吴恩达机器学习复习2:多重特征、多重变量的梯度下降、梯度下降实践Ⅰ:数据特征缩放、梯度下降实践Ⅱ:学习率、特征和多项式回归、正规方程法、向量化
【多重特征】
多变量线性回归
可以有任何输入变量的等式的表示方法

假设

使用矩阵乘法的定义,我们的多变量假设功能可以被简洁地描述为
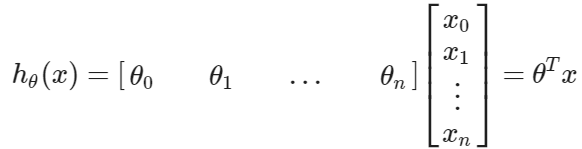
这是未来我们为训练例子的准备的假设函数的向量化
【多重变量的梯度下降】
假设
参数
代价函数
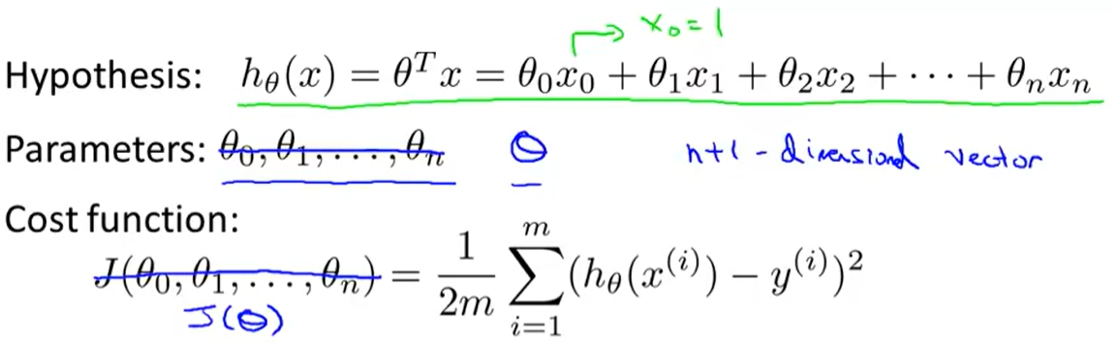


梯度下降的步骤
原来的算法(n=1)
反复做{
角度0 = 原角度0-学习率 *(1/m) 求和[ 假设函数值-实际函数值 ]
角度1 = 原角度1-学习率 *(1/m) 求和[(假设函数值-实际函数值)* 自变量 ]
}
新的算法(n>=1)
反复做{
角度j = 原角度1-学习率 *(1/m) 求和[(假设函数值-实际函数值)* 自变量 ]
}
【梯度下降实践Ⅰ:数据特征缩放】
思想: 使得确定的特征在一个相似的衡量尺度上
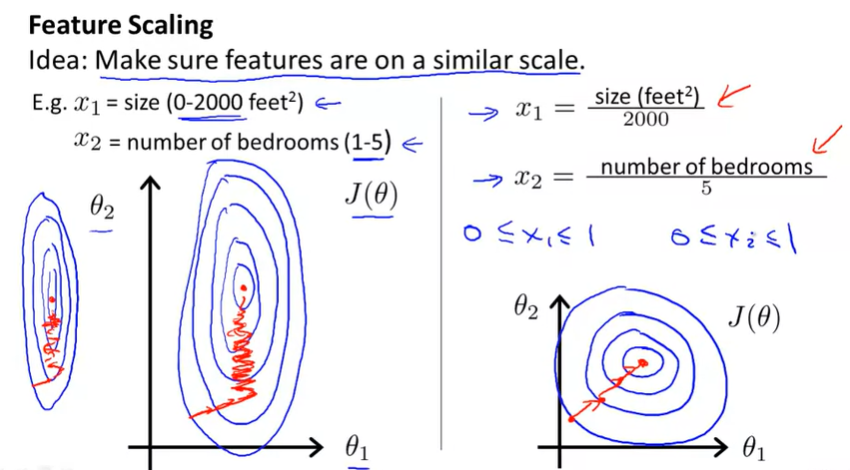
平均值归一化
把x换成x-μ,使特征接近大约零平均值

标准化
现在你知道了特征放大,如果你运用这个简单的技巧,它会让梯度下降运行得更快,并且在更小的迭代步数里收敛。
把你的输入值以粗略的相同的范围,加速梯度下降
【梯度下降实践Ⅱ:学习率】

debug除错:使得梯度下降正确工作
如何选择除错率?
找到你希望用来最小化代价函数的theta值
x轴代表梯度下降的迭代次数

迭代100次后得到一个theta,又得出一个代价函数J(theta)。

当梯度下降不能正常工作时
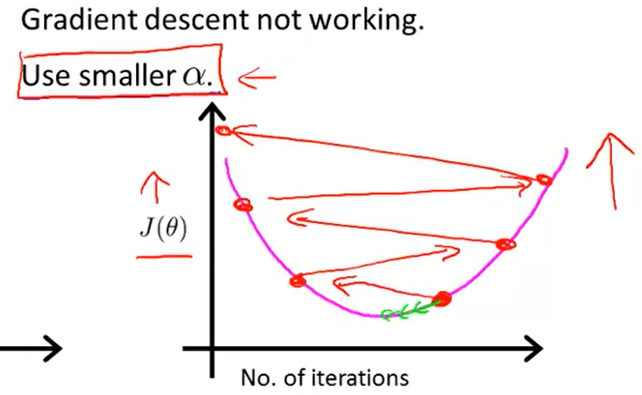
有关学习率选择与梯度下降图像的选择题
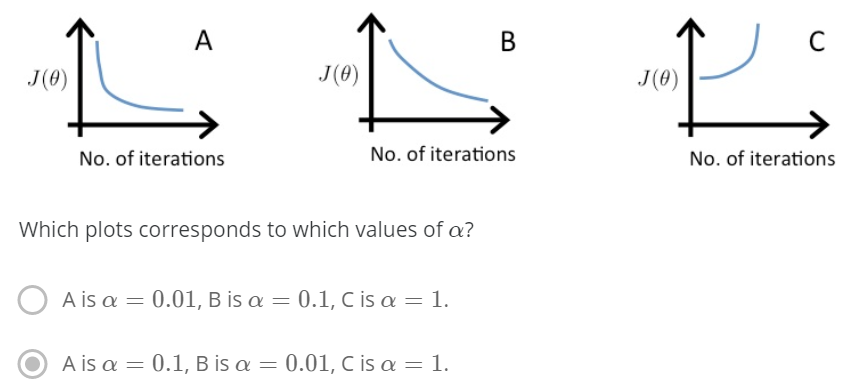
在图C中,代价函数值在增加,说明学习率太高了
A和B都收敛到一个代价函数的最优点,但是B收敛太慢了,说明学习率太低

总结:
学习率太小:收敛慢
学习率太大:代价函数随迭代次数增加而增加,甚至不收敛
{为梯度下降除错}
画一个该梯度下降的迭代次数与代价函数值的图
如果代价函数甚至增加了,你可能需要减小学习率啦
{自动收敛测试}
如果代价函数每次都比E(10的-3次方)减少得还要慢,说明是收敛的
然而实际上很难选择门槛值
【特征和多项式回归】
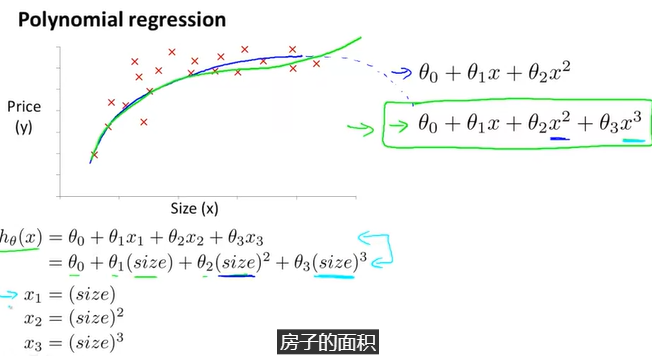
提高特征和假设函数的形式,以一系列不同的方式
{多项式回归}
我们的假设函数不需要是线性,如果能和数据拟合得很好的话
我们可以改变行为或我们假设函数的曲线,通过制造一个二次的、三次的或平方根函数(或任何形式)
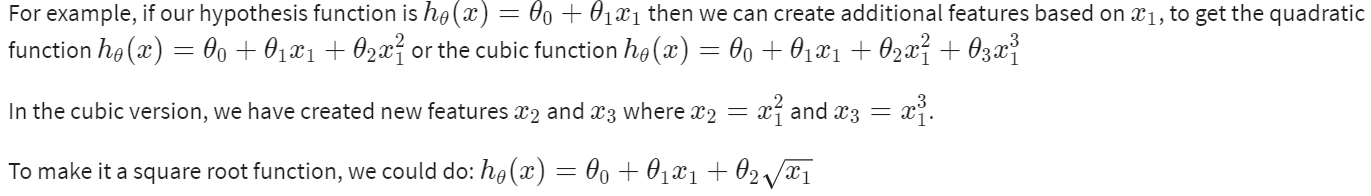
注意:如果你以这种方式选择特征,那么特征缩放就变得很重要了!
【正规方程法】
在正规方程法的方法中,通过对theta j求导,最小化代价函数,然后把它们设为0.
这让我们得以不用迭代就能找到最优化值。
![]()
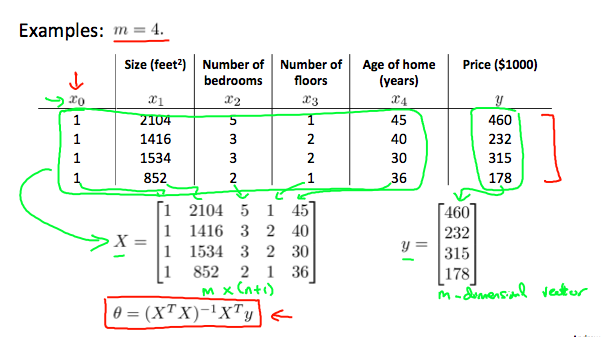
不需要用正规方程法做特征缩放
*梯度下降法和正规方程法的比较

用正规方程法计算转置有O(n^3)的复杂度
所以如果我们有更大数量的特征,那么用正规方程法就会很慢。
实际上,当n超过1万时,从正规解法到迭代过程会有一个很好的时间。

正规方程的不可逆
在matlab里执行正规方程时,我们一般用pinv功能,它能返回theta值(即使X^TX不可逆的时候)
常见的原因是:
1.冗余的特征,有两个特征是相关的(尽管不是线性独立)
2.太多的特征了。在本例中,删除一些特征或使用归一化
解决方法:
1.删除互相线性独立的一个特征
2.如果特征太多了,删除一个或多个特征
【向量化】
向量化的例子
h(x)=sum(theta_j*x_j)=theta^T*x



%matlab %未向量化执行法 prediction=0.0; for j=1:n+1; prediction=prediction+theta(j)*x(j) end; double prediction =0.0; for(int j = 0;j<=n;j++) prediction+=theta[j]*x[j]; %向量化执行方法 prediction=theta'*x; double prediction=theta.transpose()*x;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号