
数据库优化查询的方法以及大访问量到数据库时的优化
转自Tom-shushu原文 数据库优化查询的方法以及大访问量到数据库时的优化
一、数据库优化查询的方法
1.1使用索引
应尽量避免全表扫描,首先考虑在where 以及 order by ,group by 涉及的列上建立索引
1.2优化SQL语句
1>通过explain(查询优化神器)用来查看SQL语句的执行效果,可以帮助选择更好的索引和优化查询语句,写出更好的优化语句。通常我们可以对比较复杂的尤其是涉及到多表的SELECT语句,把关键字explain加到前面,查看执行计划,例如:
explain select * from news;
2>任何地方都不要使用select * from ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
3>不在索引列做运算或者使用函数。
4>查询尽可能使用limit 减少返回的行数,减少数据传输时间和带宽浪费。
1.3 优化数据库对象
1>.优化表的数据库类型
使用procedure analyse()函数对表进行分析,该函数可以对表中列的数据类型提出优化建议。能小就用小。表数据类型第一个原则是:使用能正确的表示和储存数据的最短类型。这样可以减少对磁盘空间,内存,cpu缓存的使用。
使用方法:select * from 表名 procedure analyse();
2>.对表进行拆分
第一种:垂直拆分
把主键和一些列放在一个表中,然后把主键和另外的列放到另一个表中。如果一个表中某些列常用,而另外一些列不常用,则可以用垂直拆分。
第二种:水平拆分
根据一列或者多列数据的值把数据行放到第二个独立的表中
3>.使用中间表来提高查询速度
创建中间表,表结构和原表结构完全相同,转移要统计的数据到中间表,然后在中间表上进行统计,得出想要的结果。
1.4 硬件优化
1>CUP的优化
选择多核和主频高的CPU。
2>内存的优化
使用更大的内存。将尽量多的内存分配给MySQl做缓存
3>磁盘I/O的优化
RAID没有数据冗余,没有数据校验的磁盘陈列。实现RAID0至少需要两块以上的磁盘,它将两块以上的硬盘合并成一块,数据连续地分割在每一块盘上。
RAID1是将一个两块硬盘所构成RAID磁盘阵列,其容量仅等于一块硬盘的容量,因为另一块只是当作数据“镜像”。
使用RAID-0+1磁盘阵列,RAID 0+1 是RAID0 和RAID 1的组合形式。它在提供与RAID 1一样的数据安全保障时,也提供了与RAID 0近似的储存性能。
4>调整磁盘调度算法
选择合适的磁盘调度算法,可以减少磁盘的寻道时间。
1.5 MySQl自身的优化
对MySQl自身的优化主要是对其配置文件my.cnf中的各项参数进行优化调整。如指定MySQL查询缓冲区的大小,指定MySQl允许的最大连接进程数等。
1.6 应用优化
1>使用数据库连接池
2>使用查询缓存
它的作用是存储select查询的文本及其相应结果。如果随后收到一个相同的查询,服务器会从查询缓存中直接查询结果。查询缓存适用于的对象是更新不频繁的表,当表中数据更改后,查询缓存中相关条目就会被清空。
二、如果有一个特别大的访问量到数据库上,如何优化?
2.1 使用优化查询的方法(如上面)
2.2 主从复制,读写分离,负载均衡
目前,大部分主流关系型数据库都提供了主从复制的功能,通过配置两台(或者多台)数据库的主从关系,可以将一台数据库服务器的数据跟新到另一台服务器上。网站可以利用数据库的这一功能,实现数据库的读写分离,从而改善数据库的负载压力。一个系统的读操作远远多于写操作,因此写操作发向master(主库),读操作发向于slaves(从库)进行操作(简单的轮询算法来决定使用哪个slave)。
利用数据库的读写分离,Web服务器在写数据的时候,访问主数据库(master),主数据库通过主从复制机制将数据更新同步到从数据库(slave),这样当Web服务器读数据的时候,就可以通过从数据库获取到数据。这一方案使得在大量读操作的Web应用可以轻松的读取数据,二主数据库也只会承受少量的写入操作,还可以实现数据的热备份,可谓是一举两得的方案。
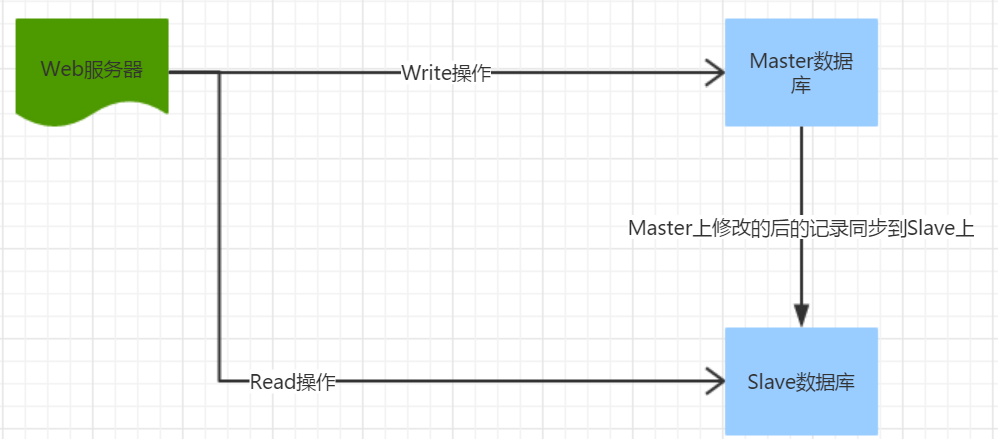
1>主从复制原理:
1,影响MySQL-A数据库的操作,在数据库执行后,都会写入本地的日志系统A中。假设,实时的将变化了的日志系统中的数据库事件操作,通过网络发给MYSQL-B。
MYSQL-B收到后,写入本地日志系统B ,然后一条条的将数据库事件在数据库中完成。那么,MYSQL A的变化, MYSQL-B也会变化,这样就是所谓的MYSQL的复制。
在上面的模型中, MYSQL-A就是主服务器,即master , MYSQL-B就是从服务器,即slave。
日志系统A ,其实它是MYSQL的日志类型中的二进制日志,也就是专用来保存修改数据库表的所有动作,即bin log。 [注意 MYSQL会在执行语句之后,释放锁之前,写入二进制日志,确保事务安全]
日志系统B,并不是二进制日志,由于它是从MYSQL-A的二进制日志复制过来的,并不是自己的数据库变化产生的,有点接力的感觉,称为中继日志,即relay log。
可以发现,通过上面的机制,可以保证MYSQL-A和MYSQL-B的数据库数据一致,但是时间上肯定有延迟,即MYSQL-B的数据是滞后的。
2,简化版:
mysql主(称master)从(称slave)复制的原理:
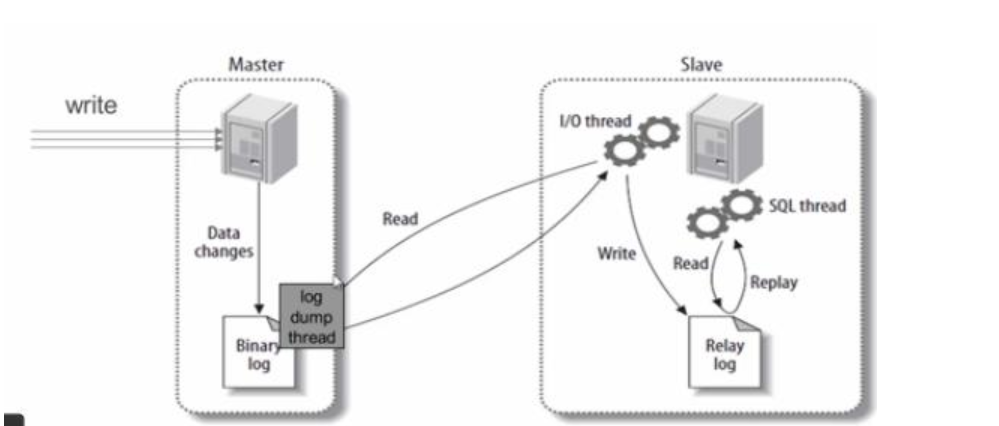
(1).master将数据改变记录到二进制8志(binary log)中,也即是配置文件log-bin指定的文件(这些记录叫做二进制日志事件,binary log events)
PS:从图中可以看出,Slave服务器中有一个l/O线程(I/O
Thread)在不停地监听Master的二进制日志(Binary
Log)是否有更新;如果没有它会睡眠等待Master产生新的日志事件;如果有新的日志事件(Log
Events);则会将其拷贝至Slave服务器中的中继日志(RelayLoal)。
(2).slave将master的二进制日志事件(binary log events)拷贝到它的中继日志(relay log)。
(3).slave重做中继日志中的事件,将Master上的改变反映到它自己的数据库中。所以两端的数据是完全-样的。
PS:从图中可以看出,Slave
服务器中有一个SQL线程(SQL
Thread)从中维日志读取事件,并重做其中的事件,从而更新Slave的数据,使其与Master中的数据致。只要该线程与10线程保持一致,
中继日志通常会位于OS的缓存中,所以中继日志的开销很小,附简要原理图:
2>主从复制的几种方式:
1.同步复制
主服务器在将更新的数据写入它的二进制日志(Bin log)文件中后,必须等待验证所有的从服务器的更新数据是否已经复制到其中,之后才可以自由处理其他进入的事务处理请求。
2.异步复制
主服务器在将更新的数据写入它的二进制日志(Bin log)文件中后,无需等待验证更新数据是否已经复制到从服务器中,就可以自由处理其他进入的事务处理请求。
3.半同步复制
主服务器在将更新的数据写入它的二进制日志文件中后,只需要等待验证其中一台服务器的更新数据是否已经复制到其中,就可以自由处理其他进入的事务处理请求,其他从服务器不用管。
2.3 数据库分表,分区,分库
1>分表见上面描述
2>分区:
就是把一张表的数据分成多个区块,这些区块可以在一个磁盘上,也可以在不同的磁盘上,分区后,表面上还是一张表,但数据散列在多个位置,这样一来,多块硬盘同时处理不同的请求,从而提高磁盘I/O读写性能,实现比较简单,包括水平分区和垂直分区。
3>分库是根据业务不同把相关的表切分到不同的数据库中,比如web ,bbs ,blog等库。
没有整理与归纳的知识,一文不值!高度概括与梳理的知识,才是自己真正的知识与技能。 永远不要让自己的自由、好奇、充满创造力的想法被现实的框架所束缚,让创造力自由成长吧! 多花时间,关心他(她)人,正如别人所关心你的。理想的腾飞与实现,没有别人的支持与帮助,是万万不能的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号