
深入理解空间搜索算法 ——数百万数据中的瞬时搜索
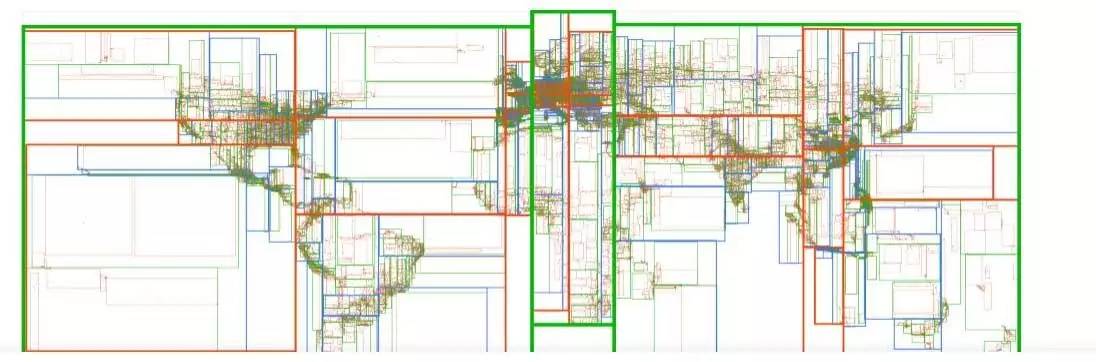
上图为全球138,000个热门地点的R-tree的可视化图示
我这个人沉迷于软件性能的提升,我在Mapbox(https://www.mapbox.com/)的职责之一就是找到能使我们的映射平台更加快速的方法。当面对大规模的空间数据时,一个最有效也是最重要的方法就是空间索引(https://en.wikipedia.org/wiki/Spatial_database#Spatial_index)。
空间索引是一系列可以通过排列几何数据来进行高效索引的算法。例如,查询“本区域所有的建筑”、“距此点最近的1000个加油站”等问题,查询结果往往能够在几毫秒内返回,即使所要查询的目标有几百万个。
空间索引是数据库如PostGIS的基础,同时也是我们平台的核心。在很多其他任务尤其是性能至关重要的任务中,空间索引也非常重要。特别的,在处理遥测数据时,我们需要对数百万个GPS样本与道路网进行匹配,以产生导航所用的实时交通数据。在客户端,我们则需要实时在地图中展示地标,以及在鼠标滞留时查找鼠标所指的目标。
在过去的四年里,我建立了一些快速的用于空间搜索的Java 库,包括:
-
rbush(https://github.com/mourner/rbush),
-
rbush-knn(https://github.com/mourner/rbush-knn/),
-
kdbush(https://github.com/mourner/kdbush),
-
geokdbush(https://github.com/mourner/geokdbush)。
本文中,我会努力将这几个库背后的原理讲解清楚。
空间搜索问题
空间数据有两种基本查询类型:最相邻查询和范围查询。这两种查询都是很多几何问题和GIS问题的基本模块。
K相邻
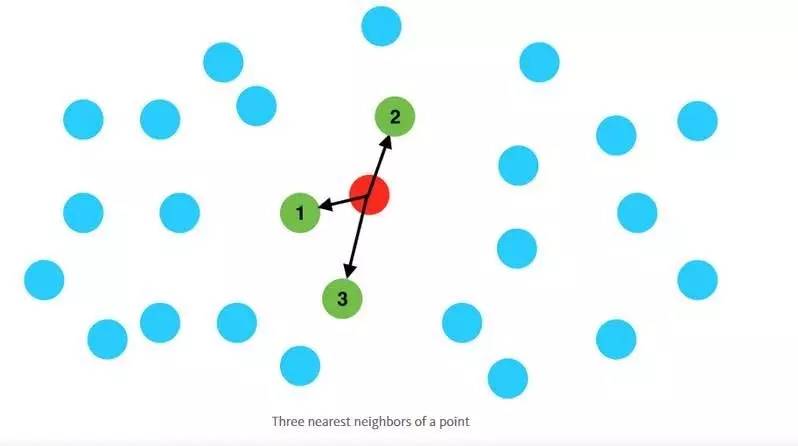
如果给出几千个数据点,如城市的坐标,我们如何检索出与某特定查询点最相邻的点呢?
-
我们很自然想到的方法可能是这样:
-
计算每个点与查询点之间的距离。
-
按距离大小对所有的点进行排序。
-
返回前k个点。
当有几百个数据点时我们可以用这种方法,但是当我们面临数百万的数据点时,这种方法就显得太慢且无法应用到实际情景。
范围查询和半径查询
如何在一个给定的范围内检索出所有的数据点呢?这里又分为两种情况,一种是所给范围是矩形的情况(范围查询),另一种是所给范围是圆的情况(半径查询)。
一种朴素的方法是遍历所有数据点并判断每一个点是否在给定范围内,但当数据集很大时,这种方法也因低效而失去了实用性。
空间树是如何工作的
大规模地解决这两种问题时就需要将数据点转换到空间索引中。由于数据转变的频率会远远少于查询的频率,因此将数据转变到空间索引的花销对于之后的快速搜索是非常值得的。
几乎所有的空间数据结构都具有相同的原理,以实现有效的搜索:分支和绑定(https://en.wikipedia.org/wiki/Branch_and_bound)。数据被排列在一个树状结构中,因此当在某一节点的某一分支不符合查询条件时,该分支之下的所有的节点都可被略过。
R-tree
现在让我们来看一个例子,下图的示例将所有的输入点分在9个矩形框中,并且每个矩形框中的点的数目相同:

现在,我们将每个矩形框再分为9个更小的矩形框:
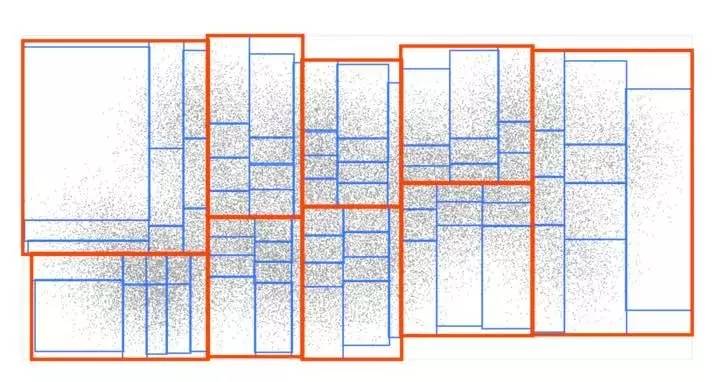
我们会将这个过程重复几次,找到最后每个矩形框包含的点不超过9个:
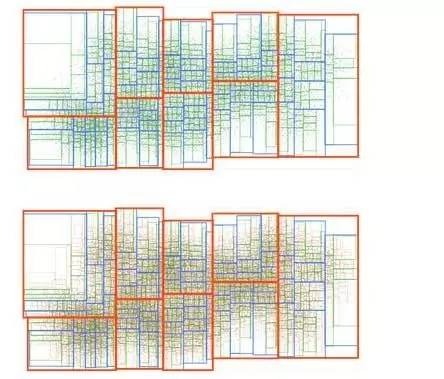
最终我们得到了R-tree(https://en.wikipedia.org/wiki/R-tree),这可以说是最常见的空间数据结构,被广泛用于现代空间数据集和游戏引擎,我的rbush JS库中也实现了R-tree。
除了点之外,R-tree也可以包含矩形,用于表示任何几何对象。同时,R-tree也可扩展到3维或高维的情况。为了易于说明,本文中以二维的情况举例讲解。
K-d tree
K-d tree (https://en.wikipedia.org/wiki/K-d_tree)是另外一种流行的空间数据结构。我的kdbush JS库(https://github.com/mourner/kdbush),用于静态的二维的索引,就是基于K-d tree实现的。K-d tree与R-tree类似,但与在每一层次上将数据点均分到几个矩形框中不同的是,K-d tree会将数据点从中间分为两部分——或左或右,或上或下,每个层次上都会在x坐标和y坐标进行划分,如下图所示:
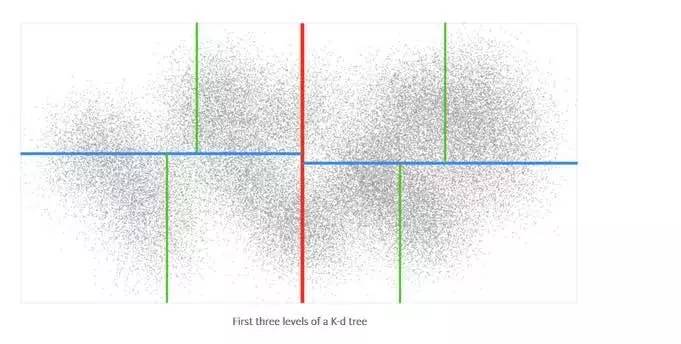
与R-tree相比,K-d tree只能包含数据点而不能包含矩形,并且不能添加或删除点。但是K-d tree在高效的同时更易实现。R-tree和K-d tree 都采用了相同的原则,即将数据组织为树的结构。因此,下文所讨论的搜索算法与树的搜索算法相同。
在树中的范围查询
下图是一个典型的空间树:
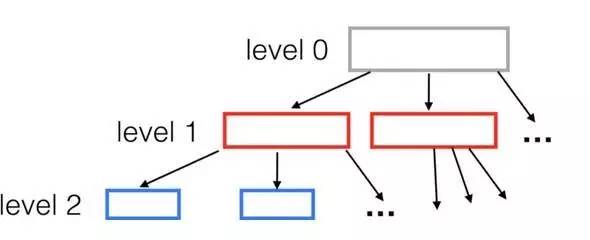
每一个节点的孩子数都固定,本文中R-tree的例子中为9。那么树的深度是多少呢?对于有1,000,000 个节点的树,高度为(log(1000000) / log(9)) = 7。
当我们在树中执行范围搜索算法时,我们可以从树根开始向下,忽略所有不满足查询框的矩形框。对于一个小的查询框,这意味着在树的每一层上只需要搜索几个矩形框即可。因此,得到最终查询结果的时间不会多于60次矩形框的比较(7 * 9 = 63),而不是1,000,000次比较,这使其比原始的循环搜索快了16000倍。
使用R-tree 的范围搜索所用的平均时间为O(K log(N))(这里K是结果的数目),而线性搜索所用时间为O(N)。因此,R-tree的搜索是非常高效的算法。
这里我们选用9作为每一节点的孩子数,9是一个很不错的默认值,但是理论上,越高的数值意味着更快的索引和更慢的查询,反之亦然。
K相邻查询
相邻查询相较于范围查询稍难一些。对于一个特定的查询点,我们怎么知道哪棵子树上的节点与该节点最相邻呢?我们可以做半径查询,但我们不知道如何选择半径的大小——最相邻的点可能在树中离查询点很远的位置。如果靠增加半径来找到一些点又会极大地降低搜索效率。
为了在空间树中找到一些最相邻点,我们会利用另一个简洁的数据结构——优先队列(https://en.wikipedia.org/wiki/Priority_queue)。优先队列会维护一个有序列表,该列表可以将“最小的”元素以很快的速度提取出来。为了更好地理解知识,我通常喜欢从头开始写一个数据结构,因此我写的优先队列的JS库 tinyqueue(https://github.com/mourner/tinyqueue)可能是有史以来最好的优先队列哦。
让我们回顾一下R-tree的例子:
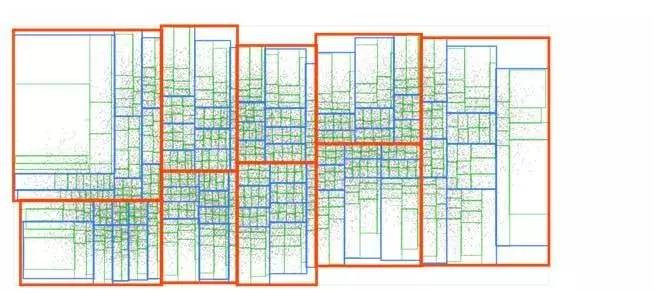
我们可以很直观地想到,与查询点更临近的矩形框可能有我们想要搜索的点。为了有效地利用这一点,我们将按从最近到最远的顺序将最大的矩形框排在队列中,从顶层开始进行搜索:
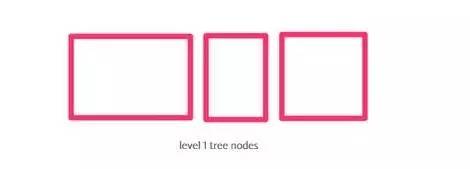
之后,我们“打开”相邻的矩形框,从队列中移除,并将它的孩子(较小的矩形框)放到队列中与其相邻的位置上。
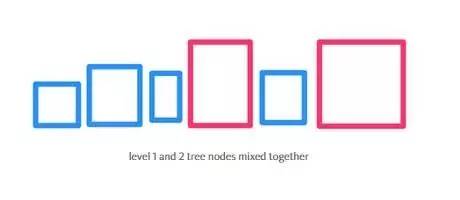
重复上述步骤,当从队列中移除的相邻项是真正的点而不是矩形框时,这就是我们要查找的点了,队列顶部第二个点就是第二个最相邻的点,以此类推。
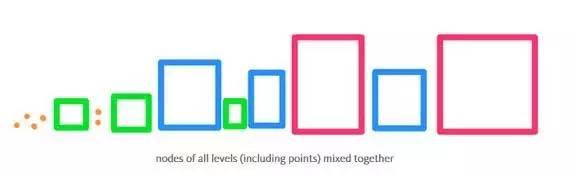
由于我们还未“打开”的矩形框中包含的点比当前矩形框中的点的距离更远,因此我们从队列中取出的任何点都会比剩余的矩形框中的点的距离更近。
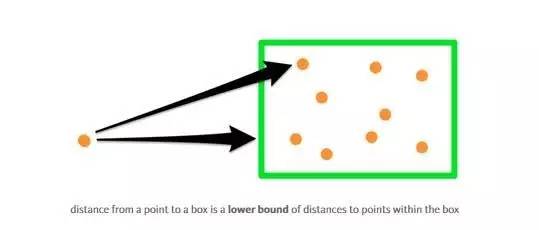
如果我们的空间树很平衡的话,即所有节点的分支数基本相同,那么我们只需处理几个矩形框即可,而忽略其余的矩形框。这种策略使得该算法在搜索过程中非常快速。
在rbush库中,该算法在rbush-knn模块中实现。对于地理信息中的点,我最近发布了另外一个kNN库——geokdbush(https://github.com/mourner/geokdbush)。Geokdbush可以很好地处理地球的曲率和时间线的包装。我真应该专门以geokdbush写一篇文章,因为它是我第一次将微积分应用到实际工作中的项目。
自定义的kNN距离衡量
这种“打开”矩形框的方法是非常灵活的,除了点对点距离之外还适用于其他的距离类型。该算法依赖于查询一个已定义的与矩形框内所有对象之间的距离的下限。如果我们自定义这个下限标准,我们依然可以使用相同的算法。这就意味着,我们可以改变算法使其搜索最接近一条线段的K个点(而不是与一个点最相近的点):
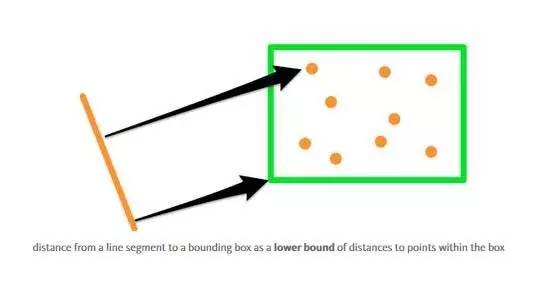
在算法中我们唯一需要改变的就是将点与点之间的距离和点与矩形框之间的距离计算换成线段与点之间的距离和线段与矩形框之间的距离计算。
当我建立Concaveman(https://github.com/mapbox/concaveman)库时——一个JS中快速的2D凹面库,这样做就显得很方便。 它需要很多点,并生成一个如下所示的图:
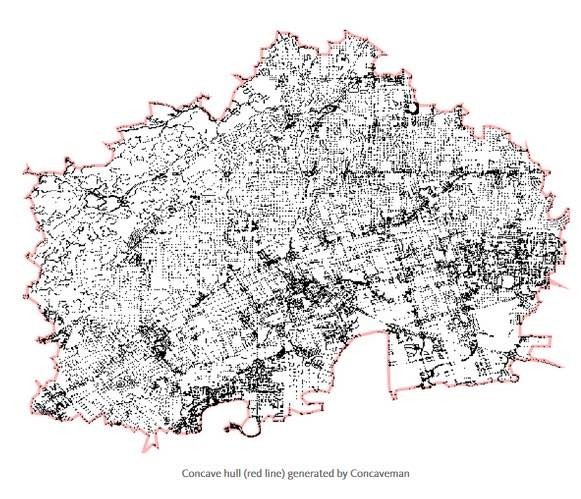
该算法以凸包(https://github.com/mikolalysenko/monotone-convex-hull-2d)开始,然后通过将它们连接到最接近的点的之一来向内弯曲它的每一段:
深入阅读:A New Concave Hull Algorithm and Concaveness Measure for n-dimensional Datasets, 2012(http://www.iis.sinica.edu.tw/page/jise/2012/201205_10.pdf)
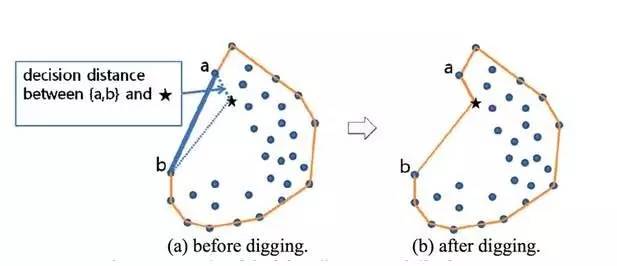
下面是一段引自论文的话:
在我们提出的凹面算法中,从边界边缘开始找到最近的内部点是一个耗时的过程,这些点是进一步挖掘目标点的候选点。开发更有效的方法是我们未来的研究课题。
我将数据点进行索引并执行“最近点到一个段”的查询,这使得该算法变得更快。
未来工作
在未来在这一些列的文章中,我会将kNN算法拓展到地理信息对象,并详细地讲解三个打包算法,即如何将数据点最好地排列到矩形框中。
最后感谢您耐心的阅读,如果您有任何意见或问题欢迎留言。欢迎试用我们的SDKs(https://www.mapbox.com/products/),如果您能够解决硬工程的挑战和地图的问题,欢迎查看我们的job openings(https://www.mapbox.com/jobs/)。
没有整理与归纳的知识,一文不值!高度概括与梳理的知识,才是自己真正的知识与技能。 永远不要让自己的自由、好奇、充满创造力的想法被现实的框架所束缚,让创造力自由成长吧! 多花时间,关心他(她)人,正如别人所关心你的。理想的腾飞与实现,没有别人的支持与帮助,是万万不能的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号