python神经网络编程2之用python搭建神经网络
【数据集下载地址】
1.MNIST数据集中较小子集( 需要 右键 另存为 )
- 100条训练数据集
- 10条测试数据集
2.MNIST完整数据集( 点击即可 直接下载 )
- 训练数据集
http://www.pjreddie.com/media/files/mnist_train.csv
- 测试数据集
http://www.pjreddie.com/media/files/mnist_test.csv
【python基础】
环境:Jupyter Notebook
for n in range(10): print(n) pass #标志循环结束,下一行回正常缩进,done只打印一次 我也可以删掉orz print("done")

#funtion that takes 2 numbers as input #and outputs their avarage def avg(x,y): print("first input is",x) print("second input is",y) a=(x+y)/2.0 print("avarage is",a) return a
import numpy a=numpy.zeros([3,2]) print(a)

a[0,0]=1 a[0,1]=2 a[1,0]=9 a[2,1]=12 print(a)

import matplotlib.pyplot matplotlib.pyplot.imshow(a,interpolation="nearest") #imshow():创建绘图,参数一:要绘制的数组 #最后一项:不要让绘图看起来平滑二混合颜色
<matplotlib.image.AxesImage at 0x1e9dd2fab20>
#只定义对象一次,却可以多次使用对象,对象类似于可重用函数,但更多 #class for a dog object class Dog: #dogs can bark() #对象函数被称为method def bark(self): #self:为了当python创建函数时,python可把函数赋予正确的对象 print("woof!") pass#貌似可有可无 pass
sizzles=Dog()#创建对象,实例 mutley=Dog()#创建对象,实例 sizzles.bark() mutley.bark() #类只是定义(蛋糕配方) #对象是所定义类的真正实例(按配方做好的蛋糕) #对象可以利用模板批量创建 #对象内由整齐封装在内的数据和函数

#把数据变量添加至类中,并添加一些方法观察、改变这些数据 #class for a dog object class Dog: #initialisation method with internal date def __init__(self,petname,temp): #后两项:函数期望的变量参数 #初始化函数:在实际使用对象前,该函数准备对象 #创建两个新变量,把变量参数传递过去 self.name=petname; self.temperature=temp; #"self."指变量是对象本身的一部分,这个变量只属于这个对象 #get status def status(self):#无参,仅打印Dog对象名和温度变量 print("dog name is ",self.name) print("dog temperature is ",self.temperature) pass #set temperature def setTemperature(self,temp): #创建对象后任何时间均可改变对象温度 self.temperature=temp; pass #dogs can bark() def bark(self): print("woof!") pass pass
#create a new dog object from the Dog class lassie=Dog("Lassie",37) lassie.status()

lassie.setTemperature(40)
lassie.status()

2022.11.21更新
#优秀的程序员、计算机科学家和数学家 #只要可能,都尽力创建一般代码,而不是具体的代码 #这让我们以一种更广泛的适用方式思考求解问题 #从而让我们的解决方案可以适用于不同的场景 #开发代码使神经网络保持尽可能多地开放有用的选项 #将假设降低到最低限度→可以根据不同需要得到使用 #code for a 3-layer neural network, and code for learning the MNIST dataset #(c) Tariq Rashid, 2016 #license is GPLv2 #scipy.special for the sigmoid function expit() import scipy.special import numpy #library for plotting arrays import matplotlib.pyplot #ensure the plots are inside this notebook, not an external window %matplotlib inline #neural network class definition class neuralNetwork: #initialise the neural network def __init__(self,inputnodes,hiddennodes,outputnodes,learningrate): #set number of nodes in each input, hidden, output layer self.inodes=inputnodes self.hnodes=hiddennodes self.onodes=outputnodes #神经网络的核心:链接权重矩阵 #link weight matrices, wih and who #weights inside the arrays are w_i_j, where link is from node i to node j in the next layer #w11 w21 #w12 w22 etc #self.wih=(numpy.random.rand(self.hnodes,self.inodes)-0.5) #self.who=(numpy.random.rand(self.onodes,self.hnodes)-0.5) #可选项:稍复杂的初始随机权重,用正态概率分布采样权重,平均值为0 self.wih=numpy.random.normal(0.0,pow(self.hnodes,-0.5),(self.hnodes,self.inodes)) self.who=numpy.random.normal(0.0,pow(self.onodes,-0.5),(self.onodes,self.hnodes)) #第一项正态分布的中心为0.0 #第二项指节点数目的-0.5次方 #第三项numpy数组的形状大小 #learning rate self.lr=learningrate #activation function is the sigmoid function self.activation_function=lambda x: scipy.special.expit(x) pass #train the neural network def train(self,inputs_list,targets_list): #核心:基于所计算输出与目标输出之间的误差,改进权重 #convert inputs list to 2d array inputs=numpy.array(inputs_list, ndmin=2).T targets=numpy.array(targets_list, ndmin=2).T #把targets_list变成了numpy数组 #calculate signals into hidden layer hidden_inputs=numpy.dot(self.wih, inputs) #calculate the signals emerging from hidden layer hidden_outputs=self.activation_function(hidden_inputs) #calculate signals into final output layer final_inputs=numpy.dot(self.who, hidden_outputs) #calculate the signals emerging from final output layer final_outputs=self.activation_function(final_inputs) #output layer error is the (target-actual) output_errors=targets-final_outputs #hidden layer error is the output_errors, split by weights,recombined at hidden nodes hidden_errors=numpy.dot(self.who.T, output_errors) #*乘法是正常的对应元素的乘法 #·点乘是矩阵点积 #update the weights for the links between the hidden and output layers self.who+=self.lr*numpy.dot((output_errors*final_outputs*(1.0-final_outputs)),numpy.transpose(hidden_outputs)) #update the weights for the links between the input and hidden layers self.wih+=self.lr*numpy.dot((hidden_errors*hidden_outputs*(1.0-hidden_outputs)),numpy.transpose(inputs)) pass #query the neural network #query()接受神经网络的输入,返回输出 #需要来自输入层节点的输入信号,通过隐藏层,从输出层输出 #信号馈送至给定隐藏层or输出层节点时,使用链接权重调节信号 #也用激活函数抑制来自节点的信号 def query(self,inputs_list): #convert inputs list to 2d array inputs=numpy.array(inputs_list, ndmin=2).T #calculate signals into hidden layer hidden_inputs=numpy.dot(self.wih, inputs) #calculate the signals emerging from hidden layer hidden_outputs=self.activation_function(hidden_inputs) #calculate signals into final output layer final_inputs=numpy.dot(self.who, hidden_outputs) #calculate the signals emerging from final output layer final_outputs=self.activation_function(final_inputs) return final_outputs #number of input, hidden and output nodes input_nodes=784#28*28的结果 hidden_nodes=100#不是科学的方法得到的比输入节点数量小的值 #强制网络尝试总结输入的主要特点,但不能太小从而限制网络寻找特征能力 output_nodes=10#给定的输出层需要10个标签 #learning rate is 0.3 learning_rate=0.3 #create instance of neural network n=neuralNetwork(input_nodes, hidden_nodes, output_nodes, learning_rate) #load the mnist training data CSV file into a list training_data_file=open("mnist_train_100.csv",'r') training_data_list=training_data_file.readlines() training_data_file.close() #train the neural network #go through all records in the training data set for record in training_data_list: #split the record by the ',' commas all_values=record.split(',') #scale and shift the inputs inputs=(numpy.asfarray(all_values[1:])/255.0*0.99)+0.01 #create the target output values(all 0.01,except the desired label which is 0.99) targets=numpy.zeros(output_nodes)+0.01 #all_values[0] is the target label for this record targets[int(all_values[0])]=0.99 n.train(inputs,targets) pass #获得测试记录,与获取训练数据代码相似 #load the mnist test data CSV file into a list test_data_file=open("mnist_test_10.csv",'r') test_data_list=test_data_file.readlines() test_data_file.close()
#get the first test record all_values=test_data_list[0].split(',') #print the label print(all_values[0])

image_array=numpy.asfarray(all_values[1:]).reshape((28,28)) matplotlib.pyplot.imshow(image_array,cmap='Greys',interpolation='None')
<matplotlib.image.AxesImage at 0x1deefb775e0>

n.query((numpy.asfarray(all_values[1:])/255.0+0.99)+0.01)

#test the neural network #scorecard for how well the network perform, initially empty scorecard=[] #go through all the records in the test data set for record in test_data_list: #split the record by the ',' commas #根据逗号拆分文本记录,分理出数值 all_values=record.split(',') #correct answer is first value correct_label=int(all_values[0]) print(correct_label,"correct label") #scale and shift the inputs inputs=(numpy.asfarray(all_values[1:])/255.0*0.99)+0.01 #query the network outputs=n.query(inputs) #the index of the highest value corresponds to the label label=numpy.argmax(outputs) print(label,"network's answer") #append correct or incorrect to list if (label==correct_label): #network's answer matches correct answer, add 1 to scorecard scorecard.append(1) else: #network's answer doesn't match correct answer, add 0 to scorecard scorecard.append(0) pass pass #scorecard计分卡,测试每条记录后都会更新 print(scorecard) #10个测试只答对了6个,太菜了(不过训练集不多,just-so-so)

#calculate the performance score, the fraction of correct answers #正确答案的分数=计分卡上“1”的数目/计分卡条目总数(计分卡大小) scorecard_array=numpy.asarray(scorecard) print("performance=",scorecard_array.sum()/scorecard_array.size)

本应该在前面但被放到了后面hhh
#number of input, hidden and output nodes input_nodes=3 hidden_nodes=3 output_nodes=3 #learning rate is 0.3 learning_rate=0.3 #create instance of neural network n=neuralNetwork(input_nodes, hidden_nodes, output_nodes, learning_rate) n.query([1.0,0.5,-1.5])

#铺垫:随机生成权重 import numpy numpy.random.rand(3,3)

data_file=open("mnist_train_100.csv",'r') data_list=data_file.readlines() data_file.close() len(data_list)

data_list[0]

all_values=data_list [0].split(',') #split根据逗号,将一长串进行拆分 image_array=numpy.asfarray(all_values[1:]).reshape((28,28)) matplotlib.pyplot.imshow(image_array,cmap='Greys',interpolation='None')
<matplotlib.image.AxesImage at 0x1deee71eb20>

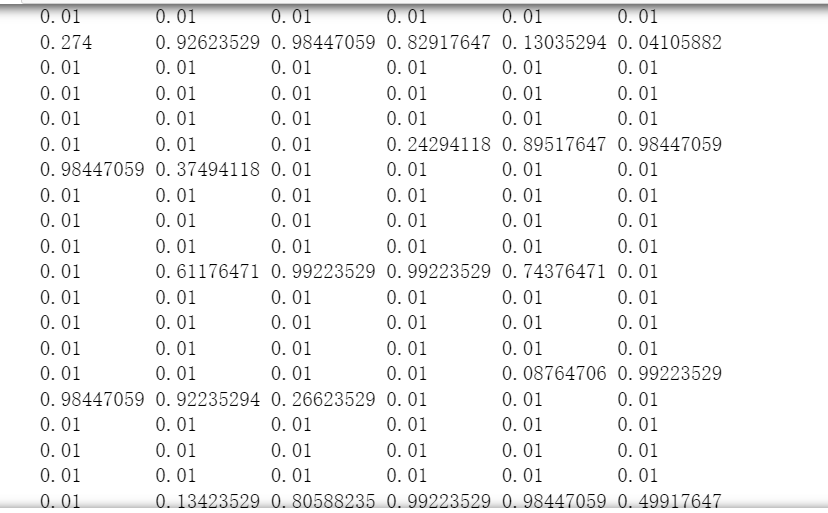
#step1 将输入颜色值从较大的0到255范围缩放至0.01到1.0范围 #选0.01是避免先前观察到的0值输入导致权重更新失败 #不需要避免输入1.0,只需避免输出1.0 #0~255范围内原始输入除255,得到0~1范围的输入值 #乘0.99,其范围变成0.0~0.99 #再加0.01,得到范围0.01~1.00 scaled_input=(numpy.asfarray(all_values[1:])/255.0*0.99)+0.01 print(scaled_input)
#要让神经网络生成0和1的输出,激活函数做不到 #也会让大的权重和饱和网络 #应该调整数字,用0.01,0.99代替0和1 #表示标签5从[0,0,0,0,0,1,0,0,0,0] #变成[0.01,0.01,0.01,0.01,0.01,0.99,0.01,0.01,0.01,0.01] #构成目标矩阵↓ #output nodes is 10 (example) onodes=10 targets=numpy.zeros(onodes)+0.01 targets[int(all_values[-1])]=0.99 #如果是书上的all_values[0],第一个元素就不是0.99了,很奇怪 print(targets)
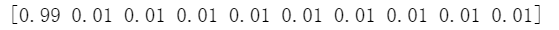
【搭建真正的神经网络】
#scipy.special for the sigmoid function expit() import scipy.special import numpy #library for plotting arrays import matplotlib.pyplot #ensure the plots are inside this notebook, not an external window %matplotlib inline #neural network class definition class neuralNetwork: #initialise the neural network def __init__(self,inputnodes,hiddennodes,outputnodes,learningrate): #set number of nodes in each input, hidden, output layer self.inodes=inputnodes self.hnodes=hiddennodes self.onodes=outputnodes #神经网络的核心:链接权重矩阵 #link weight matrices, wih and who #weights inside the arrays are w_i_j, where link is from node i to node j in the next layer #w11 w21 #w12 w22 etc #self.wih=(numpy.random.rand(self.hnodes,self.inodes)-0.5) #self.who=(numpy.random.rand(self.onodes,self.hnodes)-0.5) #可选项:稍复杂的初始随机权重,用正态概率分布采样权重,平均值为0 self.wih=numpy.random.normal(0.0,pow(self.hnodes,-0.5),(self.hnodes,self.inodes)) self.who=numpy.random.normal(0.0,pow(self.onodes,-0.5),(self.onodes,self.hnodes)) #第一项正态分布的中心为0.0 #第二项指节点数目的-0.5次方 #第三项numpy数组的形状大小 #learning rate self.lr=learningrate #activation function is the sigmoid function self.activation_function=lambda x: scipy.special.expit(x) pass #train the neural network def train(self,inputs_list,targets_list): #核心:基于所计算输出与目标输出之间的误差,改进权重 #convert inputs list to 2d array inputs=numpy.array(inputs_list, ndmin=2).T targets=numpy.array(targets_list, ndmin=2).T #把targets_list变成了numpy数组 #calculate signals into hidden layer hidden_inputs=numpy.dot(self.wih, inputs) #calculate the signals emerging from hidden layer hidden_outputs=self.activation_function(hidden_inputs) #calculate signals into final output layer final_inputs=numpy.dot(self.who, hidden_outputs) #calculate the signals emerging from final output layer final_outputs=self.activation_function(final_inputs) #output layer error is the (target-actual) output_errors=targets-final_outputs #hidden layer error is the output_errors, split by weights,recombined at hidden nodes hidden_errors=numpy.dot(self.who.T, output_errors) #*乘法是正常的对应元素的乘法 #·点乘是矩阵点积 #update the weights for the links between the hidden and output layers self.who+=self.lr*numpy.dot((output_errors*final_outputs*(1.0-final_outputs)),numpy.transpose(hidden_outputs)) #update the weights for the links between the input and hidden layers self.wih+=self.lr*numpy.dot((hidden_errors*hidden_outputs*(1.0-hidden_outputs)),numpy.transpose(inputs)) pass #query the neural network #query()接受神经网络的输入,返回输出 #需要来自输入层节点的输入信号,通过隐藏层,从输出层输出 #信号馈送至给定隐藏层or输出层节点时,使用链接权重调节信号 #也用激活函数抑制来自节点的信号 def query(self,inputs_list): #convert inputs list to 2d array inputs=numpy.array(inputs_list, ndmin=2).T #calculate signals into hidden layer hidden_inputs=numpy.dot(self.wih, inputs) #calculate the signals emerging from hidden layer hidden_outputs=self.activation_function(hidden_inputs) #calculate signals into final output layer final_inputs=numpy.dot(self.who, hidden_outputs) #calculate the signals emerging from final output layer final_outputs=self.activation_function(final_inputs) return final_outputs
#number of input, hidden and output nodes input_nodes=784#28*28的结果 hidden_nodes=200#不是科学的方法得到的比输入节点数量小的值 #强制网络尝试总结输入的主要特点,但不能太小从而限制网络寻找特征能力 #增加隐藏层节点数的确会有性能增加,但加到太多增加就不明显了! output_nodes=10#给定的输出层需要10个标签 learning_rate=0.1 #create instance of neural network n=neuralNetwork(input_nodes, hidden_nodes, output_nodes, learning_rate)
#load the mnist training data CSV file into a list training_data_file=open("mnist_train.csv",'r') training_data_list=training_data_file.readlines() training_data_file.close() #train the neural network #epochs is the number of times the training data set is used for training epochs=5 for e in range(epochs): #go through all records in the training data set for record in training_data_list: #split the record by the ',' commas all_values=record.split(',') #scale and shift the inputs inputs=(numpy.asfarray(all_values[1:])/255.0*0.99)+0.01 #create the target output values(all 0.01,except the desired label which is 0.99) targets=numpy.zeros(output_nodes)+0.01 #all_values[0] is the target label for this record targets[int(all_values[0])]=0.99 n.train(inputs,targets) pass pass #使用两个epoch的神经网络比只用一个的性能有所提高 #直觉:所做训练越多,得到性能越好 #大约5-7个epochs,性能最好(sweet point 是5个) #learning_rate=0.1而不是0.2时,性能与epochs的关系出现了总体提高 #常规而言0是黑色,255是白色 #MNIST数据集用相反的方式表示
#获得测试记录,与获取训练数据代码相似 #load the mnist test data CSV file into a list test_data_file=open("mnist_test.csv",'r') test_data_list=test_data_file.readlines() test_data_file.close() #test the neural network #scorecard for how well the network perform, initially empty scorecard=[] #go through all the records in the test data set for record in test_data_list: #split the record by the ',' commas #根据逗号拆分文本记录,分理出数值 all_values=record.split(',') #correct answer is first value correct_label=int(all_values[0]) print(correct_label,"correct label") #scale and shift the inputs inputs=(numpy.asfarray(all_values[1:])/255.0*0.99)+0.01 #query the network outputs=n.query(inputs) #the index of the highest value corresponds to the label label=numpy.argmax(outputs) print(label,"network's answer") #append correct or incorrect to list if (label==correct_label): #network's answer matches correct answer, add 1 to scorecard scorecard.append(1) else: #network's answer doesn't match correct answer, add 0 to scorecard scorecard.append(0) pass pass #scorecard计分卡,测试每条记录后都会更新 print(scorecard)

#calculate the performance score, the fraction of correct answers #正确答案的分数=计分卡上“1”的数目/计分卡条目总数(计分卡大小) scorecard_array=numpy.asarray(scorecard) print("performance=",scorecard_array.sum()/scorecard_array.size)

#计算6w个训练样本 #每个样本进行一组784个输入节点 #经100个隐藏层节点的前馈计算 #还要进行误差反馈和权重更新 #作者的现代计算机花了2min完成训练循环 #尝试修改学习率0.3为0.6,0.1可以得到不同的结果 #MNIST数据集和神经网络的sweet point大致是0.2的学习率(0.1-0.3)
【注意】ipynb文件需要和csv文件位于同一个文件夹,否则加载数据时改为绝对路径
