python神经网络编程1之神经网络如何工作
- 计算机系统:输入->(计算)->输出
- 建立模型可以模拟事情的运作
神经网络的基本思想:持续细化误差值。
大的误差需要大的修正值,小的误差需要小的修正值。
尝试得到一个答案,并多次改进答案。可称迭代,是持续地、一点一点地改进答案。
- 分类器和预测器区别不大
预测器:接受一个输入,做应有的预测,输出结果
简单预测器中,使用线性函数可以对先前未知的数据分类,但某些情况下得到正确的斜率需要改进。
如何更好地调整参数(简单的分类器线性函数中是直线斜率y=Ax)?
算法:利用一种可重复的方法、一系列计算机指令达到目标
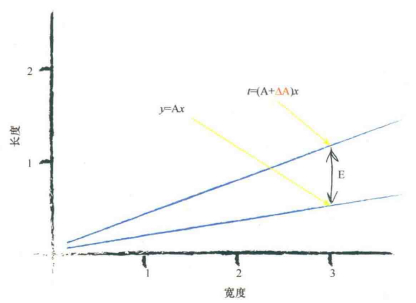
误差值=(期望目标值-实际输出值)
$E=t-y=(A+\Delta A)x-Ax=(\Delta A)x$
$\displaystyle{\Delta A=\frac{E}{x}}$
基于当前误差值调整参数的方法
$y=(A+\Delta A)*x$
像上面这样继续操作,用各个训练数据样本改进,得到的最终直线和最后一次训练样本很匹配。最终改进的直线不会顾及所有先前的训练样本,而是会抛弃所有过去训练样本的学习结果,只学习最近的实例。
因此,需要进行适度改进——小心地让分类器沿样本指示的方向移动,保持之前训练/迭代得到的值的一部分。
这种自我节制的调整,可以有效抑制或缓解“训练数据本身不一定完全正确”与“现实测量往往存在错误或噪声”的问题。
因此可以在公式中增加一个调节系数
$\displaystyle{\Delta A=L*(\frac{E}{x})}$,其中$L$为学习率
若L=0.5,则只更新原更新值的一半
- 简单的线性分类器(如直线)不能把XOR函数的两类分开
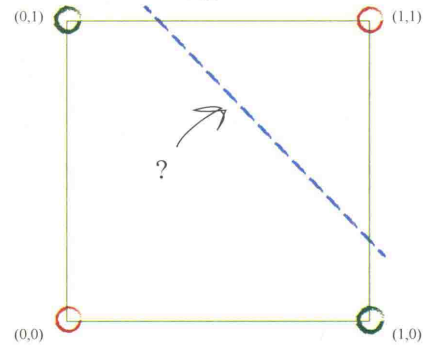
如果不能用一条直线把根本性的问题分开,则一个简单的线性分类器是无用的。
有时可以采用两条直线对不同区域划分→可以使用多个分类器一起工作
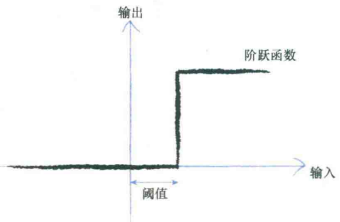
神经元工作原理:神经元接受一个电输入,输出另一个电信号。但神经元不会立即反应,而是会抑制输入,直到输入增强,强大到可以触发输出。
神经元不希望传递微小的噪声信号,而只是传递有意识的明显信号。因此,只有输入超过了阈值,足够接通电路,才会产生输出信号。
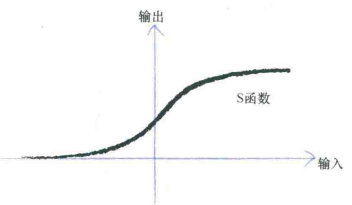 sigmoid $y=\frac{1}{1+e^{-x}$
sigmoid $y=\frac{1}{1+e^{-x}$
生物神经元可以接受许多输入,构建的神经网络也可以。
接受了这些输入后,对它们相加得到最终总和,就是S函数的输出。
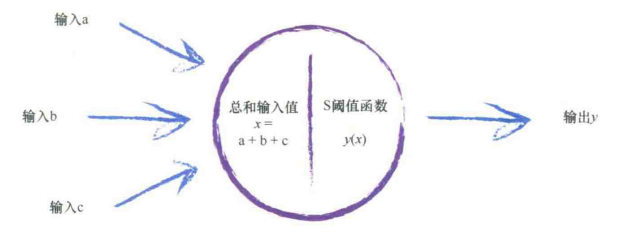
这种情况下,组合信号超过S阈值函数就可以激发神经元,反之则抑制输出信号。
模仿自然界中每个神经元接受来自其之前多个神经元的输入,激发后提供信号给更多神经元,构建多层神经元,每一层中神经元和在其前后层的神经元相互连接。
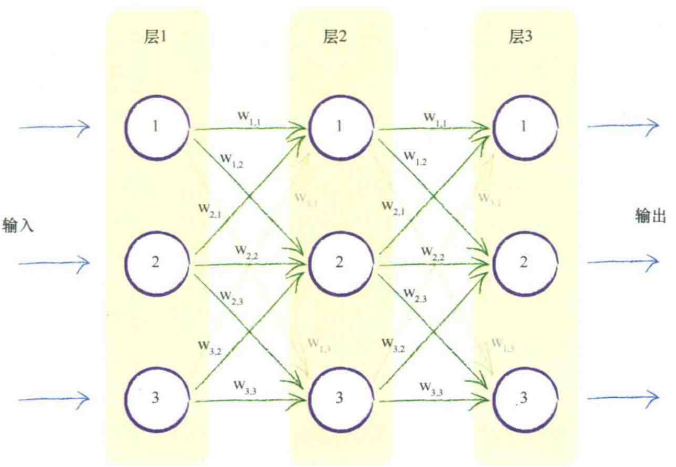
不采用创造性的方式连接神经元的原因
①一致的完全连接形式易于编写代码
②神经网络会通过学习弱化不需要的连接的权重到趋近于0,相当于断开链接
已知输入,未知权重,可以先随机取权重,再通过神经网络学习样本更新权重
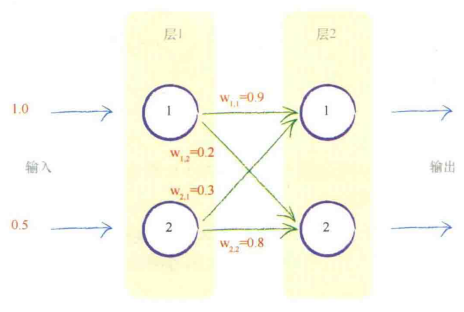
第一层仅仅输入。
第二层对每个节点,计算组合输入,即前一层中原始输出得到链接权重的调节。
权重是神经网络进行学习的内容,权重的持续优化可以带来更好的结果。
……
面对一个有很多层、很多节点的神经网络,
可以用矩阵的方式写下需要计算输出值的指令,非常简短,执行也很有效率。
矩阵?数字表格!
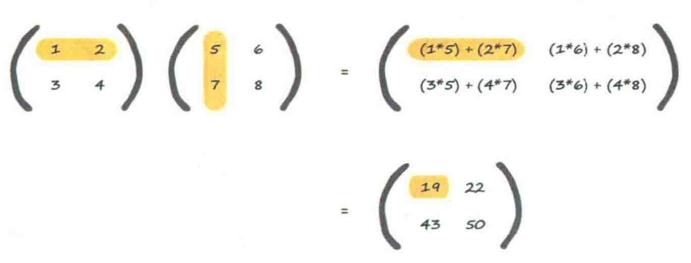
推广(一般规则)
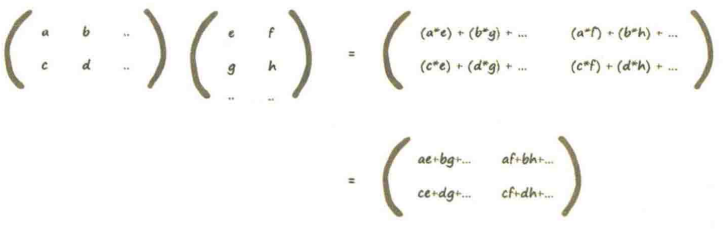
矩阵相乘(点乘/内积)的兼容规则:第一个矩阵的行和第二个矩阵的列应该相互匹配。

可以用矩阵乘法,计算调节后的信号x,输入到第二层的节点
$X=W·I$
$W$权重矩阵,$I$输入矩阵,$X$组合调节后的信号(输入到第二层的结果矩阵)
也适用于前后层之间的计算。
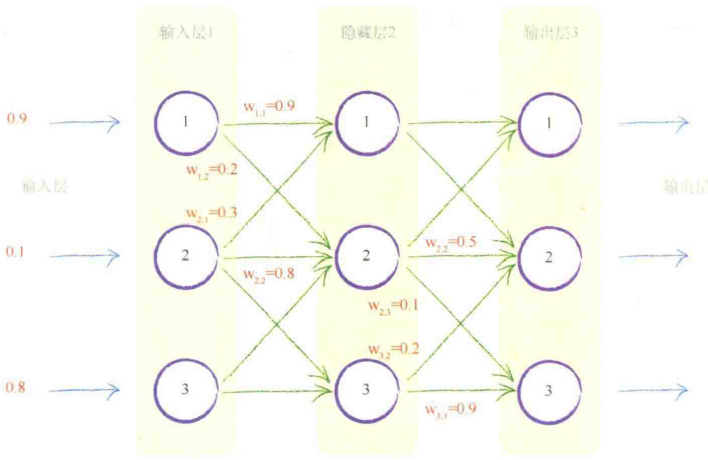
第一层:输入层 表示输入
最后一层:输出层
中间层:隐藏层(不需要显式表示为输出) 计算输入到中间层每个节点的组合信号
组合输入信号,应用链接权重调节输入信号,应用激活函数,生成这些层的输出信号
$X_{output}=W_{hidden\, output}·O_{hidden}$
将神经网络的输出值和训练样本中的输出值比较求得误差,并利用误差调整神经网络输出值。
一种思想:让所有造成误差的节点中不平分误差。根据每条链接对误差所做贡献的比例(根据链接的权重的大小),分割误差。
正向传播:用权重将信号从输入向前传播到输出层
反向传播:用权重将误差从输出向后传播到网络
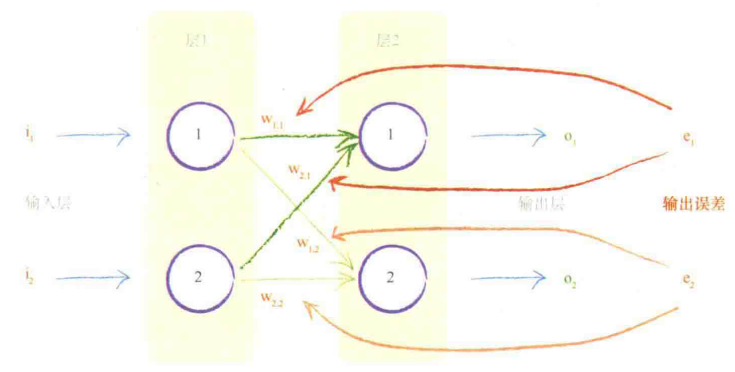
跨越造成误差的多条链接,按权重比例,分割出节点误差。
进入一个输出节点的链接并不依赖于到另一个输出节点的链接。
第一个输出节点的误差$e_1$=训练数据$t_1$提供的期望输出值 - 实际输出值$o_1$
同理第一个输出节点的误差$e_2$
用来更新$W_{1,1}$的$e_1$的一部分为$\displaystyle{\frac{w_{1,1}}{w_{1,1}+w_{2,1}}}$
用来更新$W_{2,1}$的$e_1$的一部分为$\displaystyle{\frac{w_{2,1}}{w_{1,1}+w_{2,1}}}$
思想:误差$e_1$要分割更大的值给较大的权重,分更小的值给较小的权重。
- 用矩阵乘法进行反向误差传播(尝试将过程矢量化)
利用计算中的相似性,相对简单地以矩阵形式表达大批量的计算。
计算起始点:在神经网络最终输出层中出现的误差

为隐藏层的误差构建矩阵
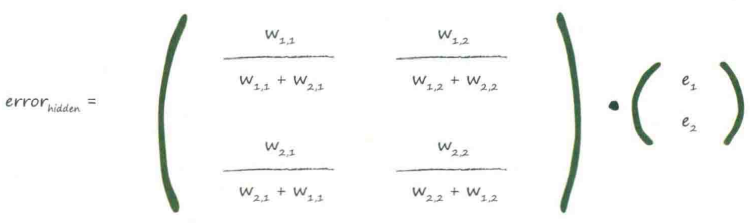
观察上式,最重要的:输出误差与链接权重$W_{ij}$的乘法
大权重→携带较多输出误差给隐藏层
而分数的分母是一种归一化因子,忽略后仅仅失去后馈误差大小
可以用$e_1*W_{1,1}$代替$\displaystyle{ e_1 * \frac {W_{1,1}} {W_{1,1}+W_{2,1}} }$
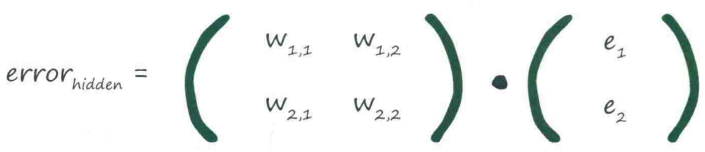
前面的和权重矩阵很像,但差一个转置

让误差反向传播到网络的每一层的原因:可以用误差指导调整链接权重,来改进神经网络输出的总体答案。
啊啊啊三层三节点网络其实很复杂的
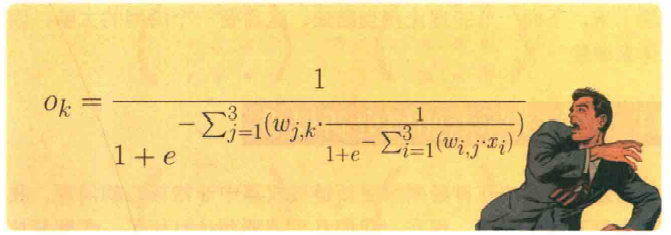
吓死宝宝了(笑)
节点i处输入为$x_i$,连接输入层节点$i$到隐藏层节点$j$的链接权重$W_{i,j}$
隐藏层节点j的输出$x_j$,链接隐藏层节点j和输出层节点$k$的链接权重$W_{j,k}$
embrace悲观主义——能表示所有权重如何生成神经网络输出的数学表达式也太复杂了;权重组合也太多了,怎么可能一个一个试出最好的组合啊!况且训练数据还可能不够,或者根本就是有错的,那怎么能训练出好的网络呢?就算数据是好的,如果神经网络不够复杂(层或节点数不够),训练出的模型还是不能很好地解决问题吧……
那就让我们来爬山吧!
山,无处不在。(此处引用刘慈欣的《山》,它真的好好看,学完快去看!)
如果是在夜里爬山,没法联网看全局地图,只有寒酸又微弱的手机手电筒,看不了太远,咋办呢?
找到看起来是可以下山的方向,往这个方向走就是了。【此所谓梯度下降】
如果找到最陡的坡度向下的地方,应该能更快到山底吧!
如果前面梯度是负的,继续往前走,如果前面梯度是正的,那就往后退。
还有步子不要太大,要不然可能会在最小值上方的地方来回走,甚至错过最小值。
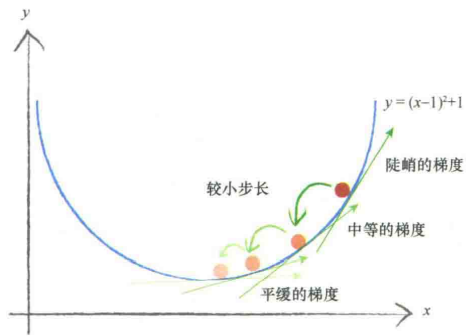
务必记住:正梯度意味着减小$x$,负梯度意味着增加$x$

中间——卡住了
常使用差的平方即$($目标值-实际值$)^2$的原因
①容易进行代数计算
②误差函数平衡连续,梯度下降很顺利
③越接近最小值,梯度越小,超调的风险变小
两个链接权重的情况:误差函数是三维曲面,曲面随两个链接权重的变化而变化
努力最小化误差就像在多山的地形中寻找山谷
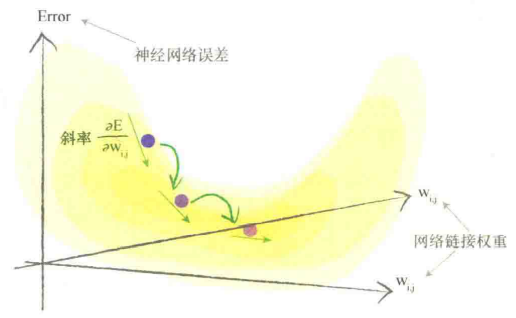
误差函数的斜率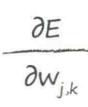 :当权重$W_{j,k}$改变时,误差$E$是如何改变的
:当权重$W_{j,k}$改变时,误差$E$是如何改变的
注: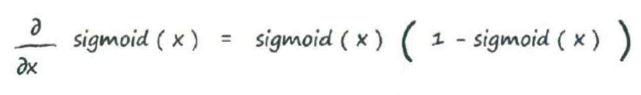
开始计算!
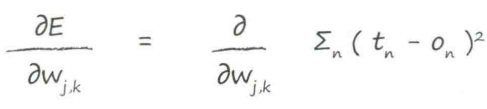

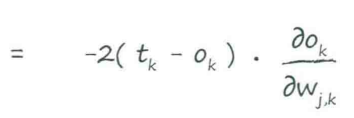
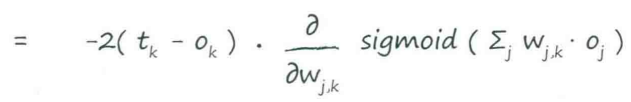
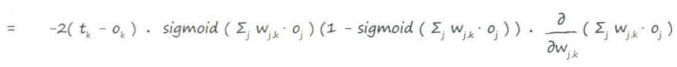
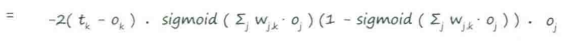
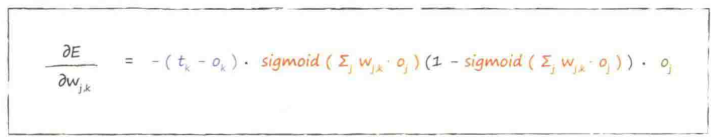
↑训练神经网络的关键
第一部分:(目标值-实际值),令其为$e_j$
sigmoid中的求和表达式:进入最后一层节点的信号$i_k$
应用激活函数前进入节点的信号,令其为$i_j$
最后一部分:前一隐藏层节点$j$的输出,令其为$o_i$
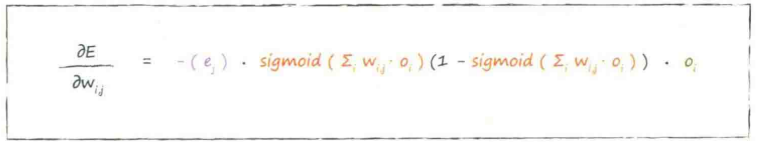
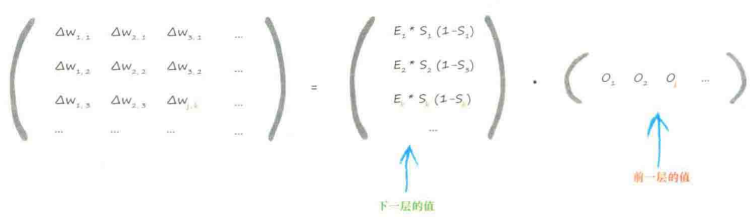
在应用每层训练样本后,更新权重。用学习因子调节变化。

更新后的权重,由刚得到的误差斜率取反来调整旧的权重得到的
(别忘了要对斜率取反哦!)
α:学习率,确保不超调

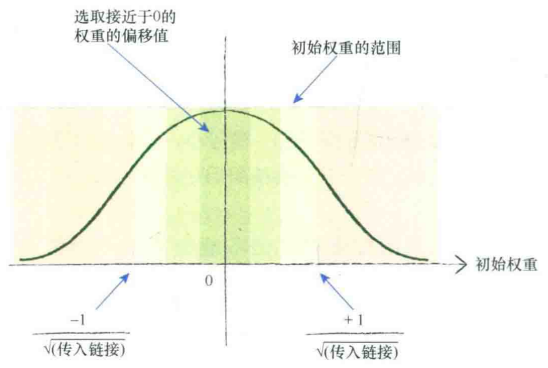
对特定形状的网络和特定的激活函数,数学家和计算机科学家以数学计算得到经验法则,设置了随机初始权重。(非常“特定的”!)
核心思想:如果很多信号进入一个节点,而且这些信号的节点表现不错,则对这些信号组合、应用激活函数时,权重要支持保持这些表现良好的信号。(别让权重破坏了已精调好的输入信号!)
经验规则:在一个节点传入链接数量平方根倒数的大致范围内随机采样,初始化权重。
过大的初始权重会在偏置方向偏置激活函数,导致激活函数饱和。
一个节点传入链接越多,越多的信号被叠加在一起。
链接更多,则减小权重范围。
从概率分布角度(前提:可替代的激活函数tanh(),输入信号的特定分布):从均值=0,标准差=节点传入链接数量平方根倒数的正态分布中采样。
初始权重别都一样(否则每个节点接受相同信号值,输出相同信号值),千万别都为0(输入信号为0,完全无法更新)就行。
【本书理论部分完结!】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号