memcached 学习笔记
memcached是高性能的分布式内存缓存服务器。一般的使用目的是,通过缓存数据库查询结果,减少数据库访问次数,以提高动态应用的速度、提高可扩展性。
Memcached基于一个存储键/值对的hashmap,当表满了以后,接下来新增的资料会以LRU机制替换掉。其守护进程是用C写的,但是客户端可以用任何语言来编写,并通过memcached协议与守护进程通信。
一、分布式
分布式的一个最重要的内容是要保证同一个key每次都必须命中同一个服务器。下面简单介绍两种分布方式:简单hash分布和一致性hash分布。
1、简单hash分布
例如对于每次访问,可以按如下算法计算其哈希值:
h = Hash(key) % N
其中Hash是一个从字符串到正整数的哈希映射函数,N是服务器数量。这样,如果我们有三台服务器,将它们分别编号为0、1、2,那么就可以根据上式和key计算出服务器编号h,然后去访问。
2、一致性hash分布
上面所说的简单hash算法有一个致命的缺点,就是扩展性和容错性。简单来说,所谓容错性是指当系统中某一个或几个服务器变得不可用时,整个系统是否可以正确高效运行;而扩展性是指当加入或减少服务器后,整个系统是否可以正确高效运行。
现假设有一台服务器宕机了,那么为了填补空缺,要将宕机的服务器从编号列表中移除,后面的服务器按顺序前移一位并将其编号值减一,此时每个key就要按h = Hash(key) % (N-1)重新计算;同样,如果新增了一台服务器,虽然原有服务器编号不用改变,但是要按h = Hash(key) % (N+1)重新计算哈希值。因此系统中一旦有服务器变更,大量的key会被重定位到不同的服务器从而造成大量的缓存不命中。而这种情况在分布式系统中是非常糟糕的。
一个设计良好的分布式哈希方案应该具有良好的单调性,即服务节点的增减不会造成大量哈希重定位。一致性哈希算法就是这样一种哈希方案。
2.1 算法简述
简单来说,一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0 - 2^(32-1)(即哈希值是一个32位无符号整形),整个哈希空间环如下:
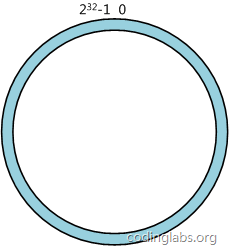
整个空间按顺时针方向组织。0和2^(32-1)在零点中方向重合。
下一步将各个服务器使用H进行一个哈希,具体可以选择服务器的ip或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置,这里假设将上文中三台服务器使用ip地址哈希后在环空间的位置如下:
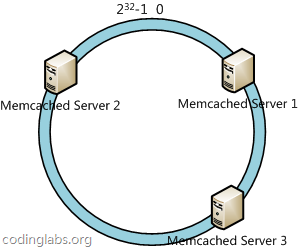
接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数H计算出哈希值h,根据h确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。
例如我们有A、B、C、D四个数据对象,经过哈希计算后,在环空间上的位置如下:
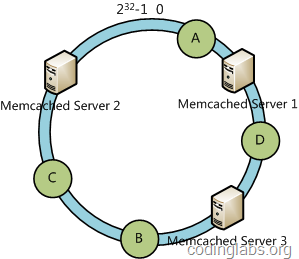
根据一致性哈希算法,数据A会被定为到Server 1上,D被定为到Server 3上,而B、C分别被定为到Server 2上。
2.2 容错性和扩展性分析
下面分析一致性哈希算法的容错性和可扩展性。现假设Server 3宕机了:
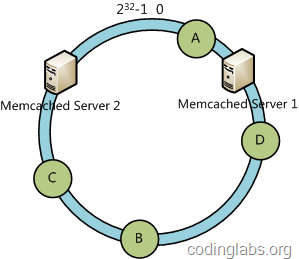
可以看到此时A、C、B不会受到影响,只有D节点被重定位到Server 2。一般的,在一致性哈希算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即顺着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。
下面考虑另外一种情况,如果我们在系统中增加一台服务器Memcached Server 4:
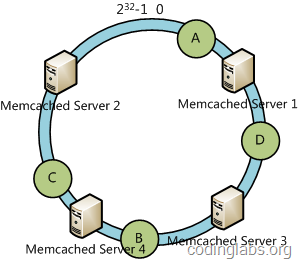
此时A、D、C不受影响,只有B需要重定位到新的Server 4。一般的,在一致性哈希算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即顺着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。
综上所述,一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
2.3 虚拟节点
一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题。例如我们的系统中有两台服务器,其环分布如下:
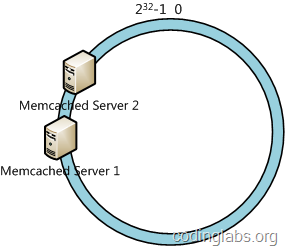
此时必然造成大量数据集中到Server 1上,而只有极少量会定位到Server 2上。为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器ip或主机名的后面增加编号来实现。例如上面的情况,我们决定为每台服务器计算三个虚拟节点,于是可以分别计算“Memcached Server 1#1”、“Memcached Server 1#2”、“Memcached Server 1#3”、“Memcached Server 2#1”、“Memcached Server 2#2”、“Memcached Server 2#3”的哈希值,于是形成六个虚拟节点:
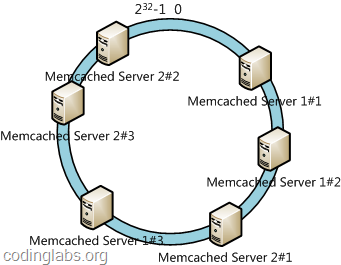
同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到“Memcached Server 1#1”、“Memcached Server 1#2”、“Memcached Server 1#3”三个虚拟节点的数据均定位到Server 1上。这样就解决了服务节点少时数据倾斜的问题。在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。
ps:上述一致性hash算法转载至:http://blog.codinglabs.org/articles/consistent-hashing.html
二、LRU机制
1、概述
三、memcached通信协议
这里以一个get和set的操作来简单地描述一下内部过程。
首先是set操作,一般我们都是使用字符串来作为存储key(当然,你也可以选择用其他的),客户端根据key来命中服务器并获取可用连接后,就开始对数据进行处理了,包括检查字符编码、数据采用字符形式还是对象序列化形式、是否进行压缩等。对数据格式处理完毕后,就要把数据发送到服务器端,它这里采用协议格式非常简单,仅仅是空格+换行而已。首先第一行包含数据的信息,类似于http的头信息,包括操作名(set/add/update/delete/get……)、key、flags(采用二进制数字来做标记,标记的包括数据采用字符形式还是对象序列化形式、是否压缩)、过期时间、数据长度。第二行就是数据内容的字节数组输出。第三行输出一个换行符/r/n。最后一步,等待服务器返回存储成功或者失败的信息。
get操作基本上就是set操作的反操作了,直接发送get命令(仅仅包含key信息),对返回的数据进行逆向处理。
1 String cmd = String.format( "%s %s %d %d %d\r\n", cmdname, key, flags, (expiry.getTime() / 1000), val.length ); 2 sock.write( cmd.getBytes() ); 3 sock.write( val ); 4 sock.write( "\r\n".getBytes() ); 5 sock.flush();

四、连接池管理
memcached客服端向每个服务器创建N个初始连接,初始连接数默认10个。然后启动SocketPool的一个管理线程协调各个socket连接,对于每个服务器:
1、将过于空闲的连接关掉
2、如果可用连接a比设置的最少连接数b还少,那么创建b-a个连接
3、如果可用连接a比设置的最多连接数b还多,那么关闭a-b个连接
4、将耗时太长并还在工作的连接关掉
5、将已经标识为死亡的连接关掉

 浙公网安备 33010602011771号
浙公网安备 33010602011771号