吴恩达机器学习复习1:监督学习、无监督学习、模型表示、损失函数、直觉Ⅰ、直觉Ⅱ、梯度下降及其直觉、线性回归的梯度下降
【说在前面】
1.只是知道算法和数学,而不知道如何将算法实际运用于你所关心的问题并不是一件好事。
2.花点时间做些有关算法每个步骤的练习,看看你能否理解它们是如何工作的。
【机器学习定义】
不用精确编程也能让计算机有能力学习的研究领域(Arthur Samuel,older, informal)
从经验中学习关于某些类别的任务T和表现度量P,并且在做任务T时,在P标准的衡量下,提高了对经验的学习的计算机程序。(Tom Mitchell,modern)
聚类:收集一百万种基因,找到自动分类相似基因(如依据寿命、位置、功能等)的方法
非聚类:"Cocktail Party Algorithm"帮助我们在混乱的环境里找到结构
从鸡尾酒派对杂乱的声音堆里找到单独的声音和音乐
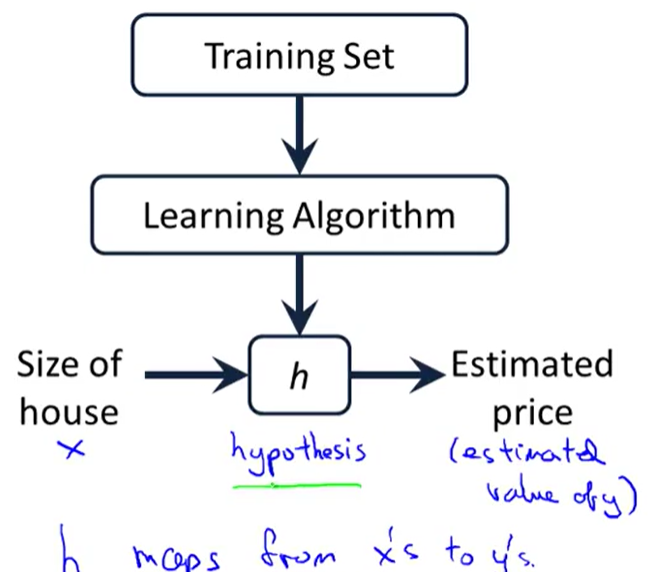
【模型表示】
回归问题:连续值如预测房价
分类问题:离散值如预测一个住所是房子还是公寓
【代价函数】Cost Function
均方误差Squared error function/Mean squared error
用途:衡量预测的准确性(利用预测结果与实际输出)
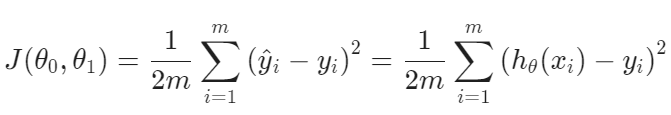

【直觉Ⅰ】
尝试最小化代价函数:选择最恰当的theta使J最小
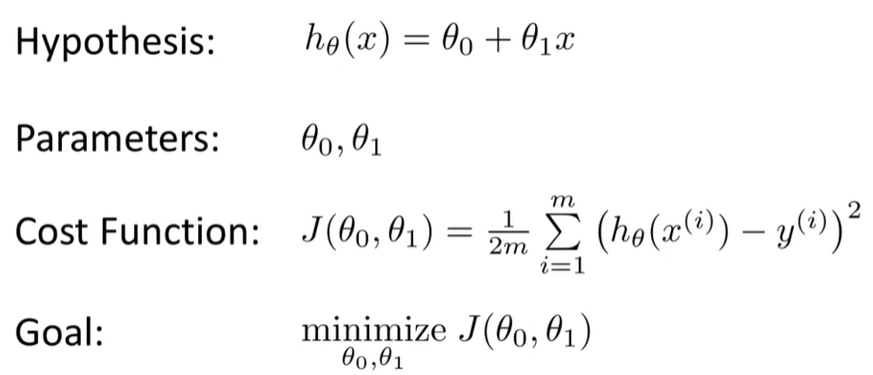
【梯度下降】

![]()

如果再在某个方向迈出小小的一步,并且希望下山越快越好,应该在哪个方向迈步呢?
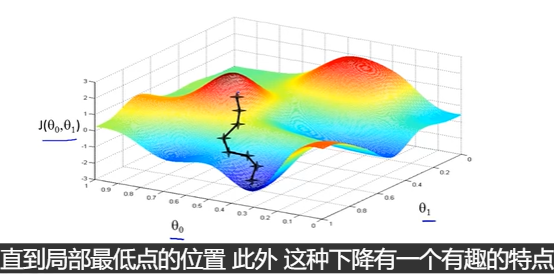
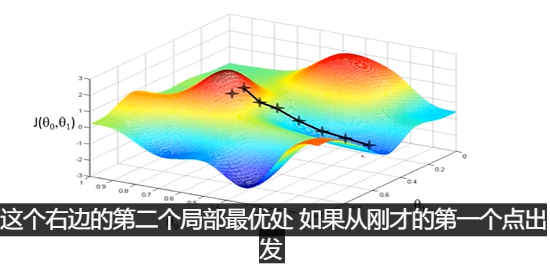
有两种方法可以到两个局部最优处
此外对于每一个j,需要同时更新参数(非常重要!!!)


【梯度下降的直觉】
 斜坡是负的,theta1的值增加;斜坡是正的,theta1的值减少
斜坡是负的,theta1的值增加;斜坡是正的,theta1的值减少

α即学习率太小,梯度下降很慢
α太大,梯度下降很快,但也许无法收敛,甚至发散!
所以需要调整α,确保梯度下降算法在合适的时间收敛
无法收敛或收敛太慢都说明做错了(α值错了)

到局部最小处,梯度下降自然会缩小步子,不需要随时间增加α
【线性回归的梯度下降】

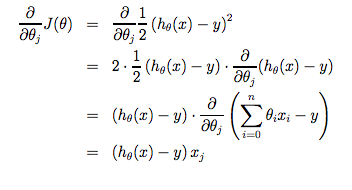
梯度下降可能受局部最优解的影响,而这里最优化问题只有一个全局而没有其他局部最优解,所以梯度下降总是可以收敛到全局最优解
α是固定的也可以收敛!
对于线性回归里特殊的损失函数的特殊形式,依然没有局部最优解


这是一张(等高线?)图,显示了theta的收敛过程

