一个std::thread()线程创建失败问题分析过程
关键词:std::thread()、pthread_create()、mmap()、ENOMEM、EAGAIN、TASK_UNMAPPED_BASE、TASK_SIZE等等。
本文描述一个进程出现Resource temporarily unavailable,然后逐步定位到std::thread()创建失败。接着从内核开始分析,到libpthread.so,以及借助maps进行分析,最终发现mmap()虚拟地址耗尽。
通过修改内核的mmap区域解决问题。
1. 问题描述
在程序运行一段时间后,出现了"std::system_error what(): Resource temporarily unavailable"字样;然后进程异常退出。或者程序在进行coredump。
2. 问题分析
在程序进行coredump过程中,通过如下脚本定期查看相关信息。
检查进程下的所有线程的maps/status/stack/syscall。
#!/bin/sh function iterate_threads_info() { pids=`pidof $1` output_file="$1.info" echo -e "@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@\nRecord start: "$pids >> $output_file for pid in $pids do cat /proc/$pid/maps >> $output_file for tid in `ls /proc/$pid/task/` do echo -e "################################################################################" >> $output_file echo "Pid:" $pid "->" $tid >> $output_file echo "************************** status ********************************" >> $output_file cat /proc/$pid/task/$tid/status >> $output_file echo "************************** statck ********************************" >> $output_file cat /proc/$pid/task/$tid/stack >> $output_file echo "************************** syscall ********************************" >> $output_file cat /proc/$pid/task/$tid/syscall >> $output_file echo -e "\n\n" >> $output_file done echo -e "\n\n" >> $output_file done } while true do iterate_threads_info $1 sleep $2 done
通过线程的栈找到正在进行coredump的线程,确定是此线程导致的coredump。
然后查看此线程创建的线程只存在了3个线程,应该是4个线程。所以怀疑是创建线程错误。
创建线程部分为:
void xxx::proc(void* rx_task, int32_t task_id) { std::thread([this, rx_task, res_handle]() { ... }).detach(); }
然后增加try...catch():
void xxx::proc(void* rx_task, int32_t task_id) { try { std::thread([this, rx_task, res_handle]() { ... }).detach(); } catch(const std::system_error &e) { std::cout << thread_count << " : " << e.code() << " meaning " << e.what() << std::endl; } }
再次运行显示是std::thread()在创建线程的时候错误,错误码为EAGAIN。
3. 问题根源追溯
线程创建从上到下依次是:std::thread()->pthread_create()->clone()->do_fork()。
下面从底层开始分析,找到究竟是谁返回了EAGAIN。
3.1 内核fork()相关分析
首先想到的是内核中fork()的时候,产生了EAGAIN错误。
内核fork()系统调用函数调用关系为do_fork()->_do_fork()->copy_process(),这里主要关注哪里返回值为EAGAIN。
long _do_fork(unsigned long clone_flags, unsigned long stack_start, unsigned long stack_size, int __user *parent_tidptr, int __user *child_tidptr, unsigned long tls) { ... p = copy_process(clone_flags, stack_start, stack_size, child_tidptr, NULL, trace, tls, NUMA_NO_NODE); add_latent_entropy(); if (!IS_ERR(p)) { ... } else { nr = PTR_ERR(p); } return nr; } static __latent_entropy struct task_struct *copy_process( unsigned long clone_flags, unsigned long stack_start, unsigned long stack_size, int __user *child_tidptr, struct pid *pid, int trace, unsigned long tls, int node) { int retval; struct task_struct *p; ... retval = security_task_create(clone_flags); if (retval) goto fork_out; retval = -ENOMEM; p = dup_task_struct(current, node); if (!p) goto fork_out; ftrace_graph_init_task(p); rt_mutex_init_task(p); #ifdef CONFIG_PROVE_LOCKING DEBUG_LOCKS_WARN_ON(!p->hardirqs_enabled); DEBUG_LOCKS_WARN_ON(!p->softirqs_enabled); #endif retval = -EAGAIN; if (atomic_read(&p->real_cred->user->processes) >= task_rlimit(p, RLIMIT_NPROC)) { if (p->real_cred->user != INIT_USER && !capable(CAP_SYS_RESOURCE) && !capable(CAP_SYS_ADMIN)) { printk("%s, processes=%d, RLIMIT_NPROC=%lu\n", __func__, atomic_read(&p->real_cred->user->processes), task_rlimit(p, RLIMIT_NPROC)); goto bad_fork_free; } } current->flags &= ~PF_NPROC_EXCEEDED; retval = copy_creds(p, clone_flags); if (retval < 0) goto bad_fork_free; retval = -EAGAIN; if (nr_threads >= max_threads) { printk("%s, nr_threads=%d, max_threads=%d\n", __func__, nr_threads, max_threads); goto bad_fork_cleanup_count; } ... recalc_sigpending(); if (signal_pending(current)) { retval = -ERESTARTNOINTR; goto bad_fork_cancel_cgroup; } if (unlikely(!(ns_of_pid(pid)->nr_hashed & PIDNS_HASH_ADDING))) { retval = -ENOMEM; goto bad_fork_cancel_cgroup; } ... return p; ... fork_out: if(retval < 0) printk("%s comm=%s pid=%d", __func__, current->comm, current->pid); return ERR_PTR(retval); }
可以看出只要是fork()异常,都能抓到相关异常点。
经过运行,在应用抓到了Resource temporarily unavailable,但是内核并没有抓到相关log。
3.2 线程创建std::thread()->pthread_create():线程栈的申请
pthread_create()函数在libpthread.so中,在glibc/nptl/pthread_create.c中定义了pthread_create()函数。
versioned_symbol (libpthread, __pthread_create_2_1, pthread_create, GLIBC_2_1); int __pthread_create_2_1 (pthread_t *newthread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg) { STACK_VARIABLES; const struct pthread_attr *iattr = (struct pthread_attr *) attr; struct pthread_attr default_attr; bool free_cpuset = false; bool c11 = (attr == ATTR_C11_THREAD); if (iattr == NULL || c11)--------------------------------------------------c11没有设置attr,有一套默认attr。 { ... } struct pthread *pd = NULL; int err = ALLOCATE_STACK (iattr, &pd);--------------------------------------为每个线程分配栈,栈的大小由系统rlimit设置;默认大小为8MB。 int retval = 0; if (__glibc_unlikely (err != 0)) { printf("%s(%d): ALLOCATE_STACK failed err=%x.\n", __func__, __LINE__, err);------这个内存分配失败可能性很大,一次8MB。实际返回值为c,也即是ENOMEM。 retval = err == ENOMEM ? EAGAIN : err; goto out; } ... pd->start_routine = start_routine; pd->arg = arg; pd->c11 = c11; /* Copy the thread attribute flags. */ struct pthread *self = THREAD_SELF; pd->flags = ((iattr->flags & ~(ATTR_FLAG_SCHED_SET | ATTR_FLAG_POLICY_SET)) | (self->flags & (ATTR_FLAG_SCHED_SET | ATTR_FLAG_POLICY_SET))); pd->joinid = iattr->flags & ATTR_FLAG_DETACHSTATE ? pd : NULL; pd->eventbuf = self->eventbuf; pd->schedpolicy = self->schedpolicy; pd->schedparam = self->schedparam; ... bool stopped_start = false; bool thread_ran = false; /* Start the thread. */ if (__glibc_unlikely (report_thread_creation (pd)))----------------------------------------------启动线程,调用内核的clone()系统调用创建线程。 { stopped_start = true; retval = create_thread (pd, iattr, &stopped_start, STACK_VARIABLES_ARGS, &thread_ran); if (retval == 0) { assert (stopped_start); assert (pd->stopped_start); pd->eventbuf.eventnum = TD_CREATE; pd->eventbuf.eventdata = pd; do pd->nextevent = __nptl_last_event; while (atomic_compare_and_exchange_bool_acq (&__nptl_last_event, pd, pd->nextevent) != 0); __nptl_create_event (); } } else retval = create_thread (pd, iattr, &stopped_start, STACK_VARIABLES_ARGS, &thread_ran); if (__glibc_unlikely (retval != 0)) { if (thread_ran) assert (stopped_start); else { atomic_decrement (&__nptl_nthreads); if (__glibc_unlikely (atomic_exchange_acq (&pd->setxid_futex, 0) == -2)) futex_wake (&pd->setxid_futex, 1, FUTEX_PRIVATE); /* Free the resources. */ __deallocate_stack (pd); } /* We have to translate error codes. */ printf("%s(%d): create_thread() failed retval=%x.\n", __func__, __LINE__, retval); if (retval == ENOMEM) retval = EAGAIN; } else { if (stopped_start) lll_unlock (pd->lock, LLL_PRIVATE); THREAD_SETMEM (THREAD_SELF, header.multiple_threads, 1); } out: if (__glibc_unlikely (free_cpuset)) free (default_attr.cpuset); return retval; } # define ALLOCATE_STACK(attr, pd) \ allocate_stack (attr, pd, &stackaddr, &stacksize) static int allocate_stack (const struct pthread_attr *attr, struct pthread **pdp, ALLOCATE_STACK_PARMS) { struct pthread *pd; size_t size; size_t pagesize_m1 = __getpagesize () - 1; assert (powerof2 (pagesize_m1 + 1)); assert (TCB_ALIGNMENT >= STACK_ALIGN); /* Get the stack size from the attribute if it is set. Otherwise we use the default we determined at start time. */ if (attr->stacksize != 0) size = attr->stacksize; else { lll_lock (__default_pthread_attr_lock, LLL_PRIVATE); size = __default_pthread_attr.stacksize; lll_unlock (__default_pthread_attr_lock, LLL_PRIVATE); } /* Get memory for the stack. */ if (__glibc_unlikely (attr->flags & ATTR_FLAG_STACKADDR))----------------------------------在flags中包含ATTR_FLAG_STACKADDR,从当前进程的stack中获取内存。一般不定义。 { ... } else {----------------------------------------------------------------------------------------使用mmap()分配匿名内存。 /* Allocate some anonymous memory. If possible use the cache. */ size_t guardsize; size_t reqsize; void *mem; const int prot = (PROT_READ | PROT_WRITE | ((GL(dl_stack_flags) & PF_X) ? PROT_EXEC : 0)); /* Adjust the stack size for alignment. */ size &= ~__static_tls_align_m1; assert (size != 0); guardsize = (attr->guardsize + pagesize_m1) & ~pagesize_m1; if (guardsize < attr->guardsize || size + guardsize < guardsize) /* Arithmetic overflow. */ return EINVAL; size += guardsize;--------------------------------------------------------------------mmap()大小包括了stack+guard两个区域,所以是0x00801000。 if (__builtin_expect (size < ((guardsize + __static_tls_size + MINIMAL_REST_STACK + pagesize_m1) & ~pagesize_m1), 0)) /* The stack is too small (or the guard too large). */ return EINVAL; /* Try to get a stack from the cache. */ reqsize = size; pd = get_cached_stack (&size, &mem); if (pd == NULL) { #if MULTI_PAGE_ALIASING != 0 if ((size % MULTI_PAGE_ALIASING) == 0) size += pagesize_m1 + 1; #endif mem = __mmap (NULL, size, (guardsize == 0) ? prot : PROT_NONE, MAP_PRIVATE | MAP_ANONYMOUS | MAP_STACK, -1, 0);-----------------------------------使用mmap()系统调用,获取一段size大小的内存。 if (__glibc_unlikely (mem == MAP_FAILED)) { printf("%s(%d):size=0x%08x, guardsize=0x%08x, prot=0x%08x, %s\n", __func__, __LINE__, size, guardsize, prot, strerror(errno));
异常log为:allocate_stack(604):size=0x00801000, guardsize=0x00001000, prot=0x00000003, Cannot allocate memory。这段内存为可读写,但是没有可执行权限。这里申请内存权限为PROT_NONE。 dump_self_maps(); return errno; } assert (mem != NULL); /* Place the thread descriptor at the end of the stack. */ #if TLS_TCB_AT_TP pd = (struct pthread *) ((char *) mem + size) - 1; #elif TLS_DTV_AT_TP pd = (struct pthread *) ((((uintptr_t) mem + size - __static_tls_size) & ~__static_tls_align_m1) - TLS_PRE_TCB_SIZE); #endif if (__glibc_likely (guardsize > 0)) { char *guard = guard_position (mem, size, guardsize, pd, pagesize_m1); if (setup_stack_prot (mem, size, guard, guardsize, prot) != 0)------------------------------使用mprotect()保护guard区域,将stack区域设置为可读写。所以stack为rx-p,guard为---p。 { __munmap (mem, size); printf("%s(%d):%s\n", __func__, __LINE__, strerror(errno)); return errno; } } pd->stackblock = mem;---------------------------------------------------------------------------stack的起始地址。 pd->stackblock_size = size;---------------------------------------------------------------------stack的大小。 pd->guardsize = guardsize;----------------------------------------------------------------------guard大小。 pd->specific[0] = pd->specific_1stblock; pd->header.multiple_threads = 1; #ifndef TLS_MULTIPLE_THREADS_IN_TCB __pthread_multiple_threads = *__libc_multiple_threads_ptr = 1; #endif #ifdef NEED_DL_SYSINFO SETUP_THREAD_SYSINFO (pd); #endif pd->setxid_futex = -1; ... /* Prepare to modify global data. */ lll_lock (stack_cache_lock, LLL_PRIVATE); /* And add to the list of stacks in use. */ stack_list_add (&pd->list, &stack_used); lll_unlock (stack_cache_lock, LLL_PRIVATE); if (__builtin_expect ((GL(dl_stack_flags) & PF_X) != 0 && (prot & PROT_EXEC) == 0, 0)) { int err = change_stack_perm (pd #ifdef NEED_SEPARATE_REGISTER_STACK , ~pagesize_m1 #endif ); if (err != 0) { /* Free the stack memory we just allocated. */ (void) __munmap (mem, size); printf("%s(%d):%s\n", __func__, __LINE__, strerror(errno)); return err; } } } ... pd->reported_guardsize = guardsize; } /* Initialize the lock. We have to do this unconditionally since the stillborn thread could be canceled while the lock is taken. */ pd->lock = LLL_LOCK_INITIALIZER; /* The robust mutex lists also need to be initialized unconditionally because the cleanup for the previous stack owner might have happened in the kernel. */ pd->robust_head.futex_offset = (offsetof (pthread_mutex_t, __data.__lock) - offsetof (pthread_mutex_t, __data.__list.__next)); pd->robust_head.list_op_pending = NULL; #if __PTHREAD_MUTEX_HAVE_PREV pd->robust_prev = &pd->robust_head; #endif pd->robust_head.list = &pd->robust_head; /* We place the thread descriptor at the end of the stack. */ *pdp = pd; ... return 0; }
可以看出pthread_create()通过mmap()从内核中申请了stack+guard内存,然后将stackaddr和stacksize作为参数给内核。
内核创建的线程栈使用用户空间分配内存。
实际测试发现确实是在allocate_stack()是返回了ENOMEM,然后ENOMEM被转换成了EAGAIN。
所以std::thread()收到的是EAGAIN错误。
3.3 线程栈申请失败根源
通过top和/proc/meminfo发觉内存都还有余量,但是恰恰此时出现ENOMEM。所以就从maps入手。
3.3.1 抓取线程栈申请失败现场的maps
在allocate_stack()失败之后,调用如下函数抓取当前线程的maps。
#include <sys/prctl.h> #define SELF_MAPS "/proc/self/maps" void dump_self_maps(void) { FILE *self_fd, *output_fd; char buf[1024], output_name[32], process_name[16]; memset(buf, 0x0, sizeof(buf)); memset(output_name, 0x0, sizeof(output_name)); prctl(PR_GET_NAME, process_name); snprintf(output_name, sizeof(output_name), "/tmp/maps_%s_%d.txt", process_name, getpid()); self_fd=fopen(SELF_MAPS,"r"); if(self_fd==NULL) { perror("open file"); exit(0); } output_fd=fopen(output_name,"w"); if(output_fd==NULL) { perror("open file"); exit(0); } while(fgets(buf,sizeof(buf),self_fd)!=NULL) { fputs(buf,output_fd); //printf("%s", buf); } fclose(output_fd); fclose(self_fd); }
maps的详细分析见:《/proc/xxx/maps简要记录》
3.3.2 分析maps为何申请失败
其实在过程中一直通过/proc/meminfo和top查看系统总内存和线程虚拟内存总量,都还有不少余量。
这里就必须要看maps为什么会申请失败?
00008000-0001d000 r-xp 00000000 b3:01 1102 /usr/bin/xchip_runtime 0001e000-00020000 r--p 00015000 b3:01 1102 /usr/bin/xchip_runtime 00020000-00021000 rw-p 00017000 b3:01 1102 /usr/bin/xchip_runtime 00021000-00cdd000 rwxp 00000000 00:00 0 [heap] 2aaa8000-2aac5000 r-xp 00000000 b3:01 957 /lib/ld-2.28.9000.so 2aac5000-2aac6000 r--p 0001c000 b3:01 957 /lib/ld-2.28.9000.so 2aac6000-2aac7000 rw-p 0001d000 b3:01 957 /lib/ld-2.28.9000.so 2aac7000-2aac8000 r-xp 00000000 00:00 0 [vdso] 2aac8000-2aaca000 rw-p 00000000 00:00 0 2aaca000-2ab0a000 r-xp 00000000 b3:01 1104 /usr/lib/libnncv_engine.so 2ab0a000-2ab0b000 ---p 00040000 b3:01 1104 /usr/lib/libnncv_engine.so 2ab0b000-2ab0e000 r--p 00040000 b3:01 1104 /usr/lib/libnncv_engine.so ... 7ea00000-7eaff000 rw-p 00000000 00:00 0 7eaff000-7eb00000 ---p 00000000 00:00 0 7eb00000-7ebff000 rw-p 00000000 00:00 0 7ebff000-7ec00000 ---p 00000000 00:00 0 7ec00000-7ecfa000 rw-p 00000000 00:00 0 7ecfa000-7ed00000 ---p 00000000 00:00 0 7ee00000-7eef6000 rw-p 00000000 00:00 0 7eef6000-7ef00000 ---p 00000000 00:00 0 7ef00000-7ef01000 ---p 00000000 00:00 0 7ef01000-7f701000 rw-p 00000000 00:00 0 7f800000-7f900000 rw-p 00000000 00:00 0 7fe58000-7fe79000 rwxp 00000000 00:00 0 [stack]
通过如下脚本对maps进行分析,可读性更强。
import re import pandas as pd maps_list=[] maps_file = open('./maps_aie_thd_165.txt', 'rb') maps_columns = ["start", "end", "size(KB)", "filename"] maps_process_end='80000000' pre_end=0 for line in maps_file: #00008000-0000b000 r-xp 00000000 b3:01 1023 /root/pidmax #0000b000-0000c000 r--p 00002000 b3:01 1023 /root/pidmax #0000c000-0000d000 rw-p 00003000 b3:01 1023 /root/pidmax maps_line_fmt = '(?P<start>.{8})-(?P<end>.{8}) (?P<permission>.{4}) (?P<size>.{8}) (?P<major>.{2}):(?P<minor>.{2}) (?P<handle>[0-9]*) *(?P<filename>.*)' m = re.match(maps_line_fmt, line) if(not m): continue start = m.group('start') end = m.group('end') permission = m.group('permission') #size = m.group('size') #major = m.group('major') #minor = m.group('minor') #handle = m.group('handle') filename = m.group('filename') start_int = int(start, 16) end_int = int(end, 16) if(pre_end != start_int): maps_list.append([ "{:0>8x}".format(pre_end), start, (start_int - pre_end)/1024, "NOT USED"]) #print start+','+end+','+size+','+permission+','+filename maps_list.append([start, end, (end_int - start_int)/1024, filename]) pre_end = end_int maps_file.close() maps_list.append([end, maps_process_end, (int(maps_process_end, 16) - end_int)/1024, "NOT USED"]) maps_pd = pd.DataFrame(columns=maps_columns, data=maps_list) maps_pd.to_csv("maps.csv", encoding='gb2312') print 'Total memory =', maps_pd['size(KB)'].sum()/1024,'(MB)'
解析结果如下:
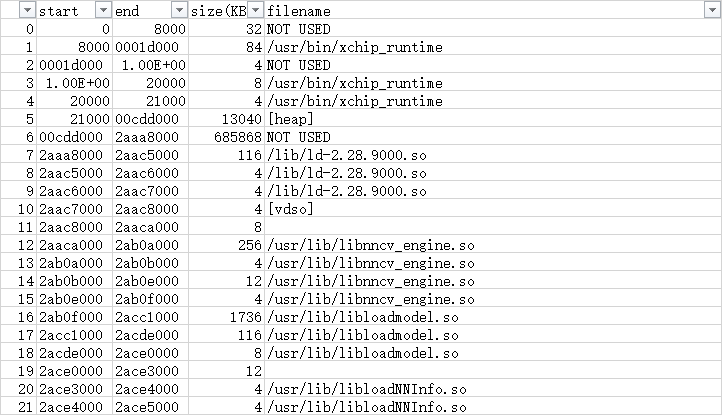
实际虚拟地址使用1340MB左右,按照2GB大小,还剩余600+MB。
可以看出有一块内存区域未使用。

经研究这块内存在heap和库文件之间,这应该是预留给heap的区域。
这块区域可以缩小,然后在进行测试。
4. 解决问题(增大mmap区域)
要增大mmap区域,首先需要了解内核中mmap区域是如何分配的。
#define TASK_SIZE 0x7fff8000UL#define TASK_UNMAPPED_BASE (TASK_SIZE / 3)
经研究发现TASK_UNMAPPED_BASE为TASK_SIZE/3,即0x2AAA8000。
所以mmap是从0x2AAA8000开始申请,这也是heap之后和ld.so之间有这么大未使用空间的原因。
在创建新进程的时候,setup_new_exec()设置了mmap区域。
void setup_new_exec(struct linux_binprm * bprm) { arch_pick_mmap_layout(current->mm); /* This is the point of no return */ current->sas_ss_sp = current->sas_ss_size = 0; ... } void arch_pick_mmap_layout(struct mm_struct *mm) { mm->mmap_base = TASK_UNMAPPED_BASE; mm->get_unmapped_area = arch_get_unmapped_area; } unsigned long arch_get_unmapped_area(struct file *filp, unsigned long addr, unsigned long len, unsigned long pgoff, unsigned long flags) { struct mm_struct *mm = current->mm; struct vm_area_struct *vma, *prev; struct vm_unmapped_area_info info; if (len > TASK_SIZE - mmap_min_addr) return -ENOMEM; if (flags & MAP_FIXED) return addr; if (addr) { addr = PAGE_ALIGN(addr); vma = find_vma_prev(mm, addr, &prev); if (TASK_SIZE - len >= addr && addr >= mmap_min_addr && (!vma || addr + len <= vm_start_gap(vma)) && (!prev || addr >= vm_end_gap(prev))) return addr; } info.flags = 0; info.length = len; info.low_limit = mm->mmap_base;--------------------------mmap区域的范围[mm->mmap_base, TASK_SIZE]。 info.high_limit = TASK_SIZE; info.align_mask = 0; return vm_unmapped_area(&info); } unsigned long get_unmapped_area(struct file *file, unsigned long addr, unsigned long len, unsigned long pgoff, unsigned long flags) { unsigned long (*get_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long); unsigned long error = arch_mmap_check(addr, len, flags); if (error) return error; /* Careful about overflows.. */ if (len > TASK_SIZE) return -ENOMEM; get_area = current->mm->get_unmapped_area; if (file) { if (file->f_op->get_unmapped_area) get_area = file->f_op->get_unmapped_area; } else if (flags & MAP_SHARED) { pgoff = 0; get_area = shmem_get_unmapped_area; } addr = get_area(file, addr, len, pgoff, flags); if (IS_ERR_VALUE(addr)) return addr; if (addr > TASK_SIZE - len) return -ENOMEM; if (offset_in_page(addr)) return -EINVAL; error = security_mmap_addr(addr); return error ? error : addr; }
进程线程在创建的时候都规定了mmap的区域,并且在mmap的时候同样进行了规定。
所以只需要修改TASK_UNMAPPED_BASE即可。
#define TASK_UNMAPPED_BASE 0x10000000// Change from 0x2aaa8000(TASK_SIZE / 3) to 0x10000000.
重新运行内存之后,发现mmap区域变大了许多。线程创建成功,问题解决。
4.1 修改pthread stacksize减少栈空间
pthread_create()可以修改,但是std::thread()创建的线程没有修改stacksize的接口。
所以使用std::thread()创建的线程默认使用ulimit -s大小的线程。这个线程栈大小是系统规定的,可以通过ulimit -x <size>来修改。
使用pthread_attr_setstacksize()来修改线程栈大小:
void* foo(void* arg); . . . . pthread_attr_t attribute; pthread_t thread; pthread_attr_init(&attribute); pthread_attr_setstacksize(&attribute,1024);----------------设置线程栈的大小。 pthread_create(&thread,&attribute,foo,0); pthread_join(thread,0);
对于C++来说,可以使用boost::thread::attributes来设置所创建的线程栈的大小。
boost::thread::attributes attrs; attrs.set_size(4096*10); boost::thread myThread(attrs, fooFunction, 42);
参考文档:《c++ - pthread - thread stack size limit》、《How to set the stacksize with C++11 std::thread》


 浙公网安备 33010602011771号
浙公网安备 33010602011771号