论文阅读|解释你的动作:基于特异性和相关性的可解释强化学习
引言:
强化学习(Reinforcement Learning, RL)是一种有效的解决序列决策问题的方法。近年来,结合了深度神经网络之后,深度强化学习(Deep Reinforcement Learning, DRL)被广泛地应用于各种领域。但是,当前的DRL算法使用神经网络学习到的策略,通常是一个黑盒。针对这种情况,可解释强化学习(Explainable Dep Reinforcement Learning, XDRL)应运而生。
问题背景:
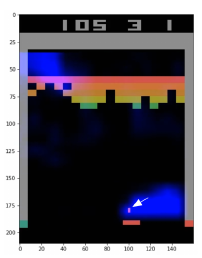
随着DRL被应用于越来越多的任务之中,我们越来越需要一种能够可视化和理解所训练的智能体(agent)行为的方法。其中一种主流的方法称之为显著图(saliency map)。这是一种通过高亮输入状态中对于agent所采取的动作最相关部分的状态特征来可视化地解释智能体行为的方法。 举一个具体的例子,下图是Atari游戏中的打砖块(Breakout),agent需要左右移动挡板接住小球使其反弹击中上方的砖块,击打掉越多分数越高。图中的蓝色荧光标记了影响agent决策的一些重要特征。其中,有两个区域被标注上了蓝色,一个是小球的区域,另一个是左上方较为残缺的位置。我们从直观上可以理解,小球的位置比较重要,因为接不到小球,游戏就结束了。左上角的残缺位置,则是获得高分的关键。通过将小球打穿残缺位置,我们就能把小球送到砖块后面,从而产生许多反弹击打砖块。因此,我们可以解释说agent根据高亮部分的特征作出了相应的动作。
具体而言,对于一个已经训练好的agent \(M\), 让它采取贪心策略,也就是\(â = argmax_a Q(s,a)\), 这里的\(Q\)是动作价值函数,表示在状态\(s\)采取动作\(a\)之后,能够得到的期望收益。我们将一个状态分解为各个特征,例如对于国际象棋,64个落子位表示了64个特征,对于Atari游戏,特征可以是每一个像素点。我们想要知道是\(s\)中的什么特征,导致了agent采取了\(â\)的动作。每一个特征会推算出一个Saliency 值来,根据Saliency来高亮相应的特征。
这里是使用saliency map来进行XDRL的几种方法。

本文中主要介绍基于扰动(perturbation-based)的saliency map。基本思想是对于每一个特征\(f\),给出一个扰动从\(s\)到达\(s’\),扰动方法可以是给特征f增加一个高斯模糊,或者直接去除状态f的信息。然后,根据某种评判方法来计算从\(s\)到\(s'\)的变化\(s[f]∈(0,1)\),变化越大,说明该特征对于所采取的动作\(â\)越重要。因此基于扰动的方法的区别,主要就体现在评判方法的区别上。
研究论文:
ICLR2020(International Conference on Learning Representations)的一篇文章 《Explain Your Move: Understanding Agent Actions Using Specific and Relevant Feature Attribution 》 针对于目前存在的perturbation-based saliency map所存在的问题提出了自己的改进方法SARFA。它首先介绍了之前的两种方法。第一种方法Greydanus et al. (2018)认为我们需要关注策略和状态价值函数的变化,因此提出使用\(S_1[f] = \frac{1}{2}|π_s-π_s'|^2\)和\(S_2[f] = \frac{1}{2}|V_s-V_s'|^2\)的组合。第二种方法 Iyer et al. (2018)则着眼于动作价值函数,认为\(S[f] = Q(s,â)-Q(s',â)\)。
文章提出了它认为评判方法应该具有的两个特性。一:特异性(Specificity),计算当前特征的扰动对要解释的动作的影响程度。影响程度越大的特征,\(S[f]\)越高。二:相关性(Relevance),计算当前特征的扰动对其他动作的干扰,干扰越小,\(S[f]\)越高。
文中指出前两种方法都缺少这两个特性,第一个方法\(S1[f] = \frac{1}{2}|π_s-π_s'|^2\)和\(S_2[f] = \frac{1}{2}|V_s-V_s'|^2\)关注状态和策略的变化,丧失了对于每一个动作本身的影响。第二个方法\(S[f] = Q(s,â)-Q(s',â)\)在某些程度上关注了动作本身,但是忽略了对于Q函数的影响只与â有关,还是和别的动作也有关系。
文中举了一个下国际象棋的例子来说明之前两种方法缺乏这两个特性。

图\(a\)表示的是原始的盘面,白方落子。agent所给出的最佳动作是让白方的象走\(b6\)实现“抽子”(它能同时攻击后和车,而且有马在\(a5\)保护,因此不会被后吃掉)。第一种方法为图\(c\)中的标注,他标注了\(c6\)的兵,其原因在于去除了\(c6\)的兵之后,使得agent产生了别的动作,导致了\(S1[f] = \frac{1}{2}|π_s-π_s'|^2\)的变化较大,但是根据相关性,这个特征会影响agent产生其他动作,因此它不应该被高亮。第二种方法为图\(b\)中的标注,它标注了\(d1\)的后,原因在于失去了后的整体价值函数都会变低,导致区分不出是什么动作能导致高亮区域,但实际上的\(d1\)的后没有参与“抽子”的战术,不应该被标注为高亮区域,这违背了特异性的思想。
随后文章根据这两个准则,提出了它自己的判断规则。
首先 为了体现特异性,文章计算 \(Q(s,â)\)相对于其他动作 \(Q(s,a)\)的比重的变化,来判断一个特征的saliency 大小。 如果一个特征对于要解释的动作很重要,那\(|Q(s,â)-Q(s',â)|\)一定会很大,但是同时还要保证别的动作\(|Q(s,a)-Q(s',a)|\)不大,这样结合起来就可以表示为图中的\(Δp\)。

类似地,为了体现相关性,文章计算 \(Q(s,a)\)的分布变化,来判断一个特征的saliency大小。 因为a表示的是除â之外的其他动作,因此需要用\(D_{KL}\)来判断变化前后分布的变化,如果分布变化不大,说明对其他动作的影响较小,特征对于\(â\)的相关性很高。

由于\(D_{KL}\)可能无穷大,因此作一个变换。这样\(K\)越大越好。
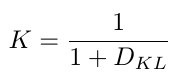
最后 saliency 数值上就取上述两个部分的调和平均。
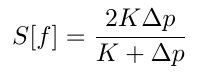
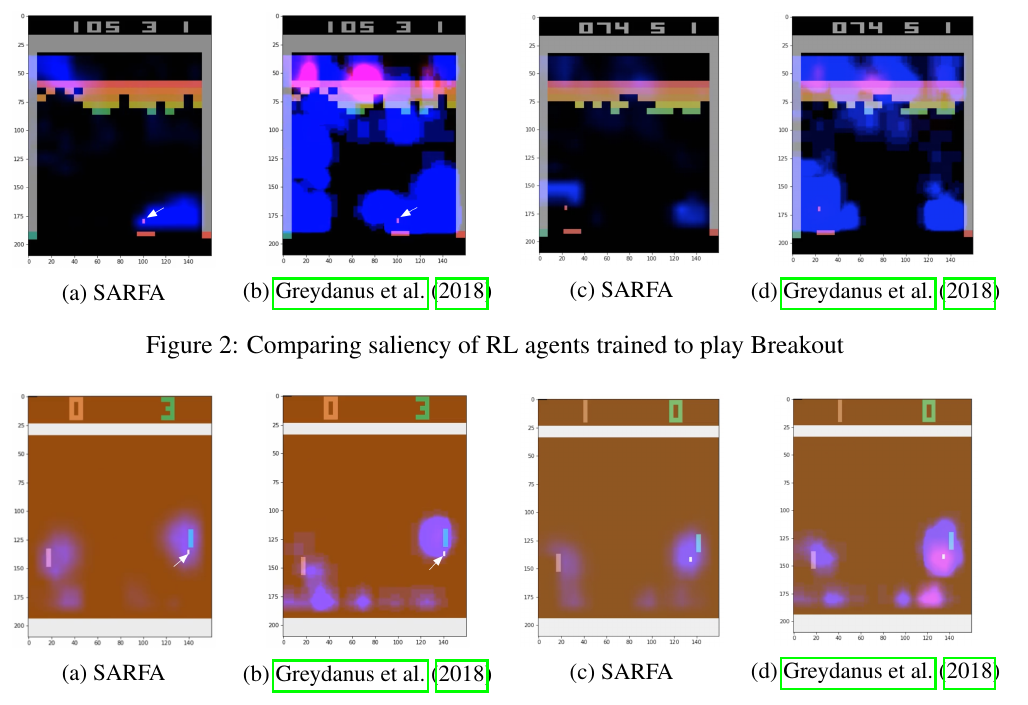
实验方面文章首先对比了SARFA与之前两种方法在Atari游戏,chess,go上的区别,实验结果显示SARFA更加精确的标注了高亮的特征区域。
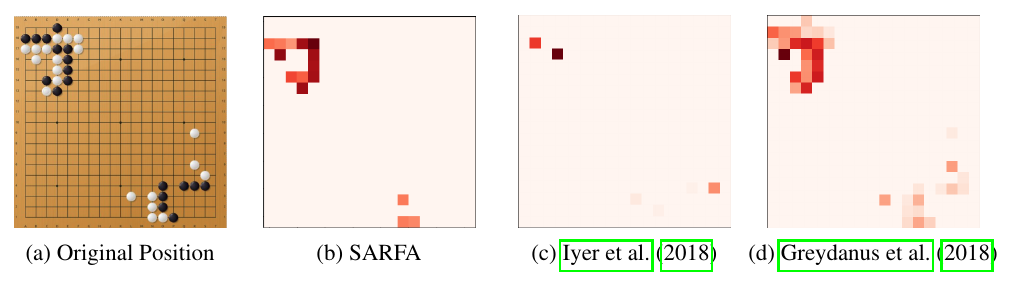
另外,本文还邀请人类棋手解答残局,将产生的saliency map用于解题提示,结果显示相比较前两种方法,棋手的解答结果也有明显的提升。

思考总结:
这篇文章在基于扰动的方法基础上,提出了两个筛选特征的准则,只筛选需要被解释的动作的特征,避免筛选与被解释动作不相关的特征。它更加精确的能够指出产生动作的特征所在,为我们日后分析agent行为提供了更加优良的方法。但是,这篇文章也存在些许不足。将扰动的部位去除,可能导致产生一个不合法的状态。此外,计算saliency时,每一个特征都是独立计算的,这可能忽略特征之间的相关性。总体而言,在XDRL事后解释agent行为上,这篇文章是一个非常不错的尝试。
论文链接:https://openreview.net/pdf?id=SJgzLkBKPB
参考资料:
[1] 知乎.[强化学习 117]Saliency Map[EB/OL].https://zhuanlan.zhihu.com/p/135376948,2020-4-17.
written by asakuras

 浙公网安备 33010602011771号
浙公网安备 33010602011771号