机器学习-逻辑回归算法
1. 概述
- 逻辑回归算法是一种很常见的用来解决二元分类问题的回归方法,它主要是通过寻找最优参数来正确地分类原始数据
2.基本原理
1)逻辑回归(Logistic Regression,简称LR)
-
又称对数几率回归 ,简称对率回归,其实是一个很有误导性的概念,虽然它的名字中带有"回归"两个字,但是它最擅长处理的却是分类问题
-
叫回归的原因:基于线性回归的原理

2)广义线性模型(generalized linear model)
-
线性回归在实际应用中引入了诸多变化形式,而这些变化形式可统一规整为如下形式∶
\[y = g^{-1}(w^Tx+b) \]-
函数被称为 联系函数(link function)
-
g(*) 为可微函数,使用对数几率函数(Logistic function)作为 g-1(*) ,对数几率函数表示形式如下:
\[y=g(z)=\frac{1}{1+e^{-z}} \]- 对数几率函数是一个Sigmoid函数(将变量映射到0,1之间,不包含0,1)
- \(g'(z) = g(z) (1-g(z))\)
-
带入对数几率函数,得到逻辑回归表达式 :
\[y =\frac{1}{1+e^{-(w^Tx+b)}} \] -
整理得
\[ln\frac{y}{1-y}=w^Tx+b \]- 由于 y 和 1-y 的和为 1,因此可将 y 和 1-y 视为一对正反例的可能性,即 y 视作样本 x 为正例的可能性,则 1-y 为 x 为反例的可能性
- 二者比例 \(\frac{y}{1-y}\) 称为”几率“,反映了样本 x 为正例的相对可能性
- 对几率取对数则得到"对数几率"(log odds,亦称logit): \(ln\frac{y}{1-y}\)
-
-
上式实际上是在用线性回归模型的预测结果取逼近真实标记的对数几率。因此,其对应的模型被称为"对数几率回归"(logistic regression)
- 虽然其名字包含回归二字,但本质上是一种分类学习方法
- 它是直接对分类可能性进行建模,因此它不仅预测出"类别",而且得到的是近似概率预测,这对许多需要利用概率辅助决策的任务很有用
- 对率函数 是任意阶可导的凸函数,有很多的数学性质,现有的很多数值优化算法都可直接用于求取最优解。(比如梯度下降算法)
3. 梯度下降(Gradient Descent)
1)作用
- 求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常用的方法之一
2)梯度
-
在微积分里面,对多元函数的参数求 偏导数,把求得的各个参数的偏导数以向量的形式写出来,就是梯度
- 例如$f(x,y) $,分别对 \(x,y\) 求偏导数,求得的梯度下降向量就是\((\varphi f/ \varphi x,\varphi f/ \varphi y)^T\),简称\[gradf(x,f)或者\bigtriangledown f \]
- 例如$f(x,y) $,分别对 \(x,y\) 求偏导数,求得的梯度下降向量就是\((\varphi f/ \varphi x,\varphi f/ \varphi y)^T\),简称
-
意义
- 几何意义上讲,就是函数变化增加最快的地方
- 具体来说,对于函数 $f(x,y) $在点 \((x_0,y_0)\),沿着梯度向量的方向就是 \((\varphi f/ \varphi x_0,\varphi f/ \varphi y_0)^T\) 的 方向是 $f(x,y) $ 增加最快的方向
- 沿着梯度向量的方向,更加容易找到函数的最大值
- 几何意义上讲,就是函数变化增加最快的地方
3)梯度下降和梯度上升
在最小化损失函数时,可以通过梯度下降法来一步步的迭代求解,得到最小化的损失函数,和模型参数值
- 如果我们需要求解损失函数的最大值,这时就需要用梯度上升法来迭代了
- 梯度下降和梯度上升法是可以互相转化的
- 比如需要求解损失函数 $f(\theta) $ 的最小值,这时我们需要用梯度下降来迭代求解。但是实际上,我们可以反过来求解损失函数 $-f(\theta) $ 的最大值,这时梯度上升法就派上用场了
4)梯度下降算法详解
-
梯度下降不一定能够找到全局的最优解,有可能是一个局部最优解。当然,如果损失函数是凸函数,梯度下降法得到的解就一定是全局最优解
-
梯度下降的相关概念
-
步长(Learning rate):步长决定了在梯度下降迭代的过程中,每一步沿梯度负方向前进的长度
-
假设函数(hypothesis function)∶在监督学习 ,为了拟合输入样本,而使用的假设函数记为 \(\hat{y}\) ,比如对于单个特征的 m 个样本,可以采用拟合函数为∶ \(\hat{y}=w_0+w_1z\) 。
-
损失函数(loss function)∶为了评估模型拟合的好坏,通常用损失函数来度量拟合的程度。
-
损失函数极小化,意味着拟合程度最好,对应的模型的参数即为最优参数。
-
+在线性回归中,损失函数通常为样本输出和假设函数的差的平方和。比如对于m个样本,采用线性回归,损失函数为∶
\[J(w_0,w_1)=\sum_{i=1}^{m}(\hat{y}-y_i)^2 \]
-
-
-
梯度下降的算法用矩阵法来表示,更加简洁,实现逻辑更加的一目了然
-
先决条件:需要确认优化模型的假设函数和损失函数。
-
对于线性回归,假设函数 \(\hat{y} = w_0+w_1x+...w_nx_n\) 矩阵表达方式为
\[\hat{y} = Xw \]-
假设函数为 m x 1 的向量,w 是 (n+1)x 1 的向量,里面有 n 个模型参数
-
X 为 m x (n+1) 维的矩阵
-
m 代表样本个数,n+1 代表样本的特征数
-
损失函数的表达式为,其中 Y 是样本的输出向量,维度为 m x 1
\[J(w)=\frac{1}{2m}(Xw-Y)^T(Xw-Y) \]
-
-
-
算法相关参数初始化
- w 向量可以初始化为默认值,或者调优后的值。
- 算法终止距离 c,步长 α 初始化为1,在调优时再进行优化
-
算法过程
-
i)确定当前位置的损失函数的梯度,对于 w 向量,其梯度表达式如下∶
\[\frac{\varphi }{\varphi w}J(w) \] -
ii)用步长乘以损失函数的梯度,得到当前位置下降的距离,即:
\[\alpha \frac{\varphi }{\varphi w}J(w) \] -
iii)确定 w 向量里面的每个值,梯度下降的距离都小于 c,如果小于 c 则算法终止,当前 w 向量即为最终结果。否则进入步骤 V)
-
V)更新 w 向量,其更新表达式如下。更新完毕后继续转入后续步骤 i)
-
损失函数对于 w 向量的偏导数计算如下:
\[\frac{\varphi }{\varphi w}J(w)=\frac{1}{m}X^T(Xw-Y) \] -
w 向量更新表达式如下:
\[w = w - \alpha X^T(Xw-Y)/m \]- 用到矩阵的链式求导法则,和两个矩阵求导的公式\[\frac{\varphi }{\varphi X}(XX^T)=2X \\ \frac{\varphi }{\varphi w}(Xw)=X^T \]
- 用到矩阵的链式求导法则,和两个矩阵求导的公式
-
-
-
5)梯度下降算法调优
-
算法的步长选择。在前面的算法描述中,提到取步长为1,但是实际上取值取决于数据样本,可以多取一些值,从大到小,分别运行算法,看看迭代效果,如果损失函数在变小,说明取值有效,否
则要增大步长。 -
算法参数的初始值选择。初始值不同,获得的最小值也有可能不同,因此梯度下降求得的只是局部最小值;当然如果损失函数是凸函数则一定是最优解。由于有局部最优解的风险,需要多次用不同的初始值运行算法,观测损失函数的最小值,选择损失函数最小化的初始值。
-
标准化。由于样本不同特征的取值范围不一样,可能导致迭代很慢,为了减少特征取值的影响,可以对特征数据标准化,也就是对于每个特征 z,求出它的期望和标准差 std(x),然后转化为∶
\[\frac{x-\bar{x}}{std(x)} \]- 这样特征的新期望为0,新方差为1,且无量纲,收敛速度可以大大加快。
4. 逻辑回归的sklearn实现
1)参数
class sklearn.linear_model.LogisticRegression (
penalty=’l2’, #L2正则化--岭回归,L1正则化--laso,默认L2
dual=False,
tol=0.0001,
C=1.0, #C越小,惩罚力度越大,反之亦然
fifit_intercept=True,
intercept_scaling=1,
class_weight=None,
random_state=None,
solver=’warn’, #梯度下降的方式
max_iter=100*, #梯度下降的迭代次数
multi_class=’warn’,
verbose=0,
warm_start=False,
n_jobs=None
)
2)正则化参数:penalty
- penalty参数可选择的值为"1"和"2",分别对应L1的正则化和L2的正则化,默认L2
- L2正则化是岭回归,L1正则化是Lasso回归
- 如果选择L2正则化发现是过拟合,即预测效果差的时候,就可以考虑L1正则化
- 如果模型的特征非常多,我们希望一些不重要的特征系数归零,从而让模型系数稀疏化,防止过拟合,可以使用L1正则化
- 模型的特征越多,模型复杂度越高,更容易将噪声学习到模型中,导致过拟合
- 模型特征越少(不能太少),泛化能力越强
- penalty参数的选择会影响我们损失函数优化算法的选择。即参数 solver 的选择
- 如果是L2正则化,那么4种可选的算法 ('newton-cg','Ibfgs','liblinear','sag'} 都可以选择
- 如果penalty是L1正则化的话,就只能选择 ‘liblinear'了
- 因为L1正则化的损失函数不是连续可导的,而 {‘newton-cg’,'Ibfgs,'sag'} 这三种优化算法时都需要损失函数的一阶或者二阶连续导数。而 ’liblinear' 并没有这个依赖
3)算法优化参数:solver
solver参数决定了我们对逻辑回归损失函数的优化方法,有4种算法可以选择,分别是∶
- liblinear∶使用了开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数。
- 逻辑回归有二元逻辑回归和多元逻辑回归。对于多元逻辑回归常见的有one-vs-rest(OvR)和many-vs-many(MvM)两种,而MvM一般比OvR分类相对准确一些。
- liblinear只支持OVR,不支持MVM,这样如果我们需要相对精确的多元逻辑回归时就不的先择liblinear了。也意味着如果我们需要相对精确的多元逻辑回归不能位用L1正则化
- Ibfgs∶拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
- newton-cg∶也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
- sag∶即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅用一部分的样本来计算梯度,适合于样本数据多的时候。
4)选最优参数sklearn实现
-
学习曲线法
-
导入相应的包
import numpy as np import pandas as pd from sklearn.datasets import load_breast_cancer import matplotlib.pyplot as plt -
提取数据
data = load_breast_cancer()#sklearn数据包 X = data.data Y = data.target -
建立模型
from sklearn.linear_model import LogisticRegression as LR from sklearn.model_selection import train_test_split lr1 =LR(penalty='l1', C = 0.5,solver='liblinear',max_iter=1000).fit(X,Y) lr2 =LR(penalty='l2', C = 0.5,solver='liblinear',max_iter=1000).fit(X,Y) -
绘制学习曲线
#切分数据集 Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,Y,test_size = 0.3,random_state = 420) # 设置 C 在 L1 和 L2下训练集和测试集的表现 #训练集的分数 l1train = [] l2train = [] #测试集的分数 l1test = [] l2test = [] for i in np.linspace(0.05,1,19): #实例化模型并且训练 lrl1 =LR(penalty='l1', C = i,solver='liblinear',max_iter=1000).fit(Xtrain,Ytrain) lrl2 =LR(penalty='l2', C = i,solver='liblinear',max_iter=1000).fit(Xtrain,Ytrain) #训练集的分数 l1train.append(lrl1.score(Xtrain,Ytrain)) l2train.append(lrl2.score(Xtrain,Ytrain)) #测试集的分数 l1test.append(lrl1.score(Xtest,Ytest)) l2test.append(lrl2.score(Xtest,Ytest)) # 画图 graph = [l1train,l2train,l1test,l2test] color = ["green","black","lightgreen","gray"] label = ["L1train","L2train","L1test","L2test"] plt.figure(figsize=(6,6)) for i in range(len(graph)): plt.plot(np.linspace(0.05,1,19),graph[i],color[i],label=label[i]) plt.legend(loc=4) #图例的位置在哪⾥? -> 4表示,右下⻆ plt.show() # 根据图选择 C=0.9的 L2 正则表达
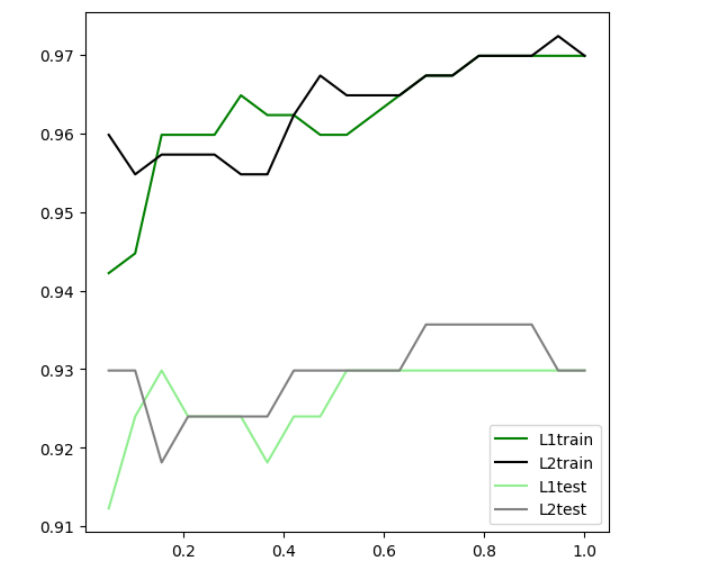
-
绘制最大次数迭代曲线
# 确定 C=0.9 关于最大迭代次数绘制曲线 L2train = [] L2test = [] for i in range(1,201,10): #实例化模型并且训练 Lrl2 =LR(penalty='l2', C = 0.9,solver='liblinear',max_iter= i ).fit(Xtrain,Ytrain) #训练集的分数 L2train.append(Lrl2.score(Xtrain,Ytrain)) #测试集的分数 L2test.append(Lrl2.score(Xtest,Ytest)) #绘图 plt.plot(range(1,201,10),L2train,label= 'L2train') plt.plot(range(1,201,10),L2test,label= 'L2test') plt.legend(loc=4) #图例的位置在哪⾥? -> 4表示,右下⻆ plt.show() # 根据图,确定最大迭代次数在25次后就收敛了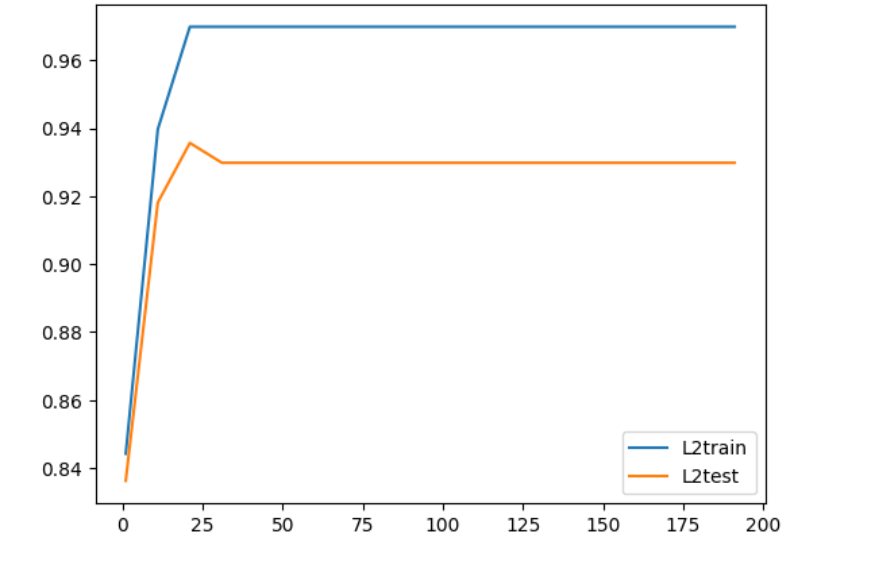
-
-
网格参数法
-
sklearn
from sklearn.model_selection import GridSearchCV #网格搜索 from sklearn.preprocessing import StandardScaler #标准化 #标准化数据 data = pd.DataFrame(X,columns=load_breast_cancer().feature_names) data['label'] = Y #切分数据集 Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,Y,test_size = 0.3,random_state = 420) #对训练集和测试集做标准化——去量纲 std = StandardScaler().fit(Xtrain) Xtrain_ = std.transform(Xtrain) Xtest_ = std.transform(Xtest) #在 L2 范式下,判断 C 和 solver 的最优值 p = { 'C':list(np.linspace(0.05,1,19)), 'solver':['liblinear','newton-cg','Ibfgs','sag'] } model = LR(penalty='l2',max_iter= 10000 ) GS = GridSearchCV(model,p,cv=5) GS.fit(Xtrain_,Ytrain) -
获取结果
GS.best_score_ # 得分 GS.best_params_ # 最优参数的值
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号