examples_old/Stereo-Inertial/stereo_inertial_realsense_t265_old
[ 41%] Built target stereo_inertial_realsense_t265_old
make: *** [Makefile:84: all] Error 2
代码中使用了 std::chrono::monotonic_clock::now() 的问题,说明这些代码可能是基于早期 C++ 版本的非标准实现或开发者误用的结果。C++ 标准库并没有 std::chrono::monotonic_clock,所以代码中应该改用 std::chrono::steady_clock。
find /root/autodl-tmp/ORB_SLAM3/Examples -type f -name "*.cc" -exec sed -i 's/monotonic_clock/steady_clock/g' {} +
find /root/autodl-tmp/ORB_SLAM3/Examples -type f -name "*.cc" -exec sed -i 's/monotonic_clock/steady_clock/g' {} +
【算法】跑ORB-SLAM3遇到的问题、解决方法、效果展示(环境:Ubuntu18.04+ROS melodic)
运行
./Examples/Monocular/mono_euroc ./Vocabulary/ORBvoc.txt ./Examples/Monocular/EuRoC.yaml 数据集地址/MH01 ./Examples/Monocular/EuRoC_TimeStamps/MH01.txt
#evaluate & plot python ../evaluation/evaluate_ate_scale.py ../evaluation/Ground_truth/EuRoC_left_cam/MH03_GT.txt f_dataset-MH03_mono.txt --plot MH03_mono.pdf
自己看情况改!
我又新建了MH01,V102等单独的文件夹用来存各自的文件
~/ORB_SLAM3/MH01在这个文件夹下面
../Examples/Monocular/mono_euroc ../Vocabulary/ORBvoc.txt ../Examples/Monocular/EuRoC.yaml ../dataset/MH01 ../Examples/Monocular/EuRoC_TimeStamps/MH01.txt dataset-MH01_mono
../Examples/Monocular-Inertial/mono_inertial_euroc ../Vocabulary/ORBvoc.txt ../Examples/Monocular-Inertial/EuRoC.yaml ../dataset/MH01 ../Examples/Monocular-Inertial/EuRoC_TimeStamps/MH01.txt dataset-MH01_monoi

ORB-SLAM3 的 单目 SLAM 模式,处理指定的 EuRoC 数据集。具体而言:
ORB-SLAM3 的核心单目 SLAM程序 (mono_euroc) 会被运行。
输入了:
词袋模型文件(ORBvoc.txt)。
相机的配置文件(EuRoC.yaml)。
数据集路径(MH01 文件夹)。
时间戳文件(MH01.txt)。
最终的输出是:估计的轨迹文件(dataset-MH01_mono)。
1. 可执行文件
../Examples/Monocular/mono_euroc
描述:这是 ORB-SLAM3 的核心程序,用于单目 SLAM(针对 EuRoC 格式数据)。
功能:调用 ORB-SLAM3 的库,处理输入的图像序列和时间戳,进行地图构建和轨迹估计。
路径:../Examples/Monocular/,运行的程序是 mono_euroc。
2. 词袋模型
../Vocabulary/ORBvoc.txt
描述:预训练的 ORB 词袋模型文件,ORB-SLAM3 的回环检测依赖此文件。
功能:在轨迹估计中进行回环检测,优化相机位姿。
路径:../Vocabulary/ORBvoc.txt。
3. 配置文件
../Examples/Monocular/EuRoC.yaml
描述:YAML 格式的相机配置文件,提供与数据集和相机相关的参数。
内容示例:
Camera.fx: 435.2 Camera.fy: 435.2 Camera.cx: 367.4 Camera.cy: 252.2 Camera.k1: 0.0 Camera.k2: 0.0 Camera.p1: 0.0 Camera.p2: 0.0
功能:
定义相机内参(焦距、主点)。
定义畸变参数(如 k1, k2)。
定义帧率(fps)和分辨率。
4. 数据集路径
../dataset/MH01
描述:这是待处理的图像数据集路径。
要求:文件夹结构必须满足 EuRoC 数据集的格式。例如:
../dataset/MH01/ ├── mav0/ │ └── cam0/ │ └── data/ │ ├── 0.png │ ├── 1.png │ ├── 2.png │ └── ...
功能:为 ORB-SLAM3 提供图像序列输入。
5. 时间戳文件
../Examples/Monocular/EuRoC_TimeStamps/MH01.txt
描述:时间戳文件,与图像帧一一对应,确保帧顺序正确。
格式:
每行一个时间戳,单位为纳秒或秒。例如:
1403636579763555584 1403636579863555584 1403636579963555584
功能:ORB-SLAM3 根据时间戳加载对应帧进行处理。
6. 输出轨迹文件
dataset-MH01_mono
描述:ORB-SLAM3 输出的轨迹文件。
格式:TUM 格式,包含每帧的时间戳、平移(tx, ty, tz)和旋转(四元数)。
timestamp tx ty tz qx qy qz qw
用途:可用于可视化轨迹。
可与 Ground Truth 比较(如计算 ATE)。
执行流程
1.启动 ORB-SLAM3:
初始化 SLAM 系统,加载词袋文件(ORBvoc.txt)和相机配置文件(EuRoC.yaml)。
2.加载数据:
从 MH01 文件夹加载图像序列。
从 MH01.txt 文件加载时间戳。
3.处理图像帧:
每帧图像通过 ORB-SLAM3 进行特征提取、匹配、位姿估计。
4.输出轨迹:
保存轨迹文件 dataset-MH01_mono。
跑EuRoC
MH01
终端Terminal里输入
#!/bin/bash
echo "Launching MH01 with Stereo sensor"
./Examples/Stereo/stereo_euroc ./Vocabulary/ORBvoc.txt ./Examples/Stereo/EuRoC.yaml /home/azq/ORB_SLAM3/dataset/MH01 ./Examples/Stereo/EuRoC_TimeStamps/MH01.txt dataset-MH01_stereo
echo "------------------------------------"
echo "Evaluation of MH01 trajectory with Stereo sensor"
python evaluation/evaluate_ate_scale.py evaluation/Ground_truth/EuRoC_left_cam/MH01_GT.txt f_dataset-MH01_stereo.txt --plot MH01_stereo.pdf

跑起来了,很感动,也有GUI了
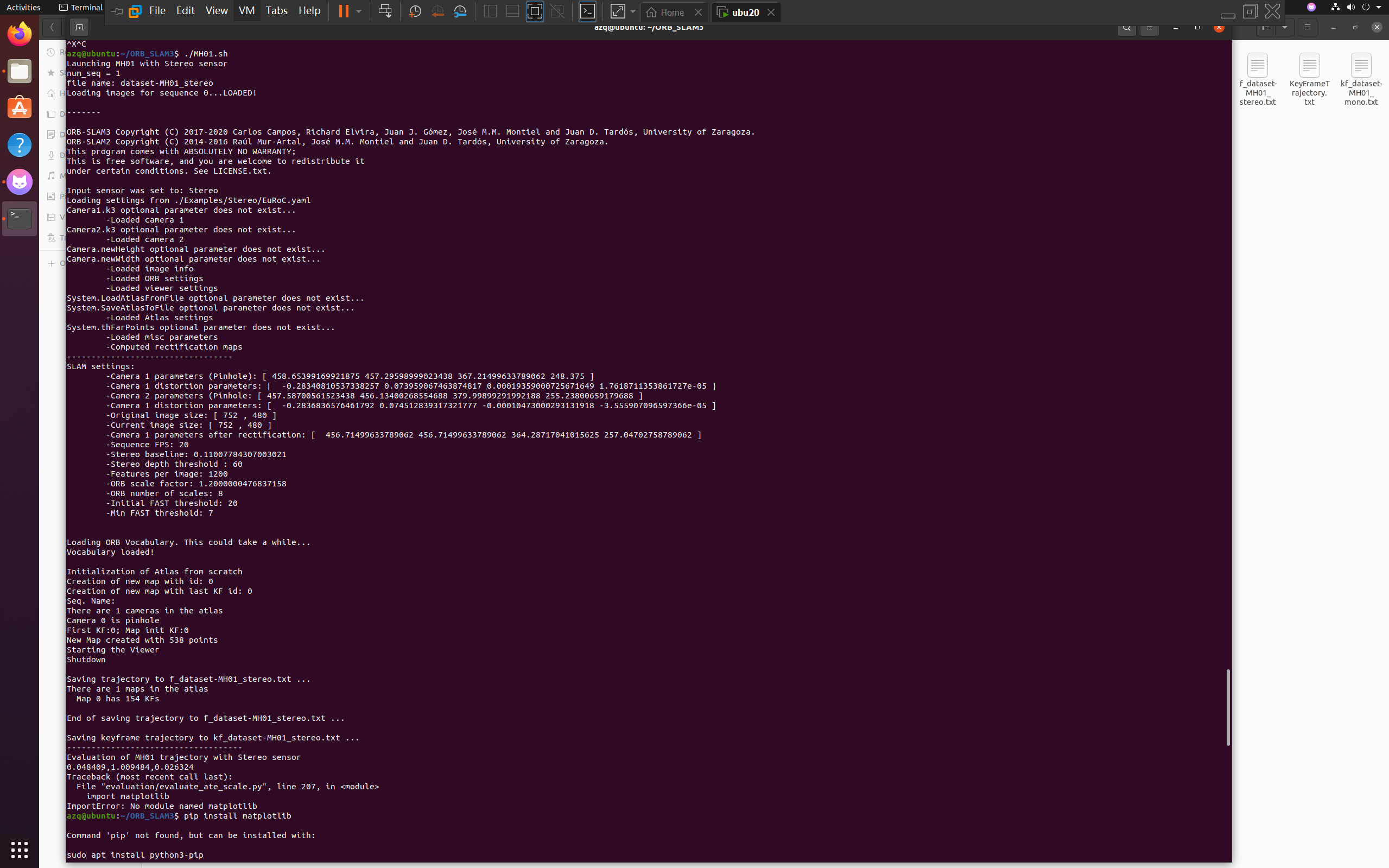
然后想着安装一下matplotlib
sudo apt install python3-pip
pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
可恶,不行啊,因为是python2.7,所以matplotlib的版本太高了
pip install matplotlib==2.2.5 -i https://pypi.tuna.tsinghua.edu.cn/simple


在 Ubuntu 系统中将默认的 Python 版本设置为 Python 3.8
sudo apt install python3.8
sudo update-alternatives --install /usr/bin/python python /usr/bin/python3.8 1
sudo update-alternatives --config python
python --version
然后修改ORB-SLAM3的evaluation代码,从python2.7变成python3.8版本的
association.py
#!/usr/bin/python3
# Software License Agreement (BSD License)
#
# License information omitted for brevity.
import argparse
import sys
import os
import numpy
def read_file_list(filename, remove_bounds=False):
"""
Reads a trajectory from a text file.
File format:
The file format is "stamp d1 d2 d3 ...", where stamp denotes the time stamp (to be matched)
and "d1 d2 d3.." is arbitrary data (e.g., a 3D position and 3D orientation) associated to this timestamp.
Input:
filename -- File name
Output:
dict -- dictionary of (stamp, data) tuples
"""
with open(filename) as file:
data = file.read()
lines = data.replace(",", " ").replace("\t", " ").split("\n")
if remove_bounds:
lines = lines[100:-100]
list_data = [[v.strip() for v in line.split(" ") if v.strip() != ""] for line in lines if len(line) > 0 and line[0] != "#"]
list_data = [(float(l[0]), l[1:]) for l in list_data if len(l) > 1]
return dict(list_data)
def associate(first_list, second_list, offset, max_difference):
"""
Associate two dictionaries of (stamp, data). As the time stamps never match exactly, we aim
to find the closest match for every input tuple.
Input:
first_list -- first dictionary of (stamp, data) tuples
second_list -- second dictionary of (stamp, data) tuples
offset -- time offset between both dictionaries (e.g., to model the delay between the sensors)
max_difference -- search radius for candidate generation
Output:
matches -- list of matched tuples ((stamp1, data1), (stamp2, data2))
"""
first_keys = list(first_list.keys()) # 修改:将dict_keys转换为列表以允许remove操作
second_keys = list(second_list.keys()) # 同上
potential_matches = [(abs(a - (b + offset)), a, b)
for a in first_keys
for b in second_keys
if abs(a - (b + offset)) < max_difference]
potential_matches.sort()
matches = []
for diff, a, b in potential_matches:
if a in first_keys and b in second_keys:
first_keys.remove(a)
second_keys.remove(b)
matches.append((a, b))
matches.sort()
return matches
if __name__ == '__main__':
# parse command line
parser = argparse.ArgumentParser(description='''This script takes two data files with timestamps and associates them.''')
parser.add_argument('first_file', help='first text file (format: timestamp data)')
parser.add_argument('second_file', help='second text file (format: timestamp data)')
parser.add_argument('--first_only', help='only output associated lines from first file', action='store_true')
parser.add_argument('--offset', help='time offset added to the timestamps of the second file (default: 0.0)', default=0.0)
parser.add_argument('--max_difference', help='maximally allowed time difference for matching entries (default: 0.02)', default=0.02)
args = parser.parse_args()
first_list = read_file_list(args.first_file)
second_list = read_file_list(args.second_file)
matches = associate(first_list, second_list, float(args.offset), float(args.max_difference))
if args.first_only:
for a, b in matches:
print(f"{a} {' '.join(first_list[a])}")
else:
for a, b in matches:
print(f"{a} {' '.join(first_list[a])} {b - float(args.offset)} {' '.join(second_list[b])}")
evaluate_ate_scale.py
# Modified by Raul Mur-Artal
# Automatically compute the optimal scale factor for monocular VO/SLAM.
# Software License Agreement (BSD License)
# License and copyright information omitted for brevity.
import sys
import numpy
import argparse
import associate
def align(model, data):
"""Align two trajectories using the method of Horn (closed-form).
Input:
model -- first trajectory (3xn)
data -- second trajectory (3xn)
Output:
rot -- rotation matrix (3x3)
trans -- translation vector (3x1)
trans_error -- translational error per point (1xn)
"""
numpy.set_printoptions(precision=3, suppress=True)
model_zerocentered = model - model.mean(1)
data_zerocentered = data - data.mean(1)
W = numpy.zeros((3, 3))
for column in range(model.shape[1]):
W += numpy.outer(model_zerocentered[:, column], data_zerocentered[:, column])
U, d, Vh = numpy.linalg.svd(W.transpose()) # 修改:linalg.linalg.svd()改为linalg.svd()
S = numpy.identity(3) # 修改:numpy.matrix()改为直接numpy.identity()
if numpy.linalg.det(U) * numpy.linalg.det(Vh) < 0:
S[2, 2] = -1
rot = U @ S @ Vh # 修改:矩阵乘法使用@代替 *
rotmodel = rot @ model_zerocentered
dots = 0.0
norms = 0.0
for column in range(data_zerocentered.shape[1]):
dots += numpy.dot(data_zerocentered[:, column].transpose(), rotmodel[:, column])
normi = numpy.linalg.norm(model_zerocentered[:, column])
norms += normi * normi
s = float(dots / norms)
transGT = data.mean(1) - s * rot @ model.mean(1)
trans = data.mean(1) - rot @ model.mean(1)
model_alignedGT = s * rot @ model + transGT
model_aligned = rot @ model + trans
alignment_errorGT = model_alignedGT - data
alignment_error = model_aligned - data
trans_errorGT = numpy.sqrt(numpy.sum(numpy.multiply(alignment_errorGT, alignment_errorGT), 0)).A[0]
trans_error = numpy.sqrt(numpy.sum(numpy.multiply(alignment_error, alignment_error), 0)).A[0]
return rot, transGT, trans_errorGT, trans, trans_error, s
def plot_traj(ax, stamps, traj, style, color, label):
"""
Plot a trajectory using matplotlib.
Input:
ax -- the plot
stamps -- time stamps (1xn)
traj -- trajectory (3xn)
style -- line style
color -- line color
label -- plot legend
"""
stamps.sort()
interval = numpy.median([s - t for s, t in zip(stamps[1:], stamps[:-1])])
x = []
y = []
last = stamps[0]
for i in range(len(stamps)):
if stamps[i] - last < 2 * interval:
x.append(traj[i][0])
y.append(traj[i][1])
elif len(x) > 0:
ax.plot(x, y, style, color=color, label=label)
label = ""
x = []
y = []
last = stamps[i]
if len(x) > 0:
ax.plot(x, y, style, color=color, label=label)
if __name__ == "__main__":
# parse command line
parser = argparse.ArgumentParser(description='''This script computes the absolute trajectory error from the ground truth trajectory and the estimated trajectory.''')
parser.add_argument('first_file', help='ground truth trajectory (format: timestamp tx ty tz qx qy qz qw)')
parser.add_argument('second_file', help='estimated trajectory (format: timestamp tx ty tz qx qy qz qw)')
parser.add_argument('--offset', help='time offset added to the timestamps of the second file (default: 0.0)', default=0.0)
parser.add_argument('--scale', help='scaling factor for the second trajectory (default: 1.0)', default=1.0)
parser.add_argument('--max_difference', help='maximally allowed time difference for matching entries (default: 10000000 ns)', default=20000000)
parser.add_argument('--save', help='save aligned second trajectory to disk (format: stamp2 x2 y2 z2)')
parser.add_argument('--save_associations', help='save associated first and aligned second trajectory to disk (format: stamp1 x1 y1 z1 stamp2 x2 y2 z2)')
parser.add_argument('--plot', help='plot the first and the aligned second trajectory to an image (format: png)')
parser.add_argument('--verbose', help='print all evaluation data (otherwise, only the RMSE absolute translational error in meters after alignment will be printed)', action='store_true')
parser.add_argument('--verbose2', help='print scale error and RMSE absolute translational error in meters after alignment with and without scale correction', action='store_true')
args = parser.parse_args()
first_list = associate.read_file_list(args.first_file, False)
second_list = associate.read_file_list(args.second_file, False)
matches = associate.associate(first_list, second_list, float(args.offset), float(args.max_difference))
if len(matches) < 2:
sys.exit("Couldn't find matching timestamp pairs between ground truth and estimated trajectory! Did you choose the correct sequence?")
first_xyz = numpy.matrix([[float(value) for value in first_list[a][0:3]] for a, b in matches]).transpose()
second_xyz = numpy.matrix([[float(value) * float(args.scale) for value in second_list[b][0:3]] for a, b in matches]).transpose()
dictionary_items = second_list.items()
sorted_second_list = sorted(dictionary_items)
second_xyz_full = numpy.matrix([[float(value) * float(args.scale) for value in sorted_second_list[i][1][0:3]] for i in range(len(sorted_second_list))]).transpose()
rot, transGT, trans_errorGT, trans, trans_error, scale = align(second_xyz, first_xyz)
second_xyz_aligned = scale * rot @ second_xyz + trans
second_xyz_notscaled = rot @ second_xyz + trans
second_xyz_notscaled_full = rot @ second_xyz_full + trans
first_stamps = list(first_list.keys())
first_stamps.sort()
first_xyz_full = numpy.matrix([[float(value) for value in first_list[b][0:3]] for b in first_stamps]).transpose()
second_stamps = list(second_list.keys())
second_stamps.sort()
second_xyz_full = numpy.matrix([[float(value) * float(args.scale) for value in second_list[b][0:3]] for b in second_stamps]).transpose()
second_xyz_full_aligned = scale * rot @ second_xyz_full + trans
if args.verbose:
print(f"compared_pose_pairs {len(trans_error)} pairs")
print(f"absolute_translational_error.rmse {numpy.sqrt(numpy.dot(trans_error, trans_error) / len(trans_error))} m")
print(f"absolute_translational_error.mean {numpy.mean(trans_error)} m")
print(f"absolute_translational_error.median {numpy.median(trans_error)} m")
print(f"absolute_translational_error.std {numpy.std(trans_error)} m")
print(f"absolute_translational_error.min {numpy.min(trans_error)} m")
print(f"absolute_translational_error.max {numpy.max(trans_error)} m")
print(f"max idx: {numpy.argmax(trans_error)}")
else:
print(f"{numpy.sqrt(numpy.dot(trans_error, trans_error) / len(trans_error))},{scale},{numpy.sqrt(numpy.dot(trans_errorGT, trans_errorGT) / len(trans_errorGT))}")
if args.verbose2:
print(f"compared_pose_pairs {len(trans_error)} pairs")
print(f"absolute_translational_error.rmse {numpy.sqrt(numpy.dot(trans_error, trans_error) / len(trans_error))} m")
print(f"absolute_translational_errorGT.rmse {numpy.sqrt(numpy.dot(trans_errorGT, trans_errorGT) / len(trans_errorGT))} m")
if args.save_associations:
with open(args.save_associations, "w") as file:
file.write("\n".join([f"{a} {x1} {y1} {z1} {b} {x2} {y2} {z2}" for (a, b), (x1, y1, z1), (x2, y2, z2) in zip(matches, first_xyz.transpose().A, second_xyz_aligned.transpose().A)]))
if args.save:
with open(args.save, "w") as file:
file.write("\n".join([f"{stamp} " + " ".join([f"{d}" for d in line]) for stamp, line in zip(second_stamps, second_xyz_notscaled_full.transpose().A)]))
if args.plot:
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(111)
plot_traj(ax, first_stamps, first_xyz_full.transpose().A, '-', "black", "ground truth")
plot_traj(ax, second_stamps, second_xyz_full_aligned.transpose().A, '-', "blue", "estimated")
label = "difference"
for (a, b), (x1, y1, z1), (x2, y2, z2) in zip(matches, first_xyz.transpose().A, second_xyz_aligned.transpose().A):
ax.plot([x1, x2], [y1, y2], '-', color="red", label=label)
label = ""
ax.legend()
ax.set_xlabel('x [m]')
ax.set_ylabel('y [m]')
plt.axis('equal')
plt.savefig(args.plot, format="pdf")
跑自己的数据集
分析MH01数据集特点:
照片有3682张,且以时间戳命名
含有IMU数据文件,为加速度和角速度原始数据,还有IMU内参文件,与ORB-SLAM3的EuRoC_IMU数据一样,代码里读取的是数据集中的IMU数据。
跑图片方式的话,需要将录制的自己数据集转换成ORB-SLAM3要求的以上格式

根据 ORB-SLAM3 的文件命名和用途,每个 .cc 文件及其相关的 .yaml 文件实际上是为特定的数据集或相机配置设计的。这些不同的数据集通常包含室内、室外场景,或者是不同设备(如相机、传感器)采集的数据。
根据 ORB-SLAM3 的文件命名和用途,每个 .cc 文件及其相关的 .yaml 文件实际上是为特定的数据集或相机配置设计的。这些不同的数据集通常包含室内、室外场景,或者是不同设备(如相机、传感器)采集的数据。以下是对常见数据集和代码的分类和用途解释:
文件分类和数据集特征
1. EuRoC 数据集
- 代码文件:
mono_euroc.cc - 配置文件:
EuRoC.yaml - 数据集类型:室内(工业环境)。
- 场景特征:
- 室内工厂、实验室环境。
- 带有相机和 IMU 的 MAV(多旋翼无人机)拍摄。
- 稳定且高频率的图像帧。
- 用途:
- 测试单目 SLAM 系统的鲁棒性。
- 验证 IMU 辅助 SLAM(可以扩展为视觉惯性 SLAM)。
2. KITTI 数据集
- 代码文件:
mono_kitti.cc - 配置文件:
KITTI00-02.yamlKITTI03.yamlKITTI04-12.yaml
- 数据集类型:室外(城市道路、郊区场景)。
- 场景特征:
- 室外动态环境。
- 车载相机采集(立体相机 + GPS/IMU)。
- 数据集含高质量的地面真值(Ground Truth)。
- 用途:
- 测试 SLAM 在室外场景中的性能。
- 比较轨迹估计与真值的误差。
3. TUM 数据集
- 代码文件:
mono_tum.ccmono_tum_vi.cc
- 配置文件:
TUM1.yamlTUM2.yamlTUM3.yamlTUM-VI.yaml
- 数据集类型:室内。
- 场景特征:
- 室内办公环境、家庭场景。
- 动态和静态场景(有时含有运动物体)。
- 支持单目相机和 IMU(视觉惯性)。
- 用途:
- 测试动态场景下的 SLAM 性能。
- 验证轨迹估计的准确性。
- 支持单目、立体、RGB-D 数据。
4. RealSense 数据集
- 代码文件:
mono_realsense_D435i.ccmono_realsense_t265.cc
- 配置文件:
RealSense_D435i.yamlRealSense_T265.yaml
- 数据集类型:实时采集。
- 场景特征:
- 使用 Intel RealSense 相机采集数据。
- D435i:RGB-D 数据(彩色图像 + 深度)。
- T265:内置 IMU 的追踪摄像头。
- 用途:
- 测试实时 SLAM 系统。
- 验证 RGB-D 和视觉惯性数据的兼容性。
5. 自定义数据集
- 代码文件:
- 基于
mono_euroc.cc或其他类似文件修改。
- 基于
- 适配方式:
- 修改图像路径加载逻辑(
LoadImages)。 - 调整相机配置(
.yaml文件)。 - 添加 Ground Truth 进行误差评估。
- 修改图像路径加载逻辑(
场景分类与代码适配
| 场景类型 | 数据集/代码 | 特征 | 使用建议 |
|---|---|---|---|
| 室内(工业) | mono_euroc.cc |
工厂、实验室 | 适用于无人机数据、稳定光照和运动轨迹。 |
| 室内(办公) | mono_tum.cc |
家庭、办公室 | 适用于动态场景测试(如运动物体)。 |
| 室外(城市) | mono_kitti.cc |
道路、郊区 | 测试车载 SLAM,在 GPS/IMU 帮助下验证轨迹性能。 |
| 实时采集 | mono_realsense_D435i.cc 或 mono_realsense_t265.cc |
深度数据、IMU | 测试实时 SLAM,验证 RGB-D 数据的效果。 |
| 自定义场景 | 修改现有代码 | 灵活 | 根据需求调整,适配其他室内/室外数据集。 |
建议替换 TUM 数据集 的相关代码和文件(如 mono_tum.cc),以跑 ScanNet 数据集 并获取 ATE RMSE (cm) 数据。
理由
数据集特性对比
| 数据集 | 特性/场景 | 支持的运行模式 | 帧率 | 轨迹评估方法 |
|---|---|---|---|---|
| TUM | 室内,RGB-D | Mono, RGB-D | 通常 30fps | 直接使用 TUM 格式 |
| EuRoC | 室内,灰度相机 + IMU | Mono, Stereo, VI | 通常 20fps | 需要转换为 TUM 格式 |
| KITTI | 室外,车载摄像头 | Mono, Stereo | 通常 10fps | 需要转换为 TUM 格式 |
| ScanNet | 室内,RGB-D | Mono, RGB-D | 通常 30fps | 需要转换为 TUM 格式 |
从特性上看,TUM 数据集 和 ScanNet 数据集 都是 室内 RGB-D 场景,格式也相对接近,因此选择 TUM 作为替换模板最合适。
代码最小改动
mono_tum.cc和 TUM 的配置文件(如TUM1.yaml)都可以直接作为基础,只需要:- 替换 ScanNet 的相机内参。
- 替换数据路径和文件名格式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号