合并pdf文件带书签代码(利用python的PyPDF2,并解决PyPDF2 编码问题'latin-1'和PyPDF2报错:PdfReadError: EOF marker not found)
1.文件准备:
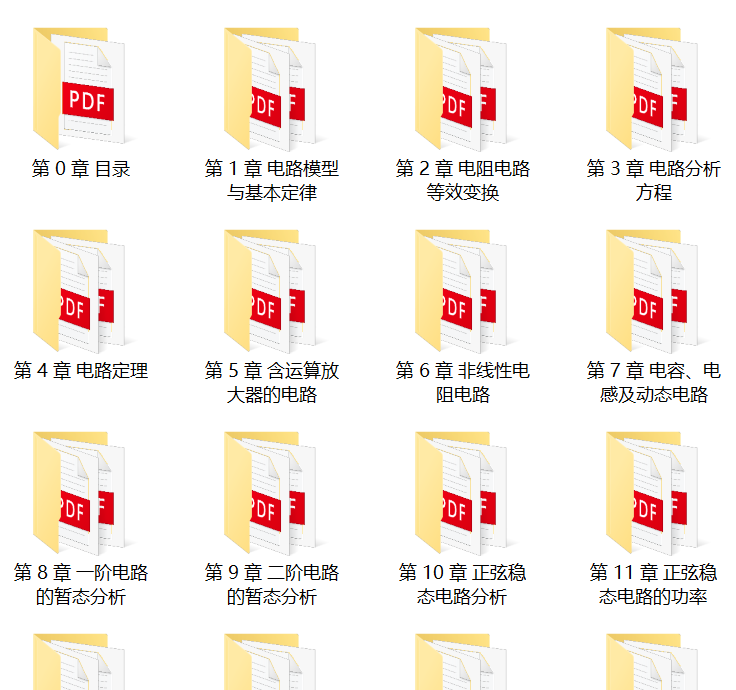
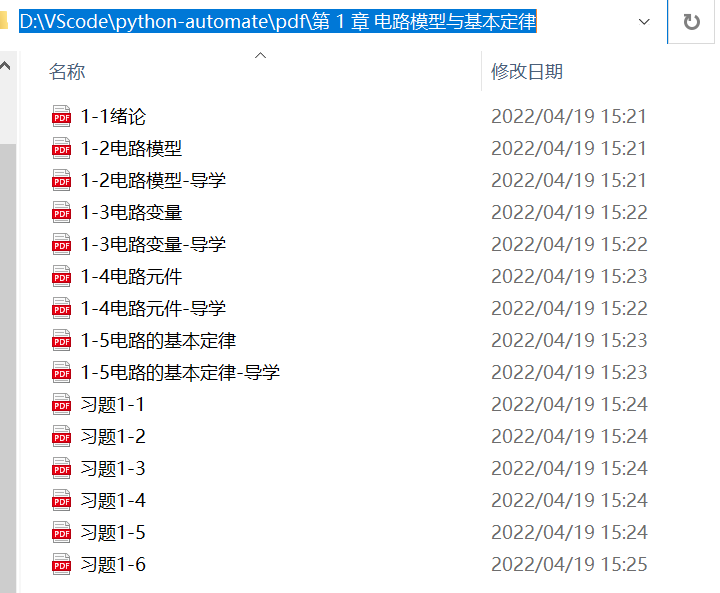
先将扫描的pdf文件,每一章放到一个文件夹中,文件夹名字用章节名命名。
这样最终程序就能将章节名作为书签了,而不是默认将每页都生成书签。
【最新代码,更新PyPDF2后可用】用的3.8的python 2023.1.25更新
# -*- coding: utf-8 -*-
'''
本脚本用来合并pdf文件,支持带一级子目录的
每章内容分别放在不同的目录下,目录名为章节名
最终生成的pdf,按章节名生成书签
'''
import os
import sys
import codecs
from PyPDF2 import PdfReader, PdfFileWriter, PdfMerger
import glob
def getFileName(filepath):
'''
获取当前目录下的所有pdf文件
'''
file_list = glob.glob(filepath + "/*.pdf")
# 默认安装字典序排序,也可以安装自定义的方式排序
# file_list.sort()
return file_list
def get_dirs(filepath='', dirlist_out=[], dirpathlist_out=[]):
# 遍历filepath下的所有目录
for dir in os.listdir(filepath):
dirpathlist_out.append(filepath + '\\' + dir)
return dirpathlist_out
def merge_childdir_files(path):
'''
每个子目录下合并生成一个pdf
'''
dirpathlist = get_dirs(path)
if len(dirpathlist) == 0:
print("当前目录不存在子目录")
sys.exit()
for dir in dirpathlist:
mergefiles(dir, dir)
def mergefiles(path, output_filename, import_outline=False):
# 遍历目录下的所有pdf将其合并输出到一个pdf文件中,输出的pdf文件默认带书签,书签名为之前的文件名
# 默认情况下原始文件的书签不会导入,使用import_outline=True可以将原文件所带的书签也导入到输出的pdf文件中
merger = PdfMerger()
filelist = getFileName(path)
if len(filelist) == 0:
print("当前目录及子目录下不存在pdf文件")
sys.exit()
for filename in filelist:
f = codecs.open(filename, 'rb')
file_rd = PdfReader(f)
short_filename = os.path.basename(os.path.splitext(filename)[0])
if file_rd.is_encrypted == True:
print('不支持的加密文件:%s' % (filename))
continue
merger.append(file_rd,
outline_item=short_filename,
import_outline=import_outline)
print('合并文件:%s' % (filename))
f.close()
# out_filename = os.path.join(os.path.abspath(path), output_filename)
merger.write(output_filename + ".pdf")
print('合并后的输出文件:%s' % (output_filename))
merger.close()
if __name__ == "__main__":
# 每个章节一个子目录,先分别合并每个子目录文件为一个pdf,然后再将这些pdf合并为一个大的pdf,这样做目的是想生成每个章节的书签
# 1.指定目录
# 原始pdf所在目录(自行修改)
path = "D:\信号与系统"
# 输出pdf路径和文件名(自行修改)
output_filename = "D:\信号与系统"
# 2.生成子目录的pdf
# merge_childdir_files(path)
# 3.子目录pdf合并为总的pdf
mergefiles(path, output_filename)
2.程序代码
代码运行环境:python310
根据文件和文件夹所在位置改下面荧光黄的代码部分即可
# -*- coding: utf-8 -*-'''
本脚本用来合并pdf文件,支持带一级子目录的
每章内容分别放在不同的目录下,目录名为章节名
最终生成的pdf,按章节名生成书签
'''
import os
import sys
import codecs
from PyPDF2 import PdfFileReader, PdfFileWriter, PdfFileMerger
import glob
def getFileName(filepath):
'''
获取当前目录下的所有pdf文件
'''
file_list = glob.glob(filepath + "/*.pdf")
# 默认安装字典序排序,也可以安装自定义的方式排序
# file_list.sort()
return file_list
def get_dirs(filepath='', dirlist_out=[], dirpathlist_out=[]):
# 遍历filepath下的所有目录
for dir in os.listdir(filepath):
dirpathlist_out.append(filepath + '\\' + dir)
return dirpathlist_out
def merge_childdir_files(path):
'''
每个子目录下合并生成一个pdf
'''
dirpathlist = get_dirs(path)
if len(dirpathlist) == 0:
print("当前目录不存在子目录")
sys.exit()
for dir in dirpathlist:
mergefiles(dir, dir)
def mergefiles(path, output_filename, import_bookmarks=False):
# 遍历目录下的所有pdf将其合并输出到一个pdf文件中,输出的pdf文件默认带书签,书签名为之前的文件名
# 默认情况下原始文件的书签不会导入,使用import_bookmarks=True可以将原文件所带的书签也导入到输出的pdf文件中
merger = PdfFileMerger()
filelist = getFileName(path)
if len(filelist) == 0:
print("当前目录及子目录下不存在pdf文件")
sys.exit()
for filename in filelist:
f = codecs.open(filename, 'rb')
file_rd = PdfFileReader(f)
short_filename = os.path.basename(os.path.splitext(filename)[0])
if file_rd.isEncrypted == True:
print('不支持的加密文件:%s' % (filename))
continue
merger.append(file_rd,
bookmark=short_filename,
import_bookmarks=import_bookmarks)
print('合并文件:%s' % (filename))
f.close()
# out_filename = os.path.join(os.path.abspath(path), output_filename)
merger.write(output_filename + ".pdf")
print('合并后的输出文件:%s' % (output_filename))
merger.close()
if __name__ == "__main__":
# 每个章节一个子目录,先分别合并每个子目录文件为一个pdf,然后再将这些pdf合并为一个大的pdf,这样做目的是想生成每个章节的书签
# 1.指定目录
# 原始pdf所在目录
path = "D:\VScode\python-automate\pdf\第 01 章 电路模型与基本定律"
# 输出pdf路径和文件名
output_filename = "D:\VScode\python-automate\pdf\第 01 章 电路模型与基本定律"
# 2.生成子目录的pdf
# merge_childdir_files(path)
# 3.子目录pdf合并为总的pdf
mergefiles(path, output_filename)
3.进一步合成

此时目标路径会出现上述文件,若代码运行成功后打开pdf无异常则表示第一章pdf已经合并好
且有每个文件名的标签,接下来只需要对每个章节再次进行合并即可(很可惜我把所有章节合并后subtitle消失了)
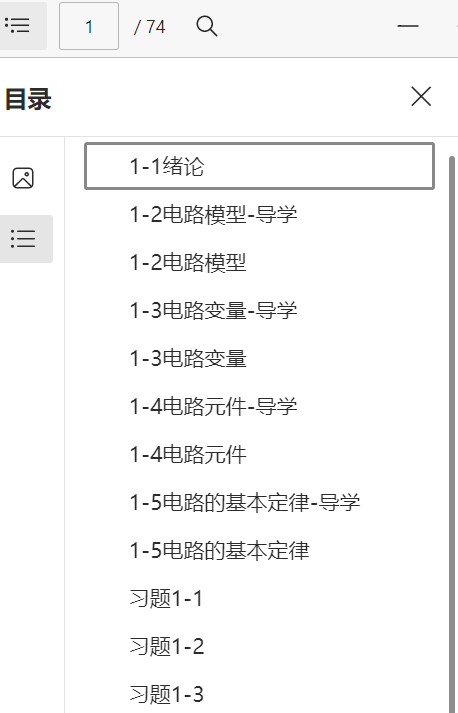 合并完全部
合并完全部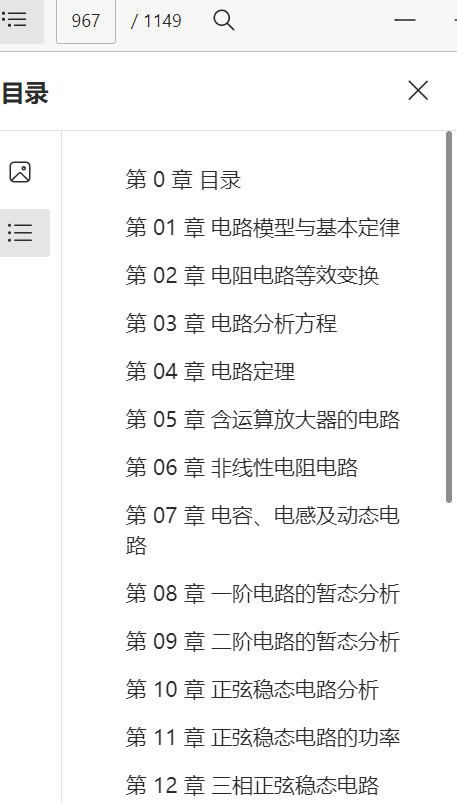
4.可能出现的问题
①PyPDF2 编码问题'latin-1' codec can't encode characters in position 8-11: ordinal not in range(256)
通常这情况是出现了中文字符编码
解决方法
1、修改pypdf2包中的generic.py文件
我的目录是c:\……python310\Lib\site-packages\PyPDF2\generic.py
1)generic.py文件第488行原文
try:
return NameObject(name.decode('utf-8'))
except (UnicodeEncodeError, UnicodeDecodeError) as e:
# Name objects should represent irregular characters
# with a '#' followed by the symbol's hex number
if not pdf.strict:
warnings.warn("Illegal character in Name Object", utils.PdfReadWarning)
return NameObject(name)
else:
raise utils.PdfReadError("Illegal character in Name Object")
改成
try:
return NameObject(name.decode('utf-8'))
except (UnicodeEncodeError, UnicodeDecodeError) as e:
try:
return NameObject(name.decode('gbk'))
except (UnicodeEncodeError, UnicodeDecodeError) as e:
# Name objects should represent irregular characters
# with a '#' followed by the symbol's hex number
if not pdf.strict:
warnings.warn("Illegal character in Name Object", utils.PdfReadWarning)
return NameObject(name)
else:
raise utils.PdfReadError("Illegal character in Name Object")
以及
2)修改pypdf2包中的utils.py文件
utils.py238行原文
r = s.encode('latin-1')
if len(s) < 2:
bc[s] = r
return r
改成
try:
r = s.encode('latin-1')
if len(s) < 2:
bc[s] = r
return r
except Exception as e:
print(s)
r = s.encode('utf-8')
if len(s) < 2:
bc[s] = r
return r
②PyPDF2报错:PdfReadError: EOF marker not found
查到的解决方法有
1)把文件复制到别的文件夹
2)打开文件再重新保存
3)(我自己)打开pdf发现有些pdf打开失败于是重新合成
参考:
————————————————
版权声明:本文为CSDN博主「huahuazhu」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:使用python合并pdf文件带书签_huahuazhu的博客-CSDN博客_python 合并pdf
版权声明:本文为CSDN博主「huahuazhu」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:使用python合并pdf文件带书签_huahuazhu的博客-CSDN博客_python 合并pdf
版权声明:本文为CSDN博主「小羊瓜瓜的博客」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
