

哈希表
1.引入
-
哈希表又称散列表,一种以「key-value」形式存储数据的数据结构。
-
所谓以「key-value」形式存储数据,是指任意的键值 key 都唯一对应到内存中的某个位置。只需要输入查找的键值,就可以快速地找到其对应的 value。
-
可以把哈希表理解为一种高级的数组,这种数组的下标可以是很大的整数,浮点数,字符串甚至结构体。

如果在元素存储位置与其关键码之间建立一个确定的对应函数关系Hash(), 使得每个关键码与唯一的存储位置相对应:
Address = Hash(key)
在插入时依此函数计算存储位置并按此位置存放;
在搜索时对元素的关键码进行同样的计算,把求得的函数值当做元素存储位置,然后按此位置搜索。这就是散列方法。
在散列方法中所用转换函数叫做散列函数 (又叫哈希函数) 。按此方法构造出来的表叫做散列表 (又叫哈希表)。
哈希函数是一个压缩映象函数,关键码集合比哈希表地址集合大得多。
因此有可能经过哈希函数的计算,把不同的关键码映射到同一个散列地址上,这就产生了冲突。
示例:有一组表项,其关键码分别是 12361, 07251, 03309, 30976 ,采用的哈希函数是 hash(x) = x % 73 + 13420。
则有 hash(12361) = hash(07251) = hash(03309) = hash(30976) = 13444。
就是说,对不同的关键码,通过哈希函数的计算,得到了同一散列地址。
综上,对于散列方法, 需要讨论以下两个问题:
- 对于给定的一个关键码集合,选择一个计算简单且地址分布比较均匀的哈希函数,避免或尽量减少冲突;
- 设计解决冲突的方案。
2.*哈希函数
构造哈希函数(散列函数)时的几点要求:
- 哈希函数应是简单的,能在较短的时间内计算出结果。
- 哈希函数的定义域必须包括需要存储的全部关键码,如果哈希表允许有 m 个地址时,其值域必须在 0 到 m-1 之间。
- 哈希函数计算出来的地址应能均匀分布在整个地址空间中 : 若 key 是从关键码集合中随机抽取的一个关键码, 哈希函数应能以同等概率取0 到 m-1 中的每一个值。
2.1 直接定址法
此类函数取关键码的某个线性函数值作为散列地址:
Hash(key) = a * key + b (a, b为常数)
这类哈希函数是一对一的映射,一般不会产生冲突。但它要求散列地址空间的大小与关键码集合的大小相同。
示例:有一组关键码如下:{ 942148, 941269, 940527, 941630, 941805, 941558, 942047, 940001 }。
哈希函数为 :Hash(key) = key-940000
Hash (942148) = 2148 Hash (941269) = 1269 Hash (940527) = 527 Hash (941630) = 1630 Hash (941805) = 1805
Hash (941558) = 1558 Hash (942047) = 2047 Hash (940001) = 1
2.2 数字分析法
设有 n 个 d 位数, 每一位可能有 r 种不同的符号。这 r 种不同符号在各位上出现的频率不一定相同。根据哈希表的大小, 选取其中各种符号分布均匀的若干位作为散列地址。
计算各位数字中符号分布均匀度λ(k)的公式:
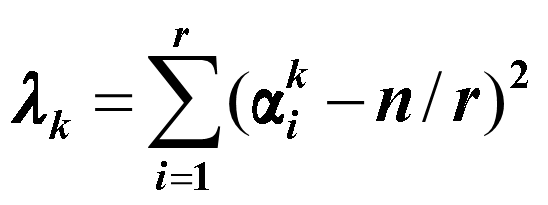
其中,α(i,k) 表示第 i 个符号在第 k 位上出现的次数,n/r 表示该符号在 n 个数中出现的期望值。
计算出的 λ(k) 值越小,表明在该位 (第 k 位) 各种符号分布得越均匀。
示例:
9 4 2 1 4 8 ①位, λ(1) = 57.60; ②位, λ(2) = 57.60 ;
9 4 1 2 6 9 ③位, λ(3) = 17.60; ④位, λ(4) = 5.60 ;
9 4 0 5 2 7 ⑤位, λ(5) = 5.60; ⑥位, λ(6) = 5.60 ;
9 4 1 6 3 0
9 4 1 8 0 5
9 4 1 5 5 8
9 4 2 0 4 7
9 4 0 0 0 1
① ② ③ ④ ⑤ ⑥
若哈希表地址范围有 3 位数字, 取各关键码的 ④⑤⑥ 位做为记录的散列地址。
数字分析法仅适用于事先明确知道表中所有关键码每一位数值的分布情况,它完全依赖于关键码集合。如果换一个关键码集合,选择哪几位要重新决定。
2.3 除留余数法(最常用)
设哈希表中允许地址数为m,取一个不大于 m,但最接近于或等于 m 的质数 p 作为除数,用以下函数把关键码转换成散列地址:
hash (key) = key % p (p <= m)
其中,“%”是整数除法取余的运算,要求这时的质数 p 不是接近 2 的幂的数。
示例: 有一个关键码 key = 962148,哈希表大小 m = 25,即 HT[25]。取质数 p = 23。哈希函数 hash(key) = key % p。
则散列地址为 hash(962148) = 962148 % 23 = 12。
可按计算出的地址存放记录。注意, 使用哈希函数计算出的地址范围是 0 到 22,而 23、24 这几个地址实际上不能用哈希函数计算出来,只能在处理冲突时达到这些地址。
2.4 平方取中法
它首先计算构成关键码的标识符的内码的平方, 然后按照散列表的大小取中间的若干位作为散列地址。
- 设标识符可以用一个计算机字长的内码表示。因为内码平方数的中间几位一般是由标识符所有字符决定, 所以对不同的标识符计算出的散列地址大多不相同。
- 在平方取中法中, 一般取散列地址为8的某次幂。例如, 若散列地址总数取为 m = 8^r,则对内码的平方数取中间的 r 位。
示例:
| 标识符 | 内码 | 内码平方 | 散列地址 |
|---|---|---|---|
| A | 01 | 01 | 001 |
| A1 | 0134 | 20420 | 042 |
| A9 | 0144 | 23420 | 342 |
| B | 02 | 04 | 004 |
| DMAX | 04150130 | 21526443617100 | 443 |
| DMAX1 | 0415013034 | 5264473522151420 | 352 |
| AMAX | 01150130 | 135423617100 | 236 |
| AMAX1 | 0115013034 | 3454246522151420 | 652 |
标识符的八进制内码表示及其平方值和散列地址
2.5 折叠法
此方法把关键码自左到右分成位数相等的几部分, 每一部分的位数应与散列表地址位数相同, 只有最后一部分的位数可以短一些。
把这些部分的数据叠加起来, 就可以得到具有该关键码的记录的散列地址。
有两种叠加方法:
- 移位法:把各部分最后一位对齐相加;
- 分界法:各部分不折断,沿各部分的分界来回折叠, 然后对齐相加。
示例: 设给定的关键码为 key = 23938587841, 若存储空间限定 3 位, 则划分结果为每段 3 位。
上述关键码可划分为 4 段: 239 385 878 41
叠加,然后把和超出地址位数的最高位删去,仅保留最低的3位,做为可用的散列地址。
一般当关键码的位数很多,而且关键码每一位上数字的分布大致比较均匀时,可用这种方法得到散列地址。
假设地址空间为HT[400],利用以上函数计算,取其中3位,取值范围在0~999,可能超出地址空间范围,为此必须将0~999压缩到0~399。可将计算出的地址乘以一个压缩因子0.4,把计算出的地址压缩到允许范围。
- 折叠法的优点是可以应对关键字长度不一致的情况,同时可以增加哈希值的随机性。
- 然而,该方法也可能存在一些问题,如部分折叠方式可能导致哈希冲突,或者在拆分关键字时可能需要额外处理边界情况。
3.冲突处理
3.1 闭散列方法
因为任一种散列函数也不能避免产生冲突,因此选择好的解决冲突的方法十分重要。
闭散列方法把所有记录直接存储在散列表中,如果发生冲突则根据某种方式继续进行探查。
线性探查法 (Linear Probing)
- 如果在 d 处发生冲突,就依次检查 d + 1,d + 2……
示例:假设给出一组表项,它们的关键码为 Burke, Ekers, Broad, Blum, Attlee, Alton, Hecht, Ederly。
采用的散列函数是:取其第一个字母在字母表中的位置。 Hash (x) = ord (x) - ord (‘A’) ,ord ( ) 是求字符内码的函数
可得 Hash (Burke) = 1 Hash (Ekers) = 4 Hash (Broad) = 1 Hash (Blum) = 1
Hash (Attlee) = 0 Hash (Hecht) = 7 Hash (Alton) = 0 Hash (Ederly) = 4
设散列表 HT[26], m = 26。采用线性探查法处理冲突, 则散列结果如图所示。
| 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Attlee | Burke | Broad | Blum | Ekers |
| 5 | 6 | 7 | 8 | 9 |
| Alton | Ederly | Hecht |
- 需要搜索或加入一个表项时, 使用散列函数计算关键字在表中的位置: H0 = hash ( key )
- 一旦发生冲突,在表中顺次向后寻找下一个位置 Hi : Hi = ( H(i-1) +1 ) % m, i =1, 2, …, m-1
- 即用以下的线性探查序列在表中寻找下一 个位置: H0 + 1, H0 + 2, …, m-1, 0, 1, 2, …, H(0-1)
- 亦可写成如下的通项公式: Hi = ( H0 + i ) % m, i =1, 2, …, m-1
线性探查法实现:
const int N = 360007; // N 是最大可以存储的元素数量
class Hash
{
int keys[N];
int values[N];
public:
Hash() { memset(values, 0, sizeof(values)); /*用于将一块内存区域的内容设置为指定的值*/}
int& operator[](int n)
{
// 返回一个指向对应 Hash[Key] 的引用
// value 等于 0 视为空
int idx = (n % N + N) % N, cnt = 1;
// 这里使用 (n % N + N) % N 而非 n % N 的原因是 C++ 中的 % 运算无法将负数转为正数
while (keys[idx] != n && values[idx] != 0)
{
idx = (idx + cnt) % N; cnt += 1;
}
keys[idx] = n;
return values[idx];
}
};
3.2 开散列方法(链地址法)
- 若设散列表地址空间的位置从 0~m-1, 则关键码集合中的所有关键码被划分为 m 个子集,具有相同地址的关键码归于同一子集。
- 每一个子集称为一个桶。通常各个桶中的表项通过一个单链表链接起来。
- 查询的时候需要把对应位置的链表整个扫一遍,对其中的每个数据比较其键值与查询的键值是否一致。
链地址法实现:
const int M = 10;
class HashTable
{
struct Node
{
Node* next;
int value;
int key;
Node(Node* n = nullptr,int v = 0,int k = 0)
:next(n), value(v),key(k){}
};
Node* head[M];
int f(int key) { return (key % M + M) % M; }
public:
HashTable() { for (auto& h : head) { h = nullptr; } }
int get(int key)
{
for (Node* p = head[f(key)]; p; p = p->next)
{
if (p->key = key)return p->value;
}
return -1;
}
int add(int key, int value)
{
if (get(key) != -1) return -1;
Node* buf = new Node(nullptr, value,key);
Node* p = nullptr;
for (p = head[f(key)]; p && p->next; p = p->next){}
if (p) { p->next = buf; }
else { head[f(key)] = buf; }
return value;
}
};
练习
给定 n 个数,要求把其中重复的去掉,只保留第一次出现的数。
输入格式:
本题有多组数据。
第一行一个整数 T,表示数据组数。
对于每组数据:
第一行一个整数 n。
第二行 n 个数,表示给定的数。
输出格式:
对于每组数据,输出一行,为去重后剩下的数,两个数之间用一个空格隔开。
样例:
输入
2
11
1 2 18 3 3 19 2 3 6 5 4
6
1 2 3 4 5 6
输出
1 2 18 3 19 6 5 4
1 2 3 4 5 6

 浙公网安备 33010602011771号
浙公网安备 33010602011771号