【机器学习】模型选择与评估中的常用指标
机器学习中的评估指标
0 概述
使用机器学习方法为任务进行建模已变得很常见,主要应用在分类和回归两大任务体系中。
本节针对分类和回归任务,依次梳理出两个类任务中常见的模型性能评估指标
1 分类任务中的评估指标
1.1 混淆矩阵
混淆矩阵的列代表模型预测的标签,行表示样本实际的标签。二分类时候,如果将正预测记作P,负预测记作N,分别对应于样本的实际标签予以逻辑判断正确T和错误F,可以生成TP,FP,TN,FN四个标签,如下表所示,混淆矩阵有助于研究者观察模型预测各类别的能力,并据此分析潜在的可能原因和模型性能提升方法。
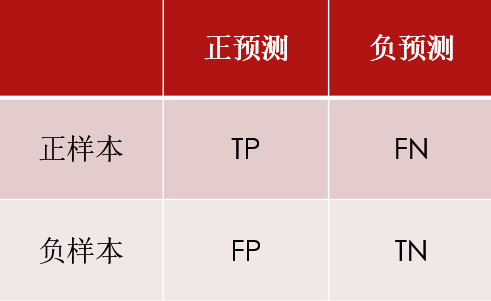
TP: 预测为正,实际样本为正。
FP:预测为正,实际样本为负。
TN: 预测为负,实际样本为负。
FN: 预测为负,实际样本为正。
1.2 准确率
准确率是指模型分类正确的样本数量占总样本数量的比例。
分类正确的样本数:$ TP + TF $
总样本数:$ TP + FP + TN + FN $
准确率:$ ACC = \frac {TP + TF}{TP + FP + TN +FN} $
1.3 精确率
精确率是指模型预测为正,实际样本为正(TP)与所有模型预测为正的样本数量的比值。
精确率:$ P = \frac {TP}{TP + FP}$
1.4 召回率
召回率是指模型预测为正,实际样本为正(TP)与所有实际样本为正(TP + FN)数量的比值。
召回率:$ R = \frac {TP}{TP + FN}$
1.5 综合评价指标F值
F值是P值和R的综合,当P值和R值出现矛盾情况的时候,就需要使用F值来评价模型的性能。
$ F = \frac {(\alpha^2 + 1) P * R }{\alpha^2(P + R)} $
当$ \alpha = 1$时,为常用的F1值:
$F1 = \frac {2 P * R }{P + R} $
1.6 ROC曲线
ROC曲线的纵轴是TPR真正率,横轴是FPR假正率。
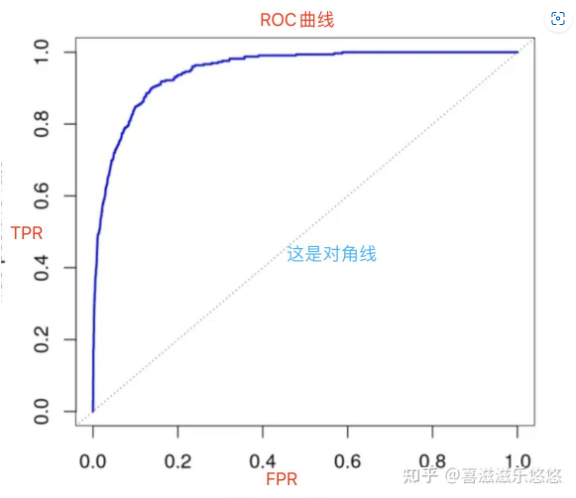
ROC曲线下方的面积计算出的值称作AUC,它处于0.5-1之间,AUC越大,表示模型分类效果越好。
1.7 PR曲线
PR曲线的横坐标是精确率P,纵坐标是召回率R。评价标准和ROC一样,先看平滑不平滑(越平滑越好)。
一般来说,在同一测试集,上面的比下面的好(绿线比红线好)。
当P和R的值接近时,F1值最大,此时画连接(0,0)和(1,1)的线,线和PRC重合的地方的F1是这条线最大的F1(光滑的情况下),此时的F1对于PRC就好像AUC对于ROC一样。
一个数字比一条线更方便调型。
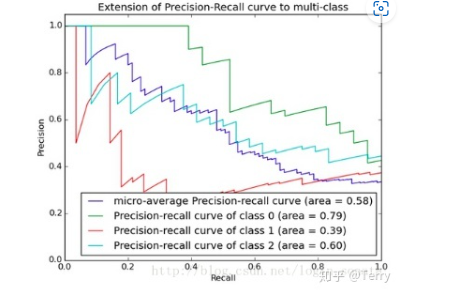
PR曲线下的面积称为AP(Average Precision),表示召回率从0-1的平均精度值。AP可用积分进行计算。
AP面积的不会大于1。PR曲线下的面积越大,模型性能则越好。性能优的模型应是在召回率(R)增长的同时保持精度(P)值都在一个较高的水平,而性能较低的模型往往需要牺牲很多P值才能换来R值的提高。
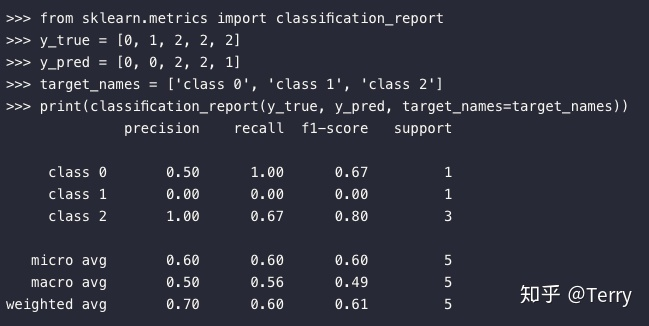
1.8 分类文本报告
classification_report函数用于显示主要分类指标的文本报告.在报告中显示每个类的精确度,召回率,F1值等信息。
2 回归(待更新)
Reference:https://zhuanlan.zhihu.com/p/86120987

 浙公网安备 33010602011771号
浙公网安备 33010602011771号